/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Сегодня я расскажу, как с помощью библиотеки ML Tuning осуществить подбор гиперпараметров модели GBTRegressor в PySpark.
Гиперпараметры в машинном обучении используются для управления процессом обучения модели, поэтому подбор оптимальных гиперпараметров – очень важный этап в построении ML-моделей, позволяющий повысить точность, а также бороться с переобучением. Привычный тюнинг параметров в Python для моделей машинного обучения представляет собой множество техник и способов, например, GridSearch, RandomSearch, HyperOpt, Optuna. Но бывают случаи, когда предобработка данных для модели занимает слишком много времени, или объем данных слишком велик, чтобы вместиться в оперативную память одной машины. Для этого на помощь приходит Spark.
Рассматривать чистку данных и feature engineering не буду и предположим, что данный процесс уже реализован.
Здесь я рассмотрю, как в Spark работать с моделями машинного обучения на примере GBTRegressor, а главное, как подбирать гиперпараметры. Делать я это буду на всем известном датасете Boston. Датасет содержит информацию об объектах недвижимости в Бостоне. Его можно скачать из библиотеки sklearn. Объем датасета: (506 X 14).
GBTRegressor – модель градиентного бустинга для задачи регрессии.
Начну с импорта необходимых библиотек:
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import GBTRegressor
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
Загружу датасет из sklearn и запишу его в Spark DataFrame:
from sklearn.datasets import load_boston
import pandas as pd
boston = load_boston()
boston_df = pd.DataFrame(boston.data, columns = boston.feature_names)
boston_df['TARGET'] = boston.target
boston_df = spark.createDataFrame(boston_df)
Посмотрю на данные:
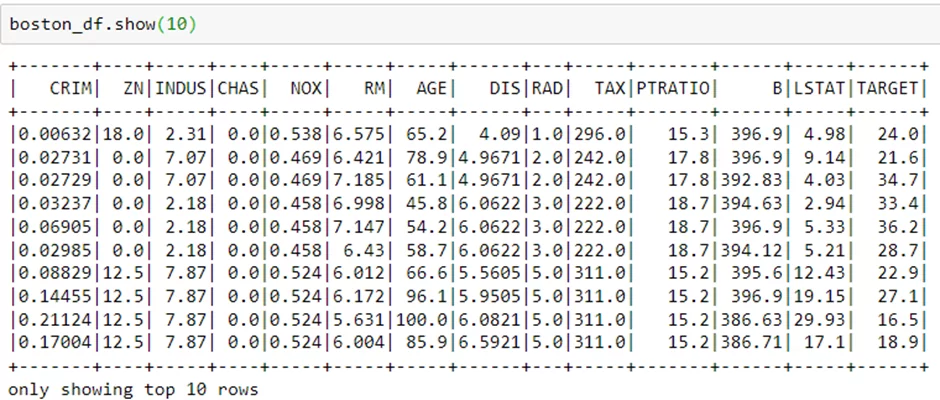
Разделю данные на train и test:
train, test = boston_df.randomSplit([0.8, 0.2], seed = 12345)Преобразую признаки в единый вектор и преобразую датафрейм:
vec = VectorAssembler(inputCols=['CRIM', "ZN", "INDUS", "CHAS",
"NOX", "RM", "AGE", "DIS",
"RAD", "TAX","PTRATIO", "B", "LSTAT"],
outputCol='FEATURES')
vector_feature_train = vec.transform(train)
vector_feature_test = vec.transform(test)
Инициализирую модель GBTRegressor явно указав, какая колонка будет отвечать за признаки, а какую колонку будем предсказывать:
gbt = GBTRegressor(featuresCol='FEATURES', labelCol='TARGET')Объявлю Evaluator для оценки модели, в качестве метрики выбрав MAE (По умолчанию стоит RMSE):
evaluator = RegressionEvaluator(predictionCol='prediction',
labelCol='TARGET',
metricName = 'mae')
Прежде чем приступать к подбору гиперпараметров, посмотрим на точность модели с дефолтными настройками:
gbt_model = gbt.fit(vector_feature_train)
pred = gbt_model.transform(vector_feature_test)
mae = evaluator. evaluate(pred)
print(mae)
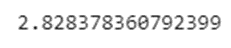
Запомним значение данной метрики, чтобы проверить, улучшится ли ее значение на тестовой выборке после подбора гиперпараметров.
Объявлю сетку параметров, которые требуется подобрать, где MaxDepth – это максимальная глубина дерева, в MaxIter – количество деревьев:
paramGrid = ParamGridBuilder() \
.addGrid(gbt.maxIter, [10, 20, 30])\
.addGrid(gbt.maxDepth, [3, 4, 5])\
.build()
В GBTRegressor есть и другие параметры, например, featureSubsetStrategy – стратегия подбора подмножества признаков, но здесь я рассматриваю сам механизм подбора параметров. С самими параметрами можно ознакомиться в официальной документации алгоритма GBTRegressor для Spark.
Значения параметров для подбора можно расширить, скажем, рассмотреть количество итераций не строго 10 или 30, а указать диапазон: [10, 11, 12…30], тем самым, возможно, повысив точность итоговой модели. Но чем больше количество значений перебираемых параметров, тем дольше времени займет процесс самого перебора, особенно на большом объеме данных, поэтому с количеством параметров и значениями для этих параметров нужно быть осторожным.
Объявлю CrossValidator, в котором укажу алгоритм, сетку параметров, способ оценивания алгоритма и количество фолдов:
crossval = CrossValidator(estimator=gbt,
estimatorParamMaps=paramGrid,
evaluator=evaluator,
numFolds=3)
Запущу кросс-валидацию и выведем среднюю метрику на каждую комбинацию параметров:
cvModel = crossval.fit(vector_feature_train)
cvModel.avgMetrics

Также очень важно посмотреть, при каких параметрах модели была получена лучшая метрика:
cvModel.bestModel.extractParamMap()
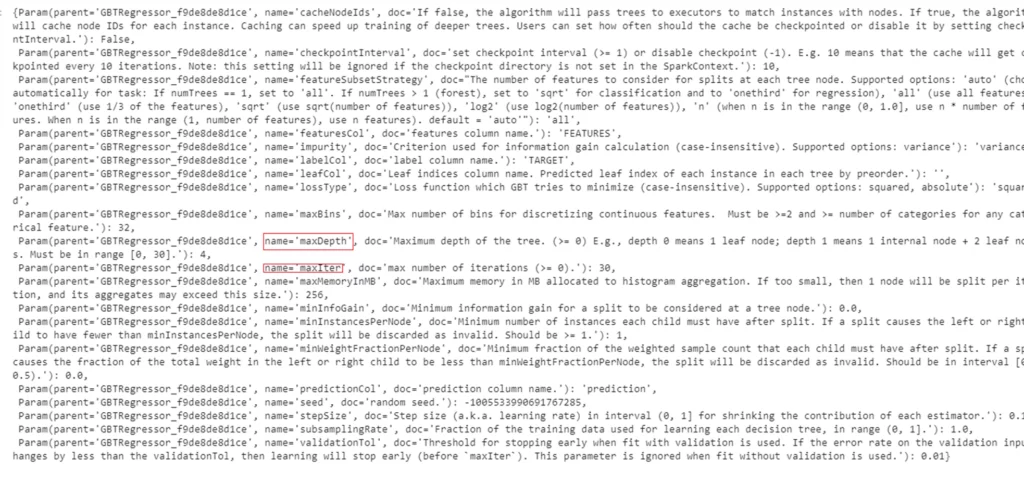
Отсюда можно увидеть, что MaxDepth = 4, а MaxIter = 30.
После получения лучших гиперпараметров, можно обучить с ними модель, сохранить ее и использовать в дальнейших предсказаниях, не затрачивая время на переобучение модели каждый раз, когда требуется predict.
Теперь проверим точность при полученных гиперпараметрах на тестовой выборке:
gbt = GBTRegressor(featuresCol='FEATURES', labelCol='TARGET', maxDepth=4, maxIter=30)
gbt_model = gbt.fit(vector_feature_train)
pred = gbt_model.transform(vector_feature_test)
mae = evaluator. evaluate(pred)
print(mae)
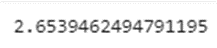
Получилось улучшить метрику!
Естественно, это не лучший результат. Можно расширить возможные значения параметров, а также количество самих параметров, чтобы добиться максимально возможной точности. Я напоминаю, что процесс feature engineering был мною пропущен, но он также может сильно помочь в получении максимально возможного качества при построении модели. Главное, что я хотел показать — это механизм подбора параметров в Spark ML, остальное — дело техники.
И не забудьте остановить spark сессию 🙂