/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Все мы привыкли к python как к основному инструменту для машинного обучения, но иногда данных становится очень много и обычный рабочий компьютер уже не способен выполнять наши задачи. На помощь приходит PySpark. Он представляет из себя API для Apache Spark, который способен выполнять распределенную обработку больших данных. Сегодня ознакомимся с базовой частью машинного обучения в PySpark — с загрузкой, с предобработкой данных, обучением моделей, а также некоторыми особенностями данного инструмента.
Для начала импортируем нужные нам библиотеки:
from pyspark.context
import SparkContextfrom pyspark.ml
import Pipelinefrom pyspark.ml.feature
import StringIndexer, VectorIndexer
from pyspark.ml.regression import LinearRegression
from pyspark.sql.session import SparkSession
from pyspark.ml.feature import VectorAssembler
Spark будет работать у нас на локальном компьютере, поэтому прописываем — local:
sc = SparkContext('local')
spark = SparkSession(sc)
Посмотрим на только что созданную Спарк-сессию, выведем немного информации о ней:
sparkДанная статья направлена больше на тестирование незнакомого инструментария, нежели на классическое машинное обучение, поэтому возьмем обучающий датасет с малым количеством строк. Обычно, конечно, работа в Spark направлена на обработку куда больших данных. Пропишем путь до стандартного датасета стоимости домов в Бостоне. Пропишем нужные формат — csv, наличие заголовка (header) и схемы. И загрузим данные в df:
PATH = '../Desktop/boston.csv'
df = spark.read.format('csv').option('header','true').option('inferSchema', 'true').load(PATH)
Любителей pandas ждет небольшое разочарование — head’а тут нет, посмотрим на начало таблицы, используя show():
df.show()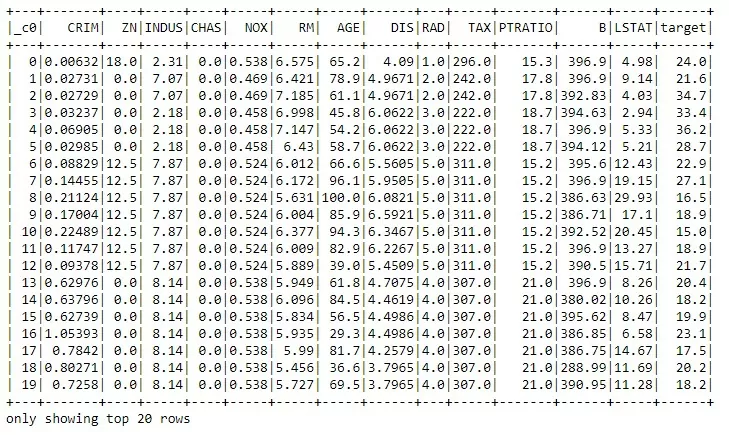
В отличие от head, show по умолчанию показываем на 20 первых строк. Часто для ознакомления с данными мне помогало немного развернуть таблицу, особенно, когда столбцов очень много:
df.show(1, vertical = True)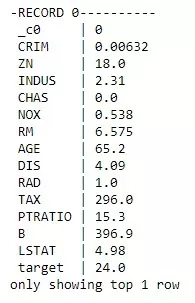
Замечаем, что у нас есть столбец, похожий на обычный индекс, проверим нашу гипотезу с помощью distinct (который знаком людям, знающим SQL) и show:
df.select('_c0').distinct().count() == df.count()
df.select('_c0').show(10)
Для знающих SQL предобработка данных не станет сюрпризом, SQL-подобный синтаксис в Spark’е встречается часто. Оставим только нужные столбцы:
df = df.select('CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'target')Давайте выведем информацию о столбцах:
df.printSchema()

Удостоверимся, что в наших данных только числа и ничего более. nullable = true указывает на то, что null-значения могут присутствовать в столбце, но не означает, что они есть конкретно в наших данных. Посмотрев на данные, немного их предобработав, перейдем к более интересной части, а именно к особенностям обучения моделей в Spark. Создадим свой небольшой пайплайн:
pipeline = []Для начала предобработаем целевую переменную в спарковскую вектор строку, подавая на вход target, на выходе получим target_spark, добавим этот шаг в наш пайплайн:
targets = StringIndexer(inputCol = 'target', outputCol = 'target_spark')
pipeline.append(targets)
Так как наш датасет обучающий, запишем все названия столбцов, за исключением целевого, в численные. Далее предобработаем и наши признаки — аналогично таргету, на выходе опять получим спарковскую вектор-строку:
num_cols = df.columns[:-1]
v_assembler = VectorAssembler(inputCols = num_cols, outputCol = 'features')pipeline.append(v_assembler)
Поделим данные в соотношении 80/20:
size = [.8, .2]
(train, test) = df.randomSplit(size)
Так как статья имеет сугубо ознакомительный характер, с алгоритмом мудрить не будем, возьмем обычную линейную регрессию и добавим ее в пайплайн:
lr = LinearRegression(labelCol = 'target_spark', featuresCol = 'features')
pipeline.append(lr)
В stage передаем этапы предобработки и модель, которую мы выбрали:
pipeline_spark = Pipeline(stages = pipeline)Давайте воспользуемся нашим пайплайном и обучим модель, после чего предскажем метки на тестовой части данных:
m = pipeline_spark.fit(train)
pred = m.transform(test)
Считать метрики и делать далеко идущие выводы в данном случае не имеет большого смысла, поэтому этот шаг можно пропустить. Немного подытожим: для человека, который работает с данными — постигать спарк будет не так сложно, опыт работы с SQL дает возможность достаточно быстро освоить предобработку данных, а работа в ML-библиотеками в Python — обучение моделей, тюнинг гиперпараметров и тд. Тем не менее, в спарке есть пару особенностей, к которым нужно привыкнуть. И не забудьте остановить спарк-сессию, удачи 🙂
sc.stop()