/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
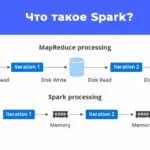
Основная проблема при работе с BigData – это не написание скрипта для получения результата, а максимальное сокращение времени его работы и объема затрачиваемых ресурсов. Для решения этих задач отлично подходит Apache Spark с его удивительно гибкими возможностями по оптимизации кода. Сегодня я опишу несколько способов оптимизации запросов.
- Не использовать collect().
Collect() может применяться в тех случаях, когда необходимо получить некоторый объем данных для их анализа. Команда collect() собирает результат и сохраняет его на DriverNode. На первый взгляд эта операция кажется безобидной, однако, если объем данных большой, то на драйвере может не хватить памяти для выполнения запроса:

В таком случае лучше применять команду take(n), где n – количество строк для выборки.
Take сканирует первую партицию и возвращает результат. Работает гораздо быстрее, чем collect и расходует меньше ресурсов.
2. Использование Persist
Когда вы начинаете работать в Spark, одна из первых особенностей, о которой вы узнаете – это принцип использования «ленивых» вычислений. Это означает, что Spark не будет выполнять операции трансформации до выполнения действия (action).
Попробуем выполнить следующий код.
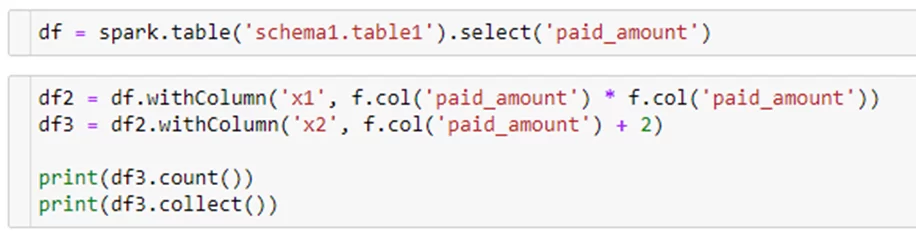

При запуске count() Spark выполняет указанные выше трансформации, затем делает то же самое при запуске collect(). Но! С помощью persist() можно сохранить один из результатов трансформации, чтобы не тратить время на его формирование при каждом запуске действия.
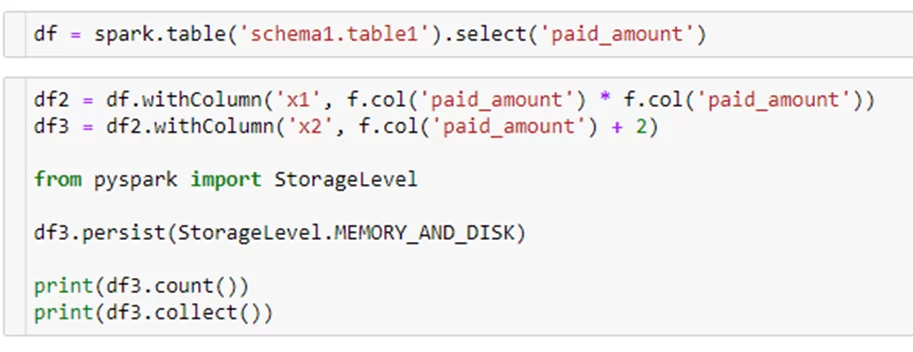

Параметр StorageLevel определяет куда будет сохранен результат:
MEMORY_ONLY
MEMORY_ONLY_SER
MEMORY_AND_DISK
MEMORY_AN_DISK_SER
DISK_ONLY
3. Следует избегать использование Groupbykey
При Groupbykey() сначала производится обмен данными затем происходит аггрегация, из за чего по сети передается большой объем данных:
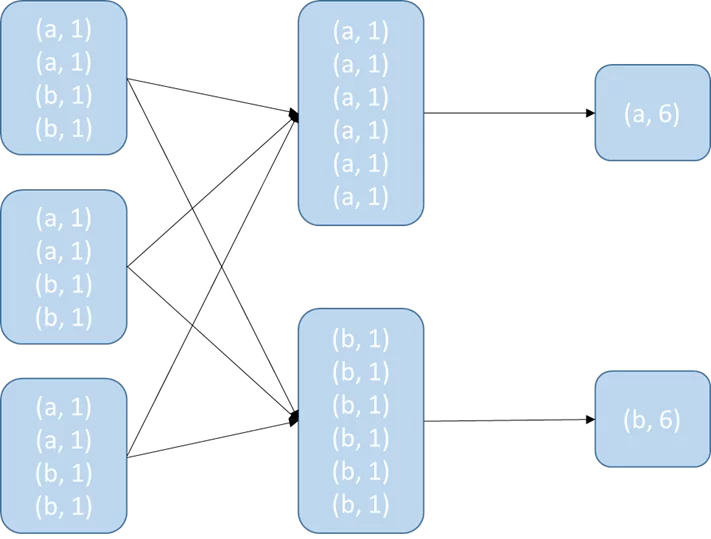
Reducebykey() сначала группирует данные внутри партиции, затем перемещает их и делает финальную группировку. Получается, что на каждом этапе сокращается объем передаваемой информации:
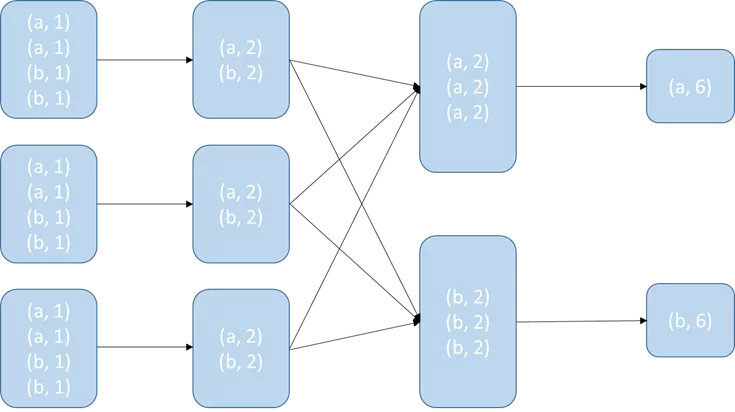
4. Пытайтесь эффективно использовать партиции.
Spark обрабатывает информацию параллельно. Он разделяет данные на партиции, которые содержат некоторую часть данных. Например, если в датафрейме 100000 строк и 20 партиций, в каждой партиции будет 5000 строк.
Количество партиций на кластере зависит от количества ядер, контролируемых DriverNode. Когда Spark запускает задачу, она выполняется на одном кластере. Количество партиций можно проверить с помощью следующего кода:

Если партиций слишком мало, то выделенные ядра будут простаивать.
Если слишком много, то запрос запрос будет выполняться дольше, чем мог бы.
Согласно документации Spark, рекомендуемы максимальный объем данных, который содержится в одной партиции – 128 МБ.
Для изменения количества партиций используется команда repartition(). Однако, при ее запуске происходит shuffle по всей сети, что неизбежно при увеличении количества партиций. Но можно избежать этого при уменьшении количества партиций с помощью команды coalesce(). Она уменьшает количество партиций, которые необходимо обработать для достижения указанного количества партиций.
5. Использовать Broadcast.
При выполнении запроса Worker-ы обмениваются информацией между собой, и для того, чтобы уменьшить нагрузку на сеть, можно передать данные, которые требуются каждому worker, с помощью broadcast() Это делается для того, чтобы при каждом Task Worker не запрашивал ее из другого места (например, другой ноды) .

Производим операцию join двух датафреймов df_1 и df_2. Предположим, что df_2 – это справочник, содержащий код страны и ее название. В df_1 нужно «подтянуть» название страны по ее коду. Для сокращения времени выполнения запроса «транслируем» df_2 на каждый worker.
Вышеуказанные советы по оптимизации лишь малая часть из всех возможностей Spark. Надеюсь, они помогут новичкам лучше изучить принципы работы Spark и позволят эффективней использовать свое время и ресурсы при выполнении задач.