/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
С помощью несложного текст майнинга можно узнать, за что дают подарки.
Компания своим клиентам дарит подарки. Причины различны. И сотрудники компании вносят информацию о них в систему, данные которой хранятся на HADOOP.
Данных много и они не структурированы. Поэтому, для того чтобы выяснить какие слова (теги) чаще всего встречаются в причинах выдачи подарков, можно это сделать достаточно быстро и эффективно с использованием методов машинного обучения — Text Mining.
Так как данные хранятся в HADOOP — логично использовать библиотеки, которые для этого разработаны — PYSPARK ML.
Что нам нужно:
- Создать набор данных для текст майнинга.
- Обработать его с помощью библиотек PYSPARK ML.
- Визуализировать.
- Создание набора данных для текст майнинга.
Подключимся к HADOOP через Python, используя библиотеки PySpark:
import os
import sys
from pyspark import SparkConf
from pyspark.sql import SparkSession, HiveContext, SQLContext
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType, ArrayType
import pandas as pd
conf = SparkConf().setAppName('text_mining').setMaster('yarn')
conf.setAll([
## здесь ваши set
])
spark = SparkSession.builder.config(conf=conf).enableHiveSupport().getOrCreate()")
sqlc = HiveContext(spark)
sqlContext =SQLContext(sqlc)
И создадим набор данных для текст — майнига:
query = '''SELECT descriptions FROM crm_podarki'''
# descriptions - информация, внесенная работниками в систему о причинах
df = sqlContext.sql(query)
df.show(5)

2. Обработка набора данных с помощью библиотек PYSPARK ML.
Загрузим необходимые библиотеки для текст майнинга:
from pyspark.ml.feature import RegexTokenizer
import nltk
import pymorphy2
from nltk.corpus import stopwords
pymorph = pymorphy2.MorphAnalyzer()
ru_stop_word = stopwords.words('russian')
Используем RegexTokenizer для разбиения текста на отдельные слова:
rt = RegexTokenizer(inputCol = "descriptions",outputCol = "txt",pattern=r"\s+")
df_text =rt.transform(df)

Определим функцию для нормализации (лемматизации) слов и исключения из текста стоп-слов.
def prep(text):
text = [str(pymorph.normal_forms(word)[0]) for word in text if word not in ru_stop_word]
Return text
Приведем слова в тексте к первоначальному виду и удалим стоп-слова:
prep_udf = udf(prep, ArrayType(StringType()))
df_text =df_text.withColumn('final',prep_udf('txt'))
df_text.show(5)

Последний штрих: загрузим все слова в один DataFrame и сохраним в файл формата csv:
df_pd = df_txt.toPandas()
pd_list=[]
for lst in df_pd['final']:
pd_list += lst
df_pd_text = pd.DataFrame(df_list, columns=['words'])
df_pd_text.to_csv('podarok.csv')
Таким образом, мы получили файл со всеми словами, которые были в текстах сообщений.
3.Визуализация результатов майнинга текста.
Для визуальной оценки воспользуемся стеком ElasticSearch — Kibana.
Загрузим полученный файл в индекс ElasticSearch, используя инструмент Kibana.
Для визуализации воспользуемся инструментом визуализации — облако тегов.
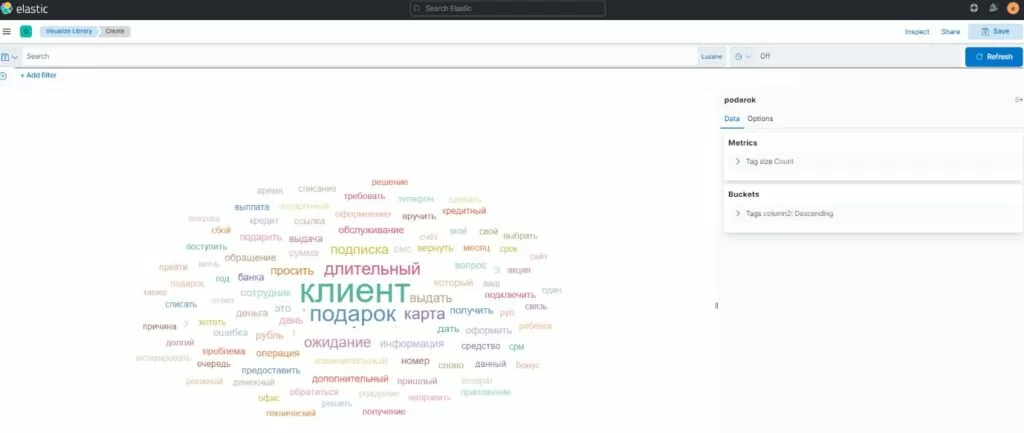
Видим: в облаке есть слова, которые не относятся к причинам: “Клиент”,”Подарок”.
Последний штрих: сделаем ручную настройку для исключения этих слов из облака тегов и добавим фильтры по эти словам:
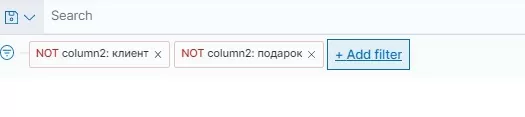
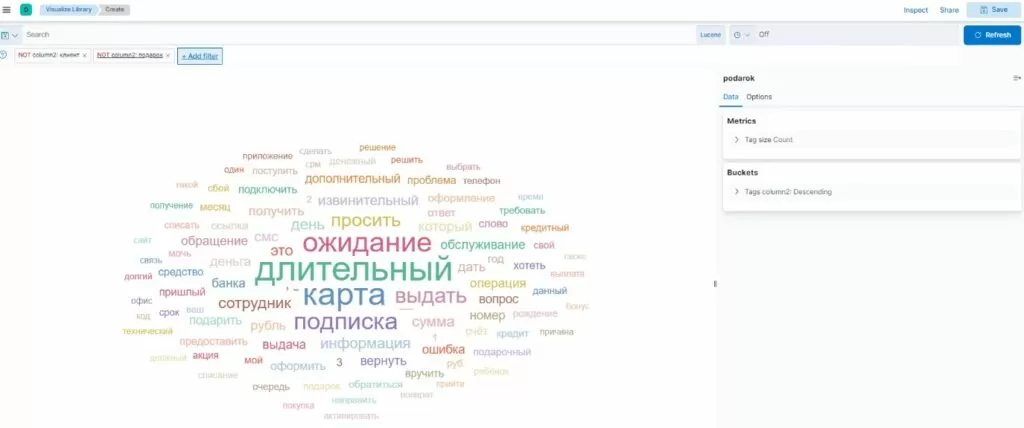
Таким же образом можно исключить и другие теги, которые визуально не относятся к словам причин подарков.
Следующий этап – для смыслового текст майнинга причин получения подарков можно использовать преобразование текста в вектор (например: библиотека MUSE), но эта тема для отдельной статьи.
Как видите, не так много нужно действий и кода, чтобы узнать — получать подарки просто!