/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Работа с библиотекой pandas для каждого аналитика данных, а тем более ML-инженера – дело совершенно тривиальное. Казалось бы, каждый читал и обрабатывал уже тысячи различных таблиц, находил метрики, строил по ним аналитику и все используя стандартные методы, имеющиеся в библиотеке. Что можно узнать нового?
На простом примере разберу несколько методов pandas, которые, к слову, известны почти всем уверенным аналитикам, и сравним их скорость работы. Кроме того, разберу причины большой разницы в скорости. Зная, как работают методы pandas, работа с ними может открыться с другой стороны.
Очевидно, что если вы обрабатываете небольшое количество строк, то совершенно не обязательно, чтобы ваш код отличался особой элегантностью или необычной техникой кодинга. Но если обрабатывать большие данные, то появляется проблема производительности и скорости обработки.
Для начала создается тестовый датафрейм с 1000000
df = pd.DataFrame(np.random.rand(1000000,2), columns=('a','b'))
df.describe()
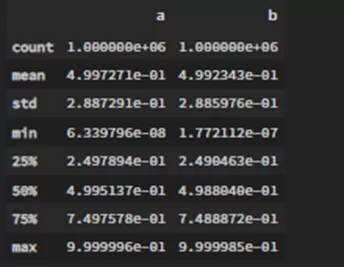
Все создалось верно и как ожидалось.
Создам новую метрику, представляющую собой сумму a и b. Сделаю это, конечно, разными способами, начиная с
- .iterrows()
Данный метод проходится по всем строкам датафрейма в виде пар (index, Series), т.е. конвертирует каждую строку в Series object, из-за чего сильно страдает время работы. Кроме того, есть вероятность автоматической смены типа данных.
По скорости работы — это худший возможный метод
%%timeit -n 3
fin=[]
for i,row in df.iterrows():
fin.append(row['a']+row['b'])


- .loc[] или .iloc[]
Теперь протестирую всем знакомые .loc и .iloc. Хоть и сами методы работают отлично, но они совершенно не предназначены для использования в цикле for. Суть работы приблизительно такая же, как и в прошлом методе. Однако, .iloc работает чуть быстрее чем .loc, т.к. метод обращается напрямую к месту, где строка хранится в памяти.
%%timeit -n 3
fin=[]
for i in range(len(df)):
fin.append(df['a'].loc[i]+df['b'].loc[i])

В 2 раза быстрее относительно .iterrows()
%%timeit -n 3
fin=[]
for i in range(len(df)):
fin.append(df['a'].iloc[i]+df['b'].iloc[i])

Почти в 3 раза быстрее относительно .iterrows()
- .apply()
Всем известный метод и, к тому же, с ним легко работать. Но, к сожалению, результат почти так же плох, как и в предыдущих методах. Больше я не использую .apply() в подобных целях, но все еще вспоминаю о нем при других, более сложных задачах.
%%timeit -n 3
df.apply(lambda row: row['a']+row['b'], axis=1).to_list()

Еще в 2 раза быстрее относительно предыдущего метода
- .itertuples()
Метод по сути крайне похож на .iterrows() (даже названием), но с отличием, позволяющим работать быстрее – вместо конвертирования строк в Series object, он переводит их в кортежи, которые намного легче. Однако в коде теперь нужно обращаться к колонкам по их номеру, а не с помощью имени.
%%timeit
fin=[]
for row in df.itertuples():
fin.append(row[1]+row[2])

Сократили время работы еще примерно 12 раз!
- list comprehension
Прекрасный метод выполнить задачу всего в 1 строчку. Кроме того, как вы догадались, он работает быстрее предыдущих. К сожалению, данный метод все еще использует цикл for, хоть и скрыто.
%timeit [a+b for a,b in zip(df['a'],df['b'])]
Почти x4, в сравнении с .itertuples()
Когда используется цикл for, python выполняет итерацию по каждому объекту, в данном случае по строке df. Он идентифицирует класс объекта (массив numpy), оценивает, является ли применяемый метод (итерация) приемлемым. Затем он перебирает каждый объект в строке. Как только он находит объект, он идентифицирует тип данных и проверяет связанные методы. Затем он анализирует метод, применяемый к ним, он применяется (или выдает ошибку, если не может), а затем переходит к следующему объекту и начинает все сначала. Для каждого объекта выполняется множество операций, что фактически убивает скорость. Методы, описанные в этой статье, сокращают количество необходимых шагов.
Как избежать всего этого?
- pandas vectorization
До этого момента просто суммировались два значения для каждой строки. Но pandas позволяет сгруппировать значения в вектор и просуммировать уже их. Векторизация работает с фреймом данных, который эффективно хранит типы объектов и пропускает или ускоряет весь поиск метаданных объекта и проверку ошибок. Решение от pandas интуитивно и выполняет векторизацию за нас. И, конечно же, такой метод работает быстрее.
%timeit (df['a'] + df['b']).to_list()
Ускорили работу еще в 10 раз! Можно ли придумать что-то быстрее? На самую малость
- numpy vectorization
Если вы работаете с массивами одного типа, использование массива numpy позволяет еще более эффективно извлекать метаданные, поскольку массивы numpy должны быть одного типа данных. Вот и получается дополнительное увеличение скорости.
%timeit (df['a'].values + df['b'].values).tolist()

Теперь подытожу и составлю топ худших решений, по сравнению с самым быстрым — numpyvectorization
pandas vectorization = 1.09 * numpy vectorization
list comprehension= 10.5 * numpy vectorization
.itertuples() = 40 * numpy vectorization
.apply() = 480 * numpy vectorization
.iloc[] = 990 * numpy vectorization
.loc[] = 1544 * numpy vectorization
.iterrows() = 3120 * numpy vectorization
Т.е. представьте себе, один специалист, работающий правильно, может заменить 3120 специалистов, которые не знают различных нюансов работы с pandas или, хотя бы, не ознакомились с данной статьей 🙂
Конечно все всегда зависит от конкретной задачи, но, по крайней мере, у вас есть пища для размышлений и понимание разнообразных возможностей pandas. Работайте быстрее, а главное проще!