/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Что такое .NET for Apache Spark?
Фреймворк .NET for Apache Spark — оболочка на языке c#, разработанная в спецификации .net для предоставления .net разработчикам возможности использования распределенной системы для разработки приложений обработки больших данных.
Фреймворк имеет следующие возможности:
- работать со структурированными данными и использовать синтаксис SQL запросов;
- работать с потоковыми данными;
- SparkML;
- подключения и получения данных из разных источников: hdfs, ms sql, postgre sql, kafka, elasticnet, azure и т.д.
Приложения, использующие фреймворк могут быть развернуты как на локальной машине под управлением windows или linux так и на облачных сервисах Microsoft благодаря соответствию стандарту .NET Standart и формальной спецификации .NET API.
С чего начать?
Прежде чем начать работать непосредственно с библиотекой, необходимо настроить окружение — скачать Microsoft.Spark.Worker с официального репозитория для нужной системы(windows/linux). Для систем под управлением windows — прописать переменную среду DOTNET_WORKER_DIR, установив в нее путь до папки со spark worker’ом, проверить доступность серверов spark и подключение к ним.
Также необходимо подключить пакет .net for apache spark к приложению. Для windows достаточно через интерфейс управления nuget пакетами visual studio загрузить и установить необходимый пакет. для linux предварительно необходимо скачать репозиторий и собрать библиотеку при помощи maven, а затем прописать зависимость для приложения.
Более подробно этот процесс расписан в официальной документации по фреймворку, так что я не буду на нем останавливаться.
Работа с фреймворком
На примере нескольких задач из моей практики я продемонстрирую работу с фреймворком.
Первая задача заключалась в разработке API для подсчета агрегированной статистики по количеству кредитов, выданных клиентам нескольких отделений для ранжирования. У нас был структурированный файл с данными по продажам кредитных продуктов банка, и при запросе к API необходимо было выдать пользователю готовую статистику по продажам в подразделениях в Json формате.
Я использовал отдельный класс для работы со spark, зарегистрировав его в промежуточном слое приложения:
builder.Services.AddSingleton<ISparkConnector, SparkConnector>();Для того чтобы получить доступ к распределенным вычислениям через spark, я инициализировал spark сессию. Собирается пайплайн сессии через метод Builder(), задается имя приложения, адрес сервера spark, а также параметры конфигурации для сессии. Инициализация сессии выполняется при вызове завершающего метода GetOrCreate():
public class SparkConnector : ISparkConnector
{
SparkSession spark;
public SparkConnector()
{
try {
spark = SparkSession
.Builder()
.Master("yarn")
.AppName("advertisement_count")
.Config("spark.driver.cores", "2")
.Config("spark.driver.memory", "4g")
.Config("spark.executor.memory", "2g")
.GetOrCreate();
} catch {
///недоступен spark сервер
///
...
}
}Полный список параметров конфигурации можно посмотреть в официальной документации по спарку. Я в своем коде использую только ограничения по памяти для экзекуторов.
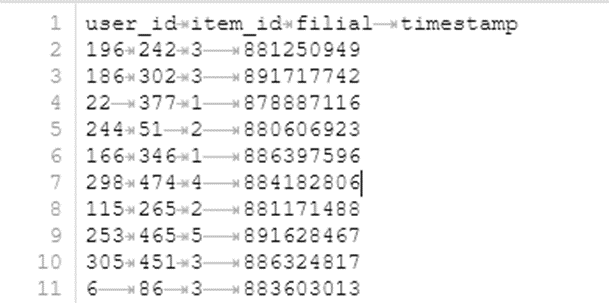
Для загрузки данных из hdfs необходимо задать формат читаемого файла и дополнительные опции для DataFrameReader, например, наличие заголовков в читаемом файле и разделитель:
var scores = spark.Read()
.Format("csv")
.Option("header", "true")
.Option("delimiter", "\t")
.Load("hdfs://my/hdfs/data/path/data.dat");
Фреймворк позволяет собирать пайплайны для работы с данными так, что решение умещается в несколько строк кода:
public string GetStatistic(string code = null)
{
if (code != null) {
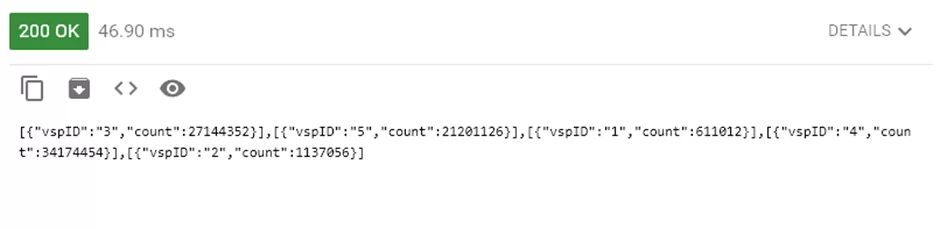
return String.Join(",", scores.Filter($"filial = {code}")
.GroupBy("filial")
.Count()
.ToJSON()
.Collect());
} else
{
return String.Join(",", scores
.GroupBy("filial")
.Count()
.ToJSON()
.Collect());
}
}Чтение данных в спарке реализовано через класс DataFrameReader, который инициализируется методом .Read(). Для него задается формат файла .Format(), устанавливаются дополнительные опции для чтения файла, например, кодировка, разделитель и заголовки для табличных файлов. Непосредственно данные читаются вызовом метода .Load(), в качестве аргумента в него передается локация файла в файловой системе. На выходе получается объект класса DataFrame, с которым уже производятся манипуляции через DataFrame API: GroupBy() для групировки по колонке, .Count() для подсчета количества записей по группам, .ToJSON() для преобразования данных в датафрейме в json формат и .Collect() для получения данных в приложение.
Готово! Осталось только создать метод контроллера, возвращающий данные:
[ApiController]
[Route("[controller]")]
public class SparkController : ControllerBase
{
private ISparkConnector _sparkConnector;
private readonly ILogger<SparkController> _logger;
public SparkController(ILogger<SparkController> logger, ISparkConnector sparkConnector)
{
_logger = logger;
_sparkConnector = sparkConnector;
}
[HttpGet(Name = "AdvStat")]
public string Get()
{
return _sparkConnector.GetStatistic();
}
}
Естественно, результат необходимо дополнительно обработать и привести его в нормальный формат для дальнейшего чтения. Здесь я опущу эти подробности, так как делается это без использования фреймворка.
Вторая задача заключалась в обработке лога отправки электронных писем c hdfs, объединив его с журналом договоров c mssql и подсчетом количества отправленных писем по группам заявок.
Для этой задачи я подключался к разным источникам. Лог отправки писем лежал на hdfs в формате parquet, так что запросить его можно, использовав метод DataFrameReader Parquet():
var logs = spark.Read().Parquet("hdfs://my/hdfs/data/path/maillogs");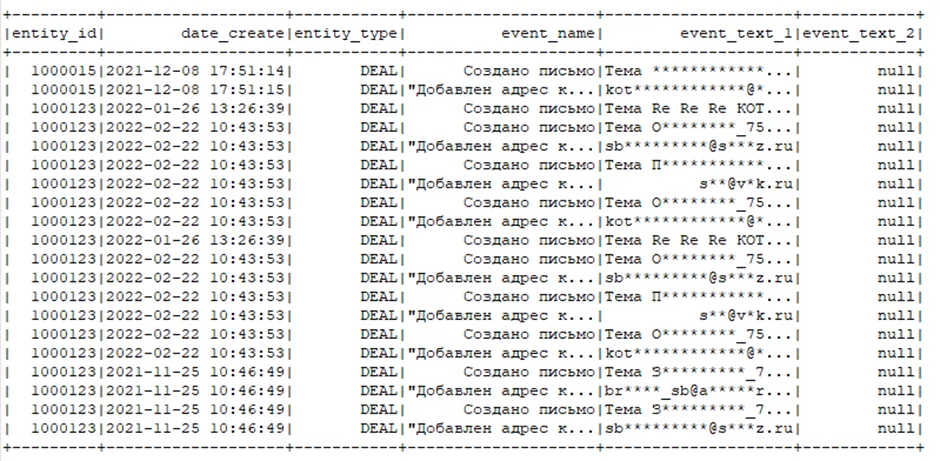
Для запроса данных из таблицы ms sql необходимо использовать jdbc драйвер, который указывается через метод .Format(). Также необходимо указать адрес ms sql сервера и таблицу из базы через метод Option():
var deals = spark.Read()
.Format("com.microsoft.sqlserver.jdbc.spark")
.Option("url", "\\ip.adress.mssql:port")
.Option("dbtable", "[crm].[reports].[deals]")
.Load();
Для начала я обрабатывал лог электронных писем. Меня интересовали только отправленные письма, в данном случае те, у которых присутствует событие «добавлен адрес к письму». Идущие друг за другом события «создано письмо» — «добавлен адрес к письму» определяют, что письмо было отправлено. Для отсеивания неотправленных писем по этой логике я использовал оконную функцию Lag(). Функция возвращает значение заданного поля из предыдущей строки:
logs = logs.WithColumn(“prev_event_name”, Functions.Lag("event_name",1).Over(Window.OrderBy("date_create")))
.WithColumn("prev_event_text_1", Functions.Lag("event_text_1",1).Over(Window.OrderBy("date_create")))
.Filter(logs["event_name"] == "Добавлен адрес к письму" && logs["prev_event_name"] =="Создано письмо");
Так как функция оконная, при помощи метода Over() определяется окно, в котором она будет работать. Окно задается через методы статического класса Window. В моем случае окном для выполнения метода Lag() является весь датафрейм, отсортированный по времени появления событий, поэтому я использовал метод OrderBy()
Посмотрим на еще одну возможность фреймворка — создание функций, определенных пользователем (user-defined functions или udf). Метод Udf<>() создает и регистрирует в контексте спарка функцию для обработки полей датафрейма по определенной пользователем логике. Для своей задачи я написал функцию выделения домена из почтового адреса:
var GetDomain = Functions.Udf<string, string>(
str => str.Split("@").Count() > 1 ? str.Split("@")[1] : "no domain";
);
var logs = logs.WithColumn("domain", GetDomain(scores["prev_event_text_1"]));
Далее к получившемуся датафрейму необходимо было присоединить информацию по договорам. Конкретно для моей задачи – сегмент клиента.
Для этого я использовал метод Join(). Чтобы избежать дублирования имен полей в результирующем датафрейме, можно передать методу не логическое выражение объединения, а массив с именами полей:
var segLogs = logs.Join(deals.Select("entity_id", "client_segment"), new List<string>() { "entity_id" }, "inner");После этого я посчитал количество писем, отправленных на каждый из доменов для каждого сегмента. Для этого я использовал метод Pivot(). Метод сводит колонку в строку и применяет для каждого поля функцию агрегации. В моем случае для подсчета количества писем я использовал Count():
var result = segLogs.GroupBy("client_segment").Pivot("domain").Count();
Результирующий датафрейм я сохранил на hdfs для дальнейшего взаимодействия с ним аналитиками. Сохранение результатов происходит через DataFrameWriter. Так же, как и с ридером, можно использовать дополнительные опции и указать формат сохраняемого файла, либо использовать стандартные функции сохранения, например .Parquet():
result.Write().Parquet("hdfs://my/result/folder/segments_mails_count");Заключение
Применив фреймворк .NET for Apache Spark, я решил несколько своих задач и приобрел интересный опыт взаимодействия с большими данными на платформе .net.
Для себя я выделил как положительные, так и отрицательные стороны.
Положительные: простота изучения, синтаксис методов повторяет такой у фреймворков на scala и python, легкая интеграция с .net приложениями, возможность преобразования результатов из объектов spark в с# структуры и дальнейшее их использование в приложении.
Отрицательные: необходимость дополнительной настройки машины для запуска приложения, без установки Microsoft.Spark.Worker и добавления переменной окружения программа не будет работать.