/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
В основе систем распознавания речи стоит скрытая марковская модель, суть модели заключается в том, что при рассмотрении сигнала в промежутке небольшой длительности (от пяти до 10 миллисекунд), возможна его аппроксимация как при стационарном процессе.
Если простыми словами скрытую марковскую модель можно объяснить на примере.
Допустим, есть два человека, которые каждый вечер созваниваются и обсуждают свои действия в течение дня. Выбор одного из друзей: ходил за покупками; гулял в парке; занимался домашними делами. При выборе активности, он полагался лишь на погоду. Второй же знал о погоде, которая была на тот момент в месте первого и, основываясь на выборе первого, мог догадаться, какая погода была в какой-то момент.
То есть, допустим, мы делим сигнал на фрагменты скажем в 10 миллисекунд и выделяем кепстральные коэффициенты, которые, по сути, являются графиком зависимости мощности от частоты сигнала отображающегося на векторе действительных чисел. Результатом скрытой марковской модели является последовательность этих векторов.
В последствии мы сопоставляем фонемы и эти векторы, а так как звук фонемы изменяется от источника к источнику, то процесс сопоставления требует обучения.
Для python существует несколько пакетов которые используются в данной сфере речи, такие как apiai, assemblyai и другие, но Speech Recognition выделяется среди них довольно высокой простотой использования.
Библиотека Speech Recognition — это, инструмент для передачи речевых API от компаний (google, microsoft, sound hound, ibm, а также pocketsphinx), который в отличие от остальных имеет возможность работы офлайн.
Для демонстрации работы в данной статье я буду использовать дефолтный Google Speech API.
Также для работы с инструментами потребуется библиотека pyAudio.
Установим библиотеку для распознавания речи:
pip install SpeechRecognition Для работы с инструментами звукозаписи
pip install pyAudio Бываю некие сложности с установкой pyaudio через pip, поэтому альтернативный вариант — установка pipwin или conda
Для анализа звуковых данных
pip install librosa Для работы с wave файлами
pip install wave и импортируем в код
import speech_recognition as speech_r
import pyaudio
import wave
Для начала нужно выставить параметры записи звука:
CHUNK = 1024 # определяет форму ауди сигнала
FRT = pyaudio.paInt16 # шестнадцатибитный формат задает значение амплитуды
CHAN = 1 # канал записи звука
RT = 44100 # частота
REC_SEC = 5 #длина записи
OUTPUT = "output.wav"
Далее нужно создать объект для обращения к устройству звукозаписи:
p = pyaudio.PyAudio()и открыть поток для записи звука:
stream = p.open(format=FRT,channels=CHAN,rate=RT,input=True,frames_per_buffer=CHUNK) # открываем поток для записи
print("rec")
frames = [] # формируем выборку данных фреймов
for i in range(0, int(RT / CHUNK * REC_SEC)):
data = stream.read(CHUNK)
frames.append(data)
print("done")
и закрываем поток
stream.stop_stream() # останавливаем и закрываем поток
stream.close()
p.terminate()
Дальше нам нужно записать оцифрованную звуковую дорожку в файл.
Для этого нам и пригодится библиотека wave:
w = wave.open(OUTPUT, 'wb')
w.setnchannels(CHAN)
w.setsampwidth(p.get_sample_size(FRT))
w.setframerate(RT)
w.writeframes(b''.join(frames))
w.close()
В итоге мы получаем готовую звуковую дорожку записанную с микрофона устройства и готовую к распознаванию для этого нам потребуется библиотека Speech Recognition:
sample = speech_r.WavFile('C:\\Users\\User\\Desktop\\1\\pythonProject\\output.wav')Непосредственно для распознавания текста нам потребуется класс Recognizer он имеет множество функций, а также определяет каким API мы будем пользоваться:
r = speech_r.Recognizer()Открываем записанный файл.
Для расшифровки сигнала мы будем использовать метод recognize_google().
Для использования данного метода необходим объект AudioData и для дальнейшей работы требуется преобразовать сигнал в объект модуля Speech_recognition для этого существует метод record():
with sample as audio:
content = r.record(audio)
но, перед тем как передать сигнал на расшифровку, нужно очистить его от шумов. У библиотеки speech_recognition есть для этого метод adjust_for_ambient_noise()
with sample as audio:
content = r.record(audio)
r.adjust_for_ambient_noise(audio)
Так как выбранный нами Api поддерживает русский язык мы можем им воспользоваться:
print(r.recognize_google(audio, language="ru-RU"))Распознаватель возвращает: «Привет»
Таким образом у нас получается небольшой распознаватель речи буквально в пару строк кода. В момент, когда речь прекращается он автоматически переводит ее в текст.
Далее можно приступить к получению аналитических данных с помощью библиотеки librosa. Для начала загружаем наш файл:
A_Data = 'C:\\Users\\User\\Desktop\\1\\pythonProject\\output.wav'
y , sf = librosa.load(A_Data)
в данном случае мы получаем значения временного ряда звука в качестве массива с частотой дискретизации.
Далее мы можем вернуть график массива нашей звуковой дорожки. Для работы с графиком импортируем pyplot из библиотеки matplotlib и используем librosa.display.waveplot() для построения графика массива:
import matplotlib.pyplot as plt
import librosa.display
plt.figure(figsize=(14, 5))
librosa.display.waveplot(y, sr=sf)
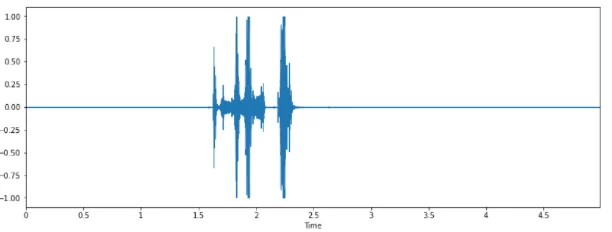
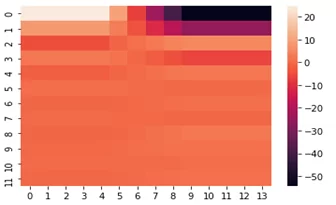
В самом начале я упоминал про кепстральные коэффициенты, они обычно используются для определения тембральных аспектов музыкального инструмента или голоса и мы можем построить их тепловую карту и хроматограмму.
fcc = librosa.feature.mfcc(y=y, sr=sf, hop_length=8192, n_mfcc=12)
import seaborn as sns
from matplotlib import pyplot as plt
fcc_delta = librosa.feature.delta(fcc)
sns.heatmap(fcc_delta)
plt.show()
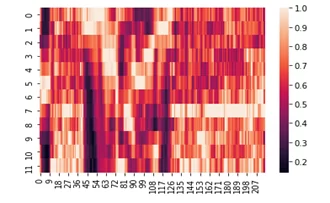
chromo = librosa.feature.chroma_cqt(y=y, sr=sf)
sns.heatmap(chromo)
plt.show()
Надеюсь, что данный материал будет полезен при решении задач по распознаванию речи.