/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Сегодня я расскажу, как из аудиозаписи выделить разговор, вычислить его длительность и, если запись позволяет, определить пересечение диалогов с помощью библиотеки Librosa.
Для начала считаю аудиофайл. Если он записан в формате стерео, то для возможности работать с двумя дорожками поставлю параметр mono = False.
file_name = 'Phone.mp3'
y, sr = librosa.load(file_name, mono = False)В переменную y записываются считанные значения амплитуды, в sr — частота дискретизации.
По умолчанию sr равен 22050. Это означает, что файл считывается с частотой дискретизации в 22050 Гц. Следовательно, в y 22050 значений амплитуды в секунду.
В переменной y — двумерный массив, значит здесь две дорожки с 354750 значениями.
y.shape
(2, 354750)
Подсчитаю общую длительность аудиозаписи, разделив общую длинную амплитуд на частоту дискретизации:
y.shape[1] / sr
16.08843537414966
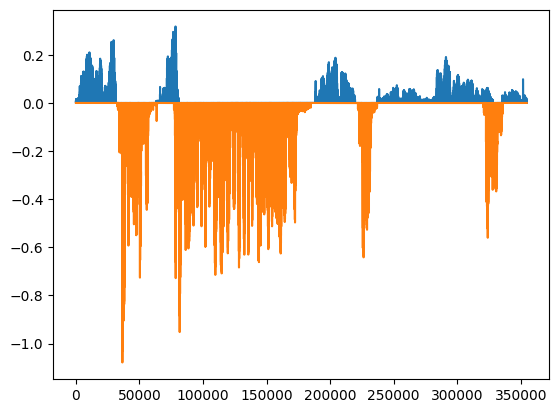
Ниже на графике представлена визуализация двух дорожек аудиозаписи: синим цветом отображается речь одного собеседника, оранжевым — другого.
sns.lineplot(abs(y[0]))
sns.lineplot(abs(y[1])*-1)
На графике ниже представлена амплитуда первых 200 точек одной из дорожек аудиозаписи. Можно заметить, что большинство из них отличны от нуля. И, казалось бы, это значит, что все время есть звук, а значит, есть и разговор. Но это не так. В записях часто встречаются посторонние, незначительные шумы, которые тоже вносят свой вклад (как на графике ниже).
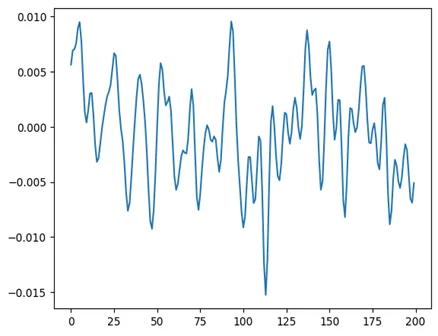
Поэтому для определения границ разговора необходимо задать минимальный порог амплитуды звука. Если она выше границы, ставлю метку 1 и считаю, что разговор осуществляется, если ниже — ставлю 0 и считаю, что в аудиозаписи никто не говорит.
Далее выбираю из исходных данных только значения, подходящие под условие:
limit = 0.04
y0 = np.select([abs(y[0])>limit ],[1])
y1 = np.select([abs(y[1])>limit ],[-1])
Для удобства работы создаю таблицу. В ней будут находиться исходные значения амплитуд и определенные метки разговора. В них заменю 0 на Nan для того, чтобы остались только моменты, когда присутствует речь. Также добавлю колонку времени, разделив индекс на sr, получу значение времени в каждый момент.
df = pd.DataFrame( {'channel_1_orig':y[0]
,'channel_2_orig':y[1]
,'channel_1':abs(y[0])
,'channel_2':abs(y[1])*-1
,'channel_1_limit':y0
,'channel_2_limit':y1})
df['time'] = df.index / sr
df['channel_1_limit'] = df['channel_1_limit'].replace(0,np.nan)
df['channel_2_limit'] = df['channel_2_limit'].replace(0,np.nan)
Казалось бы, я получил нужный результат. На графике есть разметка в верхней и нижней части экрана, где осуществляется речь в первой и во второй дорожке соответственно.
sns.lineplot(data = df, x = 'time', y = 'channel_1')
sns.lineplot(data = df, x = 'time', y = 'channel_2')
sns.scatterplot(data = df, x = 'time', y = 'channel_1_limit',label = '1',marker = '+')
sns.scatterplot(data = df, x = 'time', y = 'channel_2_limit',label = '2',marker = '+')
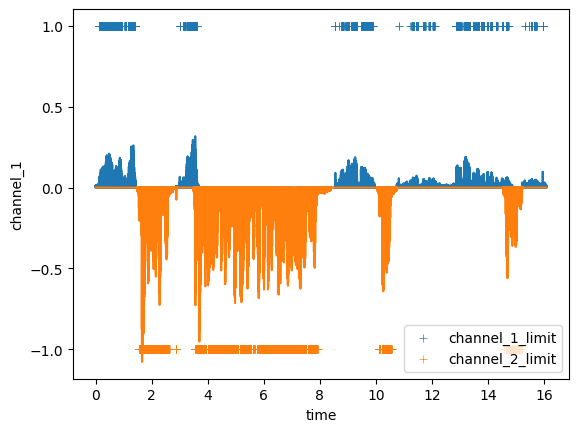
Но на самом деле это не так. Посчитав длительность размеченных разговоров, я получил суммарно 4.6 секунды, что явно не соответствует действительности.
len(df[~df.channel_1_limit.isna()]) / sr + len(df[~df.channel_2_limit.isna()])/ sr
4.602267573696145
Связано это с тем, что во время разговора синусоида множество раз пересекает 0 (частота пересечений зависит от частоты голоса). Соответственно значение амплитуды опускается ниже порога, т.е. в этот момент времени речь отсутствует, хотя разговор все еще идет. Это можно увидеть по разметке в нижней части графика. На графике отчетливо видно, что идет разговор, но не везде он помечен как разговор.
def plot_part(time_start,chanel,dur = 0.02, new = ''):
time_end = time_start + dur
df_plt = df[(df.time>time_start)&(df.time<time_end)]
sns.lineplot(data = df_plt, x = 'time', y = f'{chanel}_orig')
sns.scatterplot(data = df_plt, x = 'time', y = f'{chanel}_limit{new}',label = 'speech',marker = '|')
print('loss',len(df[(df.time>time_start)&(df.time<time_end)&(df[f'{chanel}_limit{new}'].isna())]) / len(df[(df.time>time_start)&(df.time<time_end)]))
plot_part(4,'channel_2')loss 0.4318181818181818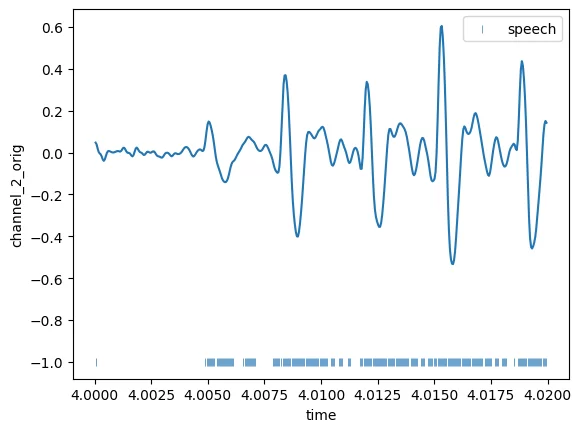
Попробую это исправить. Предположу, что если в текущий момент времени амплитуда разговора выше порога, то и следующую 0.1 секунду будет так же (в моем кейсе следующие 2205 точек).
points = int( 0.1 * sr )
df['channel_1_limit_new'] = df['channel_1_limit'].fillna(method = 'ffill',limit = points)
df['channel_2_limit_new'] = df['channel_2_limit'].fillna(method = 'ffill',limit = points)
plot_part(4,'channel_2',new = '_new')
loss 0.0
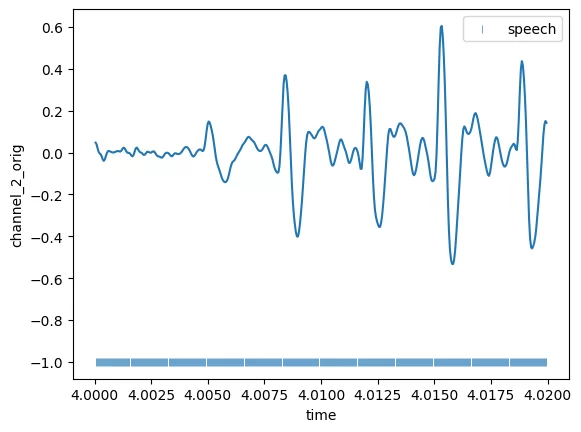
После выполненных выше преобразований получу общую длительность разговора ~ 14 секунд, что уже похоже на правду.
len(df[~df.channel_1_limit_new.isna()]) / sr + len(df[~df.channel_2_limit_new.isna()])/ sr
13.95891156462585
Для проверки корректности построения разметки построю график.
sns.lineplot(data = df, x = 'time', y = 'channel_1')
sns.lineplot(data = df, x = 'time', y = 'channel_2')
sns.scatterplot(data = df, x = 'time', y = 'channel_1_limit_new',label = '1',marker = '+')
sns.scatterplot(data = df, x = 'time', y = 'channel_2_limit_new',label = '2',marker = '+')
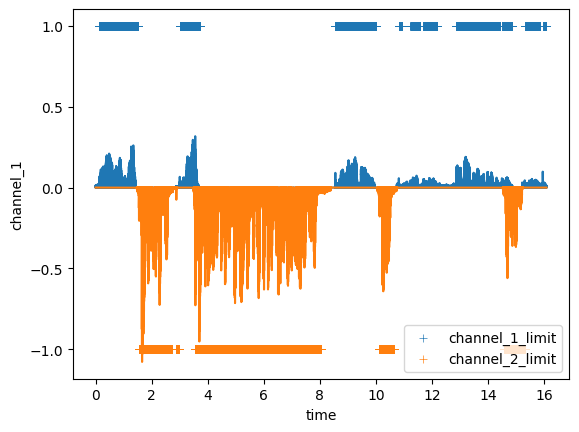
Пересечение меток в верхней и нижней частях графика покажет наличие разговора в обоих каналах. Длительность данного пересечения составляет 0.5 секунды.
len(df[~df.channel_1_limit_new.isna()&~df.channel_2_limit_new.isna()])/ sr
0.47750566893424035
Итоговый результат сформирую в отчет в виде таблицы. Данная таблица содержит в себе название файла, его длительность, время разговора из каждой дорожки, а также время, когда разговор присутствует в обеих дорожках одновременно.
df_add = pd.DataFrame({'file_name':file_name,
'total_duration':len(df)/sr,
'channel_1_duration':len(df[~df.channel_1_limit_new.isna()]) / sr,
'channel_2_duration':len(df[~df.channel_2_limit_new.isna()]) / sr,
'channel_1_2_duration':len(df[~df.channel_1_limit_new.isna()&~df.channel_2_limit_new.isna()])/ sr
},index = [0])
df_add

Благодаря этому алгоритму мне удалось быстро обработать аудиофайлы (5 минут на 100 записей длительностью в среднем 1 минуту) и получить сравнительно точные результаты разметки активного разговора.
В заключении отмечу, что предложенный алгоритм дает возможность извлекать разговоры из аудиозаписей, определять их длительность и вычислять пересечения диалогов с помощью библиотеки Librosa.
Важным моментом является, что алгоритм обладает определенной точностью, и на результаты могут оказать влияние шумы или особенности записи. Однако я предложил дополнительные улучшения, такие как использование окна времени для определения продолжительности разговоров, что повышает точность.
Резюмирую: представленный алгоритм позволяет эффективно анализировать аудиозаписи и выделять секции с разговорами, что может быть полезным в различных областях, включая распознавание речи, обработку данных и мониторинг коммуникаций.
Полный код программы размещен по ссылке.