/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
В моём случае необходимо предсказать вероятность сделки у объявления. Для начала импортирую все необходимые библиотеки.
import numpy as np
import torch
import pandas as pd
from tqdm.auto import tqdm
from transformers import BertTokenizer, BertModel
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import Ridge
from catboost import Pool, CatBoostRegressor
from sklearn.model_selection import train_test_splitА также загружаю предобученный BERT. Выбор этой модели обоснован тем, что BERT – одна из лучших моделей для работы с текстом. Отличным примером этого является объявление Google о том, что эта сеть является основной движущей силой их поиска. Компания считает, что этот шаг представляет собой самый большой скачок вперед за последние годы и один из самых больших скачков в истории поиска.
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
bert_model = BertModel.from_pretrained('bert-base-multilingual-cased')Буду использовать модель bert-base-multilingual-cased. Но можно взять любой подходящий вариант на сайте.
Далее ознакомлюсь с данными. Для примера будут взяты только 5000 семплов и некоторые из колонок, как категориальных, так и количественных, а также текстовая – title (наименование объявления).
df = pd.read_csv('train.csv')
df.drop(columns=['item_id', 'user_id', 'item_seq_number',
'param_1', 'param_2', 'param_3', 'image',
'user_type', 'activation_date', 'image_top_1',
'description'], inplace=True)
df = df.iloc[:5000]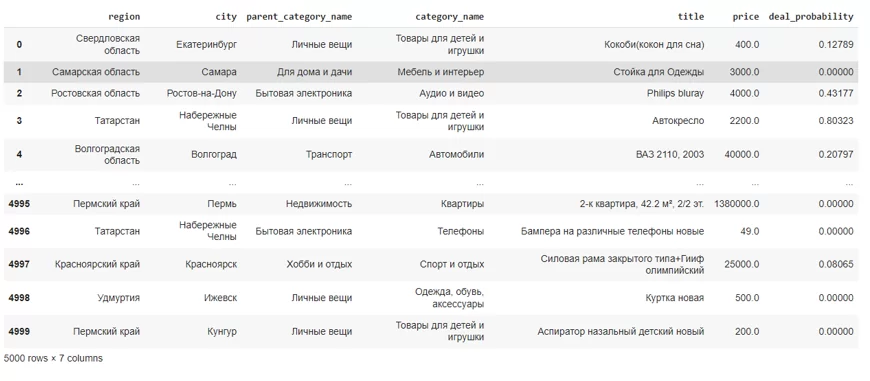
Проведу токенизацию тайтлов, а к получившимся закодированным последовательностям добавлю паддинги и маску. Паддинги – заполнители со значением 0 (нужны для получения размерности 256), а маска – массив, где 0 – элемент с соответствующим индексом является паддингом, 1 – токеном.
tokenized = [tokenizer.encode(x, add_special_tokens=256) for x in tqdm(df['title'])]
padded = np.array([i + [0]*(256-len(i)) for i in tokenized])
attention_mask = np.where(padded != 0, 1, 0)Переведу массивы в тензоры для обработки torch, отправлю эмбеддинги и маску в BERT.
input_ids = torch.tensor(padded)
attention_mask = torch.tensor(attention_mask)
with torch.no_grad():
last_hidden_states = bert_model(input_ids, attention_mask=attention_mask)Извлекаю фичи из результатов сети.
features = last_hidden_states[0][:,0,:].numpy()Далее разбиваю датасет на 5 частей. Частей может быть произвольное количество. Чем их меньше, тем меньше время выполнения и качество предсказания, и наоборот.
spliter = StratifiedKFold(n_splits=5, shuffle=True)
_y = (df.deal_probability.round(2)*100).astype(int)
FOLD_LIST = list(spliter.split(_y, _y))
Y = df.deal_probability.valuesТеперь нужно предсказать каждую часть из 5, обучив Ridge регрессию по остальным 4-м. Полученные предсказания будут являться новой мета-фичей от текста моего датасета.
def rmse(y_true, y_pred):
return (mean_squared_error(y_true, y_pred)**0.5).round(5)
oof_predictions = np.zeros(shape=[df.shape[0]])
for fold_id, (train_idx, val_idx) in enumerate(tqdm(FOLD_LIST)):
text_train, y_train = (
features[train_idx],
Y[train_idx]
)
text_val, y_val = (
features[val_idx],
Y[val_idx]
)
model = Ridge()
model.fit(text_train, y_train)
oof_predictions[val_idx] = model.predict(text_val)
print('###', 'fold', fold_id,':', '###')
print('descr_model rmse:', rmse(oof_predictions[val_idx], y_val))Разбиваю датасет на обучающую и валидационную части. Формирую пулы для обучения CatBoostRegressor. Авторы библиотеки catboost рекомендуют использовать именно пулы при обучении.
df['title_score'] = oof_predictions
df.drop(columns=['title'], inplace=True)
X_train, X_val, y_train, y_val = train_test_split(df.drop(columns=['deal_probability']), df.deal_probability)
cat_features = ['region', 'city', 'parent_category_name', 'category_name']
train_pool = Pool(X_train, y_train, cat_features=cat_features)
val_pool = Pool(X_train, y_train, cat_features=cat_features)Обучаю бустинг. Catboost взят в качестве примера, поэтому оставляю параметры по умолчанию, хотя данная реализация бустинга неплохо себя показывает даже с дефолтными параметрами. Именно градиентный бустинг считается SOTA моделью для табличных данных.
cbr = CatBoostRegressor()
cbr.fit(train_pool, eval_set=val_pool, verbose=100)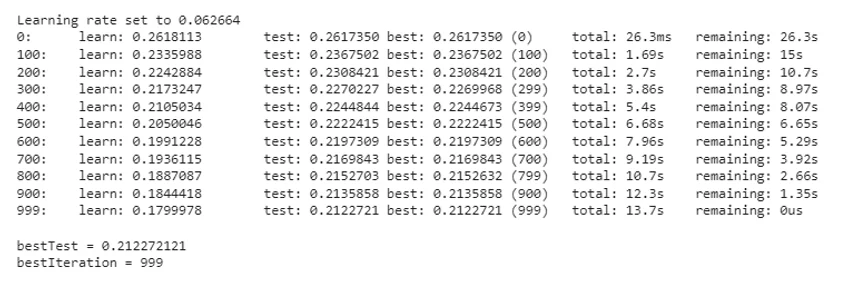
В посте был разобран один из вариантов кодирования текста для табличных данных. Часто подобная работа с текстом позволяет выиграть в качестве модели, но плохо влияет на её интерпретируемость. Многие упомянутые моменты можно изменить, поэкспериментировав под свою задачу, например, вместо Catboost использовать XGBoost или LightGBM, вместо Ridge использовать Lasso и т.д. Также можно попробовать решать задачу регрессии для получения мета-фичей и самим BERT’ом.