/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Настройка параметров выполнения задачи Spark является достаточно сложной и трудоёмкой, ведь помимо того, что необходимо вычислить оптимальный набор параметров в зависимости от возможностей кластера и объема данных, необходимо учитывать и то, что на кластере работает несколько человек. Одним из возможных решений данной проблемы является оптимизация работы задачи Spark при помощи задания параметров, характеризующих процесс обработки и хранения данных.
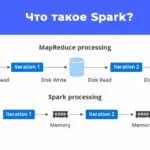
Перед тем, как рассмотрим процесс задания параметров, опишем то, как Spark производит обработку. Spark использует архитектуру ведущий/ведомый (master/slave) с одним центральным координатором и множеством распределенных рабочих узлов. Центральный координатор называется драйвером (driver). Драйвер взаимодействует с (возможно) большим числом рабочих узлов, которые называют исполнителями (executors). Драйвер и исполнители выполняются в отдельных и независимых друг от друга процессах Jаvа и составляют приложение Spark. В связи с чем основными параметрами, позволяющими настроить задачу Spark являются параметры настройки driver’а и executor’а.
Для настройки данных параметров Apache Spark предоставляет следующие варианты:
- Динамическое использование ресурсов кластера
- Использование параметров, установленных по умолчанию
- Задача параметров работы задачи Spark вручную
Вышеперечисленные варианты мы рассмотрим на примере фреймворка pyspark, позволяющего запускать задачи, используя понятный и удобный интерфейс языка Python.
В фреймворке pyspark параметры задаются при помощи класса SparkConf. В общем случае для установки параметра задачи используется метод set объекта SparkConf.
Рассмотрим каждый вариант отдельно.
Настройки Spark по умолчанию предполагают исключительно гарантированное исполнение задания при очень маленьких значениях кластера, что в свою очередь позволяет уменьшить расход ресурсов кластера, однако неприменимо для обработки больших объемов данных в силу большого времени обработки и большой вероятности завершения задачи с ошибкой нехватки памяти. Для использования данного способа достаточно просто создать задачу без задания каких-либо параметров.
Задача параметров динамическим образом позволяет избежать данных проблем, благодаря автоматическому определению параметров задачи. Однако, этот способ сопровождается риском использования слишком большого количества ресурсов, что в свою очередь значительно затрудняет обработку данных другими пользователями. В связи с чем не рекомендуется пользоваться данной настройкой на кластерах общего доступа (т.е. на кластерах, на которых может проводиться параллельная обработка разными людьми).
Пример:
conf = SparkConf().setAppName('SparkContextExample')\
.setMaster("yarn-client")\
.set('spark.dynamicAllocation.enabled', 'true')\#включен режим
динамических параметров
.set('spark.dynamicAllocation.executorIdleTimeout', '90')\ #время
простоя, по умолчанию infinity = 60 секунд
.set(spark.dynamicAllocation.initialExecutors', '9')\ # начальное
количество исполнителей
Наиболее оптимальным решением для работы на кластерах общего доступа является установка параметров вручную. Под задачей параметров в данном случае понимается определение размеров выделяемой памяти и количества executor’ов и driver’ов.
Пример:
conf = SparkConf().setAppName('SparkContextExample')\
.setMaster("yarn-client")\
.set('spark.dynamicAllocation.enabled', 'false')\ # отключен режим
динамических параметров
.set('spark.local.dir', 'sparktmp')\ # директория хранения времен-
ных файлов
.set('spark.executor.memory','5g')\ # объем памяти для каждого
исполнителя
.set('spark.driver.maxResultSize','5g')\ # объем памяти для ре-
зультата по умолчанию 1g, при «0» проигнорирует ограничение
.set('spark.executor.instances', '1')\
.set('spark.executor.cores', '8')\ # число ядер приложения
.set('spark.port.maxRetries', '150')\
Преимуществом данного способа является то, что выделенные пользователю ресурсы сохраняются до конца задачи, что, в отличие от динамического способа задачи параметров, позволяет обрабатывать данные быстрее за счет сохранения выделенных ресурсов кластера. Недостатком такого подхода является поиск оптимальных значений выделяемой памяти и количества обработчиков вручную, поскольку точного способа определения оптимального значения параметров не существует и поиск производится с помощью простого их перебора.
По итогу мы рассмотрели различные варианты задания параметров задачи Spark, описали их плюсы и минусы и привели простые примеры использования в Python. Сама я использую вариант статического задания параметров ввиду наибольшей производительности при работе на кластере общего доступа.
Надеюсь статья для Вас будет полезна. Буду рада Вашим комментариям и лайкам.