/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Каждый пользователь создает нагрузку на кластер, и посмотреть параметры каждого работающего Spark-приложения возможно в представлении Resource manager UI через YARN.
В случае, когда запущено несколько приложений, посмотреть их параметры довольно просто, но что делать, если таких приложений несколько десятков? Оптимальным вариантом решения такой задачи был бы отчет на момент времени со всеми интересующими параметрами. Основное преимущество такого отчета в том, что пользователь сможет сразу увидеть любые интересующие его параметры приложений, доступные для просмотра через из YARN Resource manager UI.
Разберу один из способов, который может упростить отслеживание нагрузки на кластер и не требует каких-то особых прав доступа и разработки своей версии UI. Например, мне интересно, сколько информации было обработано приложением (параметр Aggregate Resource Allocation) и какие значения задали пользователи при конфигурации для следующих параметров:
• spark.dynamicAllocation.enabled – динамическое распределение ресурсов;
• spark.driver.memory – максимальный объем памяти драйвера;
• spark.driver.maxResultSize – максимальный объем информации приходящей с воркеров на драйвер;
• spark.executor.memory – объем памяти исполнителя;
• spark.executor.cores – число процессоров исполнителя.
В пользовательском интерфейсе посмотреть параметры возможно на главной странице Application и на вкладке Environment, пример этих экранов на изображениях ниже, параметры подчеркнуты красной линией:
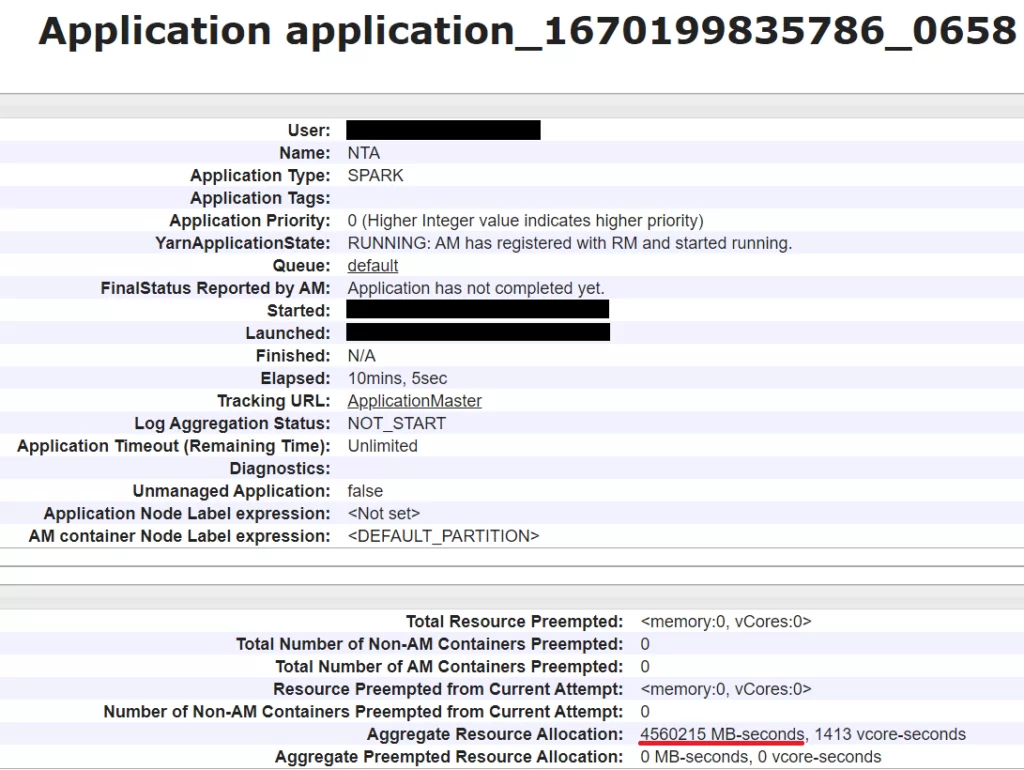
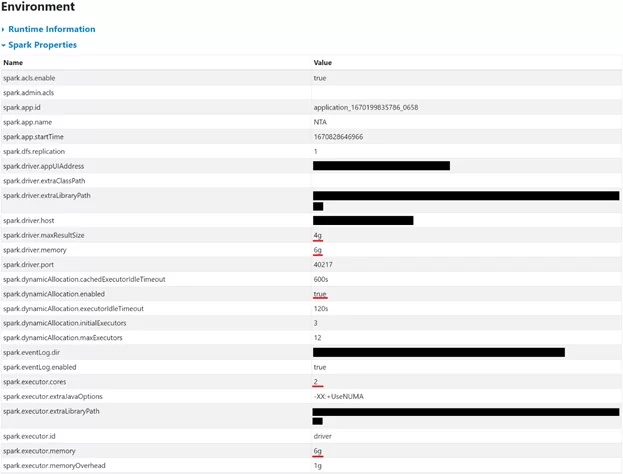
 Параметры у одного из приложений следующие:
Параметры у одного из приложений следующие:
| Aggregate Resource Allocation: | 1369869 MB-seconds, 363 vcore-seconds |
| spark.dynamicAllocation.enabled | true |
| spark.driver.memory | 6g |
| spark.driver.maxResultSize | 4g |
| spark.executor.memory | 6g |
| spark.executor.cores | 2 |
Для получения сводного отчета о параметрах всех запущенных приложений напишу небольшой скрипт на Python в JupyterLab на кластере. При его выполнении будет использоваться YARN и следующие библиотеки:
import subprocess
import requests
import re
import pandas as pd
from bs4 import BeautifulSoup
Параметры будут выбираться по наименованию на вкладке Environment либо по маске для поиска, функция ниже выполняет эту задачу:
#Поиск параметров в таблице
def find_value(df, target_var, target_mask):
tag_values = df['Value'][df['Name'] == target_var].values
if len(tag_values) == 0:
tag_values = re.findall(target_mask+'=(.*?)\s', site_res)
return tag_values
Начинается сбор данных с запроса к YARN, для этого с помощью библиотеки subprocess направляется команда yarn application –list. Для удобства собирается базовая информация о приложении – его наименование, тип (например, SPARK или TEZ), логин пользователя, ссылка на ноду, с которой было запущено приложение, и объем обработанных данных. Далее алгоритм обращается к YARN Resource manager UI и собирает детальную информацию о настройках приложений.
#Сбор данных о приложениях
result_array = []
#Обращение к YARN для получения списка приложений
cmd = 'yarn application -list'
applications = subprocess.check_output(cmd, shell = True).splitlines()
for app in applications[2:]:
app_name = ''
app_type = ''
app_user = ''
app_url = ''
app_resources_mb = ''
spark_driver_memory = ''
spark_dynamicAllocation_enabled = ''
spark_driver_maxResultSize = ''
spark_executor_memory = ''
spark_executor_cores = ''
time = ''
#Выбор id приложения
app_id = str(app).split('\\t')[0].replace("b'", "")
print(app_id)
#Получение параметров активных приложений
cmd = 'yarn application -status '+app_id
status = subprocess.check_output(cmd, shell = True).splitlines()
#Сбор информации из полученного ответа
app_name = re.findall("Application-Name\s\:\s(.*?)\'", str(status))
app_type = re.findall("Application-Type\s\:\s(.*?)\'", str(status))
app_user = re.findall("User\s\:\s(.*?)\'", str(status))
app_url = re.findall("Tracking-URL\s\:\s(.*?)\'", str(status))
app_resources_mb = re.findall("Aggregate Resource Allocation\s\:\s(.*?)\sMB-seconds", str(status))
#Получение параметров SPARK-приложений из YARN Resource manager UI
if app_type == ['SPARK']:
#Ссылки на YARN Resource manager UI
site_res = requests.get("http://my_cluster.ru:8088/proxy/"+app_id+"/environment/").text
site_jobs = requests.get("http://my_cluster.ru:8088/proxy/"+app_id+"/").text
#Поиск последнего Job-а и запись в переменную даты и времени его выполнения
jobs_info = BeautifulSoup(site_jobs, 'lxml').find_all('table', attrs={'id': 'completedJob-table'})
if len (jobs_info) > 0:
jobs = []
trs = jobs_info[0].find_all('tr')
for row in trs:
tds = row.find_all('td')
tds = [ele.text.strip() for ele in tds if ele != '']
jobs.append(tds)
if len(jobs) == 1:
time = jobs[0][2]
elif len(jobs) > 1:
time = jobs[1][2]
else:
time = '0'
soup = BeautifulSoup(site_res, 'html.parser')
tab = soup.find_all("table", {"class": ["table table-bordered table-condensed table-striped sortable", "table table-bordered table-sm table-striped sortable"]})
#Если найдена таблица с конфигурацией, то необходимые параметры выбираются из нее, но если не найдено значение параметра, будет осуществлен его поиск на странице.
#Как правило, параметры хранятся в таблице, но могут быть только в sun.java.command
df = pd.read_html(tab[1].prettify())
df = df[0]
spark_dynamicAllocation_enabled = find_value(df, 'spark.dynamicAllocation.enabled', 'spark\.dynamicAllocation\.enabled')
spark_driver_memory = find_value(df, 'spark.driver.memory', 'spark\.driver\.memory')
spark_driver_maxResultSize = find_value(df, 'spark.driver.maxResultSize', 'spark\.driver\.maxResultSize')
spark_executor_memory = find_value(df, 'spark.executor.memory', 'spark\.executor\.memory')
spark_executor_cores = find_value(df, 'spark.executor.cores', 'spark\.executor\.cores')
#Заполнение итоговой таблицы
result_array.append([app_id
,','.join(app_name)
,','.join(app_type)
,','.join(app_user)
,','.join(app_url)
,','.join(app_resources_mb)
,','.join(spark_driver_memory)
,','.join(spark_dynamicAllocation_enabled)
,','.join(spark_driver_maxResultSize)
,','.join(spark_executor_memory)
,','.join(spark_executor_cores)
,time])
#Формирование отчета
dff = pd.DataFrame(data=result_array, columns = ['id'
,'name'
,'type'
,'user'
,'url'
,'resources_mb'
,'driver_memory'
,'dynamicAllocation_enabled'
,'driver_maxResultSize'
,'executor_memory'
,'executor_cores'
,'time'])
dff['resources_mb'] = dff['resources_mb'].apply(lambda x : '{0:,}'.format(int(x)).replace(',',' '))
dff['time'] = dff['time'].apply(lambda x : x.replace('/', '-'))
dff.sort_values(by = 'user')
Некоторые приложения могут не выполнять задач на момент формирования отчета, и для удобства их поиска в отчет добавлена дата запуска последней задачи (Job). Если приложение было запущено, но задач еще не выполняло, будет указано значение 0.
В итоге я получил отчет следующего вида:
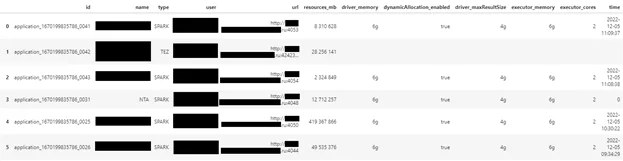
Используя такой отчет, возможно оперативно реагировать на приложения, конфигурация которых не соответствует мощности кластера, либо на приложения, которые находятся в простое длительное время. Он может быть полезен как администраторам кластеров, так и рядовым пользователям, особенно в ситуации, когда для запущенных приложений не хватает ресурсов и необходимо определить причину.
Несомненным преимуществом является отсутствие необходимости создавать специализированные формы для взаимодействия с YARN Resource manager UI, а доработать код для вывода не указанных в примере полей не составит труда.
Следует отметить и минусы такого подхода, например, при возникновении ошибки обращения к конфигурации приложения через UI, алгоритм также выдаст ошибку или будет ожидать ответа. Для таких случаев возможно написать обработчик исключений, но сама ситуация уже является поводом для администраторов обратить внимание на состояние кластера.