/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Синтаксис Spark не схож с Pandas, поэтому пользователю тяжело переключится с одного на другое. Для примера, с помощью Pandas и PySpark создадим из csv-файла DataFrame, в который добавим новую колонку ‘x2’ со значениями из колонки x во второй степени.
Pandas:
Import pandas as pd
Df= pd.read_csv(“data.csv”)
Df.columns=[‘x’, ‘y’, ‘z’]
Df[‘x2’]=df.x*df.x
PySpark:
Df=(spark.read
.option(“inferSchema”, “true”)
.csv(“data.csv”))
Df=df.toDF(‘x’, ‘y’, ‘z’)
Df=df.withColumn(‘x2’, df.x*df.x)
Синтаксис PySpark интуитивно менее понятен, чем Pandas, в связи с чем у аналитика данных возникают сложности в использовании инструментов PySpark. Овладение ими занимает определенное время, что в условиях сжатых сроков выполнения задач, может быть критично.
На помощь приходит библиотека Koalas, которая для версий Spark 3.1 и ниже является отдельной, но начиная с 3.2 уже включена в PySpark из коробки.
В данной статье постараюсь ответить на вопрос: а так ли мягки коалы на ощупь, как и панды?
Для начала импортируем необходимые библиотеки:
import pandas as pd
import numpy as np
import databricks.koalas as ks
from pyspark.sql import SparkSession
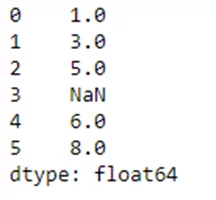
Создадим последовательность из списка значений и разрешим создать стандартный индекс:
s = ks.Series([1, 3, 5, np.nan, 6, 8])Получаем результат:
Теперь создадим словарь объектов, которые могут быть преобразованы в последовательность:
kdf = ks.DataFrame(
{'a': [1, 2, 3, 4, 5, 6],
'b': [100, 200, 300, 400, 500, 600],
'c': ["one", "two", "three", "four", "five", "six"]},
index=[10, 20, 30, 40, 50, 60])
Результат:

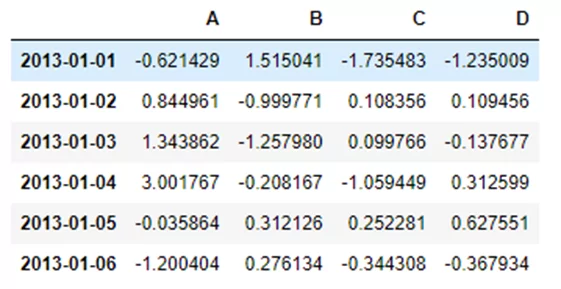
Создадим DataFrame (DF), используя numpy массив с индексами из дат и названными колонками.
dates = pd.date_range('20130101', periods=6)
pdf = pd.DataFrame(np.random.randn(6, 4),
index=dates,
columns=list('ABCD'))
В результате получим таблицу такого вида:
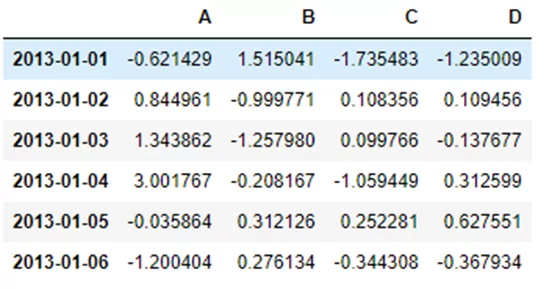
Следующим шагом конвертируем Pandas DF в Koalas DF.
kdf = ks.from_pandas(pdf)И получаем идентичный результат:
Также возможно преобразование Spark DF в Koalas DF, что и разберем ниже.
Создадим Spark DF из Pandas DF:
spark = SparkSession.builder.getOrCreate()
sdf = spark.createDataFrame(pdf)
sdf.show()
Результат:

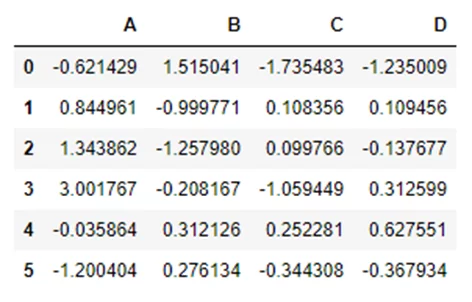
А теперь создадим Koalas DF:
kdf = sdf.to_koalas()Результат аналогичный предыдущему:
Как создавать DF мы поняли. Теперь разберемся как данные просматривать. Рассмотрим основные команды и как они работают.
kdf.head()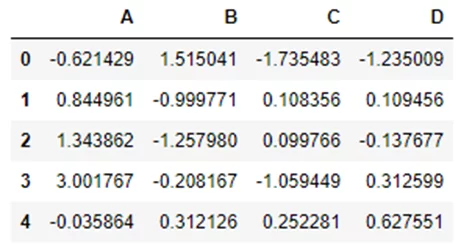
kdf.index
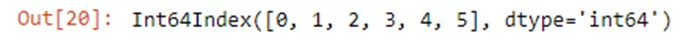
kdf.columns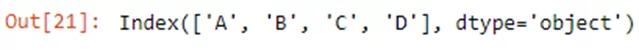
kdf.to_numpy()
Describe показывает краткую статистику данных:
kdf.describe()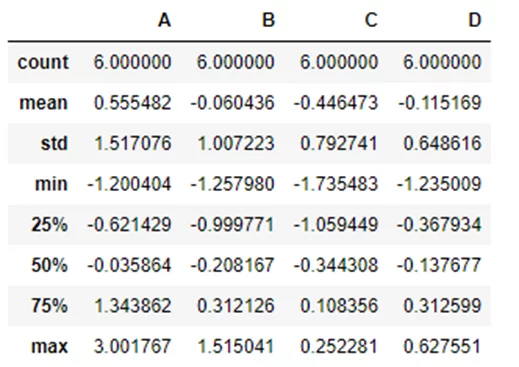
Сортировка:
kdf.sort_values(by='B')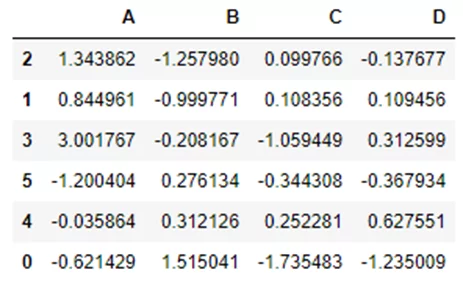
Любой человек, знакомый с Pandas, может сказать: «И что тут сложного? Обычные примеры использования библиотеки, похожей на Pandas». Но я напомню, что все эти действия происходят на Spark, что решает проблему масштабируемости обработки данных и обеспечивает “мягкий вход” аналитиков в Spark.