/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
В данной статье речь пойдет о внутреннем устройстве (архитектуре) Spark, т.е. о процессах, которые происходят после запуска Spark приложения. В рамках разработки приложения разработчик должен иметь представление, что происходит от старта до окончания работы Spark приложения. Данная информация необходима для понимания, где искать ошибки, каким образом ориентироваться в логах и оптимизировать приложение.
Основной набор данных, используемый в Spark – RDD.
RDD — Resilient Distributed Dataset – отказоустойчивый распределенный набор данных, которым можно оперировать почти так же, как и с обычным списком, но с дополнительными доступными методами и с автоматическим распараллеливанием, разработчику нужно лишь давать подсказки о том, как именно разделять данные, исходя из характеристик кластера и задач.
Однако, RDD это низкоуровневая абстракция в Spark. Для работы с данными как с таблицами, часто используется API Dataframe.
Dataframe – часть модуля Spark SQL. Dataframe позволяет удобнее работать с табличными данными.
Также Dataframe имеет встроенный оптимизатор Catalyst, который после вызова action оптимизирует запрос, вследствие чего, в большинстве случаев, Dataframe более эффективен, чем RDD. При возможности использования Dataframe, не рекомендуется использовать RDD.
Dataframe имеет синтаксис, схожий с синтаксисом Dataframe из Pandas.
Также Dataframe позволяет писать на sql подобном синтаксисе:
spark.sql(‘’’SELECT * FROM tablename‘’’)
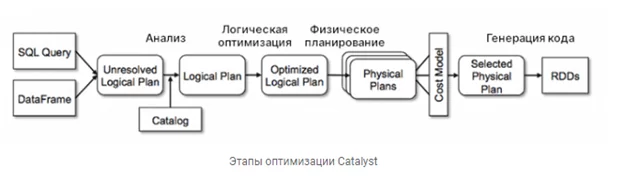
На рисунке представлено краткое описание работы оптимизатора запросов Catalyst.
Коротко о работе Spark приложения:
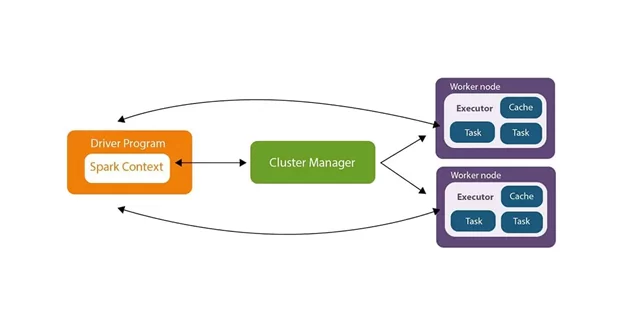
При запуске приложения, Driver запускает main(), в котором создается SparkContext — основной класс Spark приложения. Driver на протяжении всей работы приложения управляет потоком заданий (jobs), планирует задачи (tasks). Driver считывает необходимые данные из источника данных (hdfs, hive и т.д) и распределяет задачи. Далее каждый из узлов Hadoop кластера выполняет инструкции, описанные в задачах, но с различными данными, которые распределяет Driver. При необходимости данные сохраняются в форматах json, csv, parquet и т.д
Все данные в Spark хранятся в файлах, разделенных на партиции. Основной формат хранения данных Spark приложения – parquet, изначально созданный для работы с экосистемой Hadoop. Количество партиций в Spark приложении указывает разработчик, либо берется дефолтное значение (200 partitions).
Далее рассмотрим более подробно работу Spark приложения и соответствующие компоненты.
В работе Spark приложения участвуют следующие основные компоненты:
- Cluster Manager (YARN, Kubernetes, Spark Standalone Mode, Mesos)
Все они отвечают за планирование задач, распределение ресурсов и очередность выполнения задач.
- Cluster – группа виртуальных узлов, каждая из которых запускается на JVM, соединенных сетью и запускающие Spark.
- Driver (драйвер) – управляющий процесс, который запускает main() и создает SparkContext, с этого и начинается вся работа приложения. Драйвер запускается на Мастер ноде Hadoop кластера и проводит все преобразования RDD. Драйвер играет роль главного узла кластера.
- SparkContext – класс, который создает RDD.
- SparkSession – класс, который создает DataFrame.
- Executors (исполнители) – один или несколько распределенных процессов, количество которых зависит от количества выделенных ядер процессора на каждого исполнителя.
- Task (Задача) – наименьшая единица в Spark, которая выполняет определенную задачу для одной партиции. Например, если набор данных состоит из 5 партиций, то и задач будет 5, выполняемых на каждой партиции отдельно. Каждая задача выполняется одним ядром в исполнителе.
Job (Джоба) – последовательность трансформаций, заканчивающихся действием. - Stage – последовательность джобов, которые можно выполнить без shuffle (перетасовка данных между узлами Hadoop кластера).
Зная за что отвечает каждый из компонентов Spark приложения, можно понять, на каком этапе произошла ошибка, либо улучшить работоспособность, изменив часть кода, который отвечает за замедляющий приложение этап.
Трансформации и Действия
Трансформации – промежуточные изменения.
Действия – завершающий последний этап, после вызова которого начинают работу трансформации.
Все трансформации в Spark (map, filter и т.д), как и в scala, ленивые, т.е. пока не будет вызвано завершающее действие (save, count, show и т.д.), Spark не будет изменять rdd. Изменения, если они необходимы, произойдут лишь после вызова действия.
Одной из важных причин, почему необходимо понимать архитектуру Spark приложения является мониторинг выполнения вашего приложения. Если не знать, как работает приложение, то будет проблематично отслеживать процессы, оптимизировать приложение, понимать причину сбоев и т.д
Ниже представлен пример dag visualization, который описывает шаги выполнения приложения.
Возьмем простой пример Spark приложения, который обращается к Hive таблице и выводит его содержимое:
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
object Main extends App {
/**
* Инициализация SparkSession
* Основной класс Spark, позволяющий работать с RDD, Dataset, DataFrame
* Добавляем возможность использования Hive и динамическое секционирование таблиц
*/
val spark = SparkSession.builder.
appName(getClass.getSimpleName).
config("hive.exec.dynamic.partition", "true").
config("hive.exec.dynamic.partition.mode", "nonstrict").
enableHiveSupport.getOrCreate
/**
* Обращение к Hive таблице на диалекте Hive Query Language (HQL)
* В методе sql используется код, схожий со стандартным sql синтаксисом
* tableName - название таблицы в Hive хранилище
* show - вывод содержимого таблицы c указанием количества строк и truncate
*/
val schemaName = "schemaName"
val tableName = "tableName"
val hive_data = spark.sql(s"select * from $schemaName.$tableName")
hive_data.show(100, truncate = true)
}
Как видно из DAG, Stage начинается с WhileStageCodegen, где происходит объединение трансформаций и оптимизация запроса. Далее происходит стадия map, где в зависимости от конфигурации SparkSession все преобразования map происходят либо на одной ноде, либо на нескольких, результат которых записывается в партиции.
В HDFS одна партиция равна одному блоку, размер которого указывается в конфигурации кластера. Данный параметр можно изменить вручную при создании SparkSession, чаще всего это 64mb или 128mb.
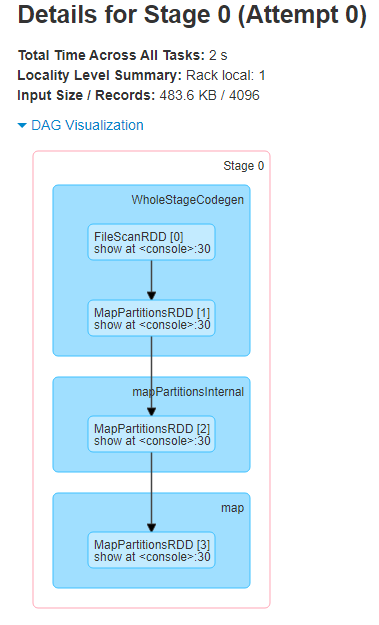
Как было описано выше, Stage это множество
Если вам важна скорость обработки данных, выбор Spark является верным решением, но стоит помнить, что Spark потребляет много оперативной памяти в своих вычислениях.
В рамках данной статьи мы рассмотрели архитектуру Spark приложения, для чего ее нужно знать, как и вследствие чего происходит оптимизация запросов. Надеемся информация будет для вас полезной!