/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Предыстория
Когда-то давно четыре народа… К-хм. Не так давно на нашем кластере было признано использование Hive запросов нежелательным в силу того, что:
- Hive-запросы управляются TEZ, им по умолчанию выделяется максимум ресурсов, вплоть до того, что эти ресурсы перенаправляются с уже работающих Spark-сессий.
- Невозможно переопределить параметры выделения ресурсов на TEZ-сессии и установить для них пороговые значения как, например, было бы возможно с MapReduce.
- TEZ будет пытаться выполнить запрос, даже если запрос пользователя не оптимизирован, например, обращается к весомой партиционированной таблице без использования партиций.
- Мониторинг работы таких запросов менее информативен и в основном показывает информацию о факте выполнения запроса в моменте, без показа текста запроса, информации по подзадачам и т.д.
Альтернативой Hive-запросов был определен Spark. Он работает более дружелюбно, потребление ресурсов легче контролировать, а анализ spark-сессий гораздо проще: можно увидеть подзадачи и диаграмму запроса. Однако пользователи-аналитики лучше знают SQL и по этой причине предпочитают работать с HiveQL в силу почти идентичного синтаксиса, удобства работы в HUE. Учитывая, что аналитикам нужно некоторое время на обучение новому инструменту, они продолжали работать с Hive. Но закон есть закон. На плечи администраторов кластера выпала задача “убивать” (Так как приложения помечаются статусом KILLED, от англ.: убито) Hive-приложения и, побыв какое-то время своего рода «палачом», устав от необходимости периодически отслеживать запущенные приложения, мы решили автоматизировать этот процесс, чтобы пользователи обижались на «злую машину», а не админа.
К этому моменту я уже имел опыт обращения к API ResourceManager’а в целях сбора истории приложений кластера. К слову, Hadoop предлагает огромный функционал взаимодействия с его экосистемой через API.
Hadoop API
Я не перестаю восхищаться титаническим трудом разработчиков Hadoop и предоставляемые API – это одна из причин уважения (помимо этого прекрасного жёлтого слона, при виде которого в голове начинает играть “What a Wonderful World” Луи Армстронга). Перечислю основные возможности:
- Полноценное взаимодействие с HDFS;
- Управление MapReduce приложениями и их историей;
- Управление Yarn-службами;
- Взаимодействие с Yarn Timeline;
- Взаимодействие с NodeManager;
- Взаимодействие с ResourceManager,
Последним я и воспользовался в своей задаче.
Вероятно, вам тоже уже знаком веб-интерфейс ResourceManager’а, с помощью которого можно следить за объёмом занимаемых приложением ресурсов, перечнем работающих приложений, отработавших и т.д.
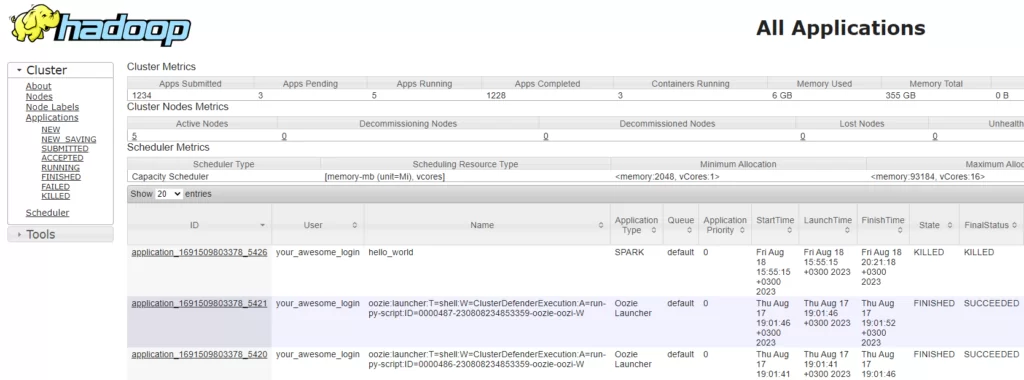
Моя задача была среди работающих приложений найти те, что управляются TEZ (означает, что это Hive-запрос), взять его id и попросить Yarn прекратить его работу. Не трудоёмкий процесс, но рутинный и требует периодического отвлечения от основных задач. Так, опираясь на указанные действия, я и сформулировал алгоритм: с некой периодичностью получать список текущих приложений и находить те, что нас не устраивают, и останавливать их выполнение.
Для того чтобы получить список текущих приложений, сформируем следующий GET запрос:
http://<<host>>:<<port>>/ws/v1/cluster/apps/state=<<states>>,
где:
host – Хост ResourceManager’а;
port – Порт ResourceManager’а (Стандартное значение 8088);
states – Список состояний приложений, которые мы хотим получить: ACCEPTED –принятых в работу, RUNNING – выполняющихся в текущий момент и т.д.
Для того, чтобы остановить приложение, воспользуемся следующим PUT запросом:
http://<<host>>:<<port>/ws/v1/cluster/apps/<<application_id>>/state?user.name=<<user>>,где:
application_id – id приложения, которое мы можем получить из предыдущего запроса;
user – Пользователь, от лица которого приложение будет приостановлено (Здесь, на самом деле, может быть почти любая строка, например, “Michael_Jackson_is_not_my_dad”).
Перейдём к написанию кода.
Код
Для того чтобы общаться с API, мы можем использовать requests или subprocess + curl. В своей задаче я использовал оба варианта, так как кластер работает под Kerberos и по ряду причин установить gssapi и, как следствие, библиотеку requests_kerberos, из которой можно было бы взять класс с Kerberos-авторизацией, не предоставляется возможным. Поэтому, для получения списка приложений я воспользовался requests в силу простоты работы с json и subprocess + curl, а также в силу поддержки авторизации через Kerberos.
Подгрузим библиотеки:
import requests
import subprocess
Напишем функцию для получения списка приложений:
def get_all_apps(host: str, port: str, states: list[str]) -> list:
r = requests.get('http://{}:{}/ws/v1/cluster/apps/?state={}'.format(host, port, ','.join(states)))
return r.json().get('apps').get('app')
Теперь сформируем список фильтров, по которым мы отберём нежелательные:
filters = [
lambda x: (x.get('applicationType') == 'TEZ') & (x.get('elapsedTime') / (60 * 1000) >= 5)
]
И функцию, которая вернёт отфильтрованный список:
def get_target_apps(apps: list[dict], filters: list[callable]) -> list:
return [x for x in apps if any([func(x) for func in filters])]
Теперь функция, чтобы сделать PUT запрос, на изменение состояния приложения:
def kill_app(host: str, port: str, app_id: str):
subprocess.run([
'curl',
'-X', 'PUT',
'-H', 'Content-Type: application/json',
'-d', '{"state": "KILLED"}',
'--negotiate', '--user', ':',
'http://{}:{}/ws/v1/cluster/apps/{}/state?user.name=cluster_defender'.format(host, port, app_id)
], stdout=subprocess.PIPE)
Наконец:
if __name__ == '__main__':
all_apps = get_all_apps(host, port, states)
target_apps = get_target_apps(all_apps, filters)
[kill_app(x.get('id')) for x in target_apps]
Периодическое исполнение
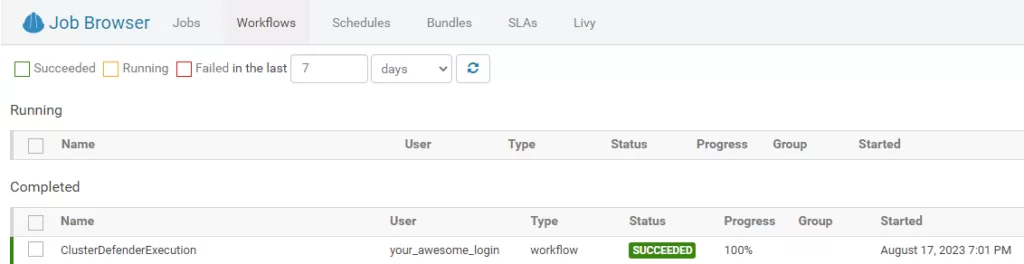
Следующим шагом будет постановка на периодическое исполнение. Сделать это можно как средствами python (например, при помощи цикла while и функции sleep модуля time), так и планировщиками: cron и oozie. Я выбрал oozie, так как это инструмент экосистемы Hadoop, работу которого также можно отслеживать с помощью Hue или ResourceManager. Для того чтобы выставить расписание для задачи, нам нужно сделать следующее:
- сформировать три файла: файл со свойствами, файл с описанием алгоритма исполнения и файл-координатор, с информацией о времени выполнения соответственно:
coordinator.properties,
frequency=5
startTime=2023-08-16T14:00Z
endTime=9999-12-31T23:59Z
timezone=Europe/Moscow
jobTracker=<< ResourceManager API endpoint >>
nameNode=<< HDFS API endpoint >>
ownerIPA=your_awesome_login
ScriptFileName=main.py
ScriptFilePath=main.py
workflowPath=${nameNode}/user/${ownerIPA}/oozie
oozie.coord.application.path=${nameNode}/user/${ownerIPA}/oozie
oozie.libpath=${nameNode}/user/oozie/share/lib
workflow.xml
<workflow-app name="ClusterDefenderExecution" xmlns="uri:oozie:workflow:0.1">
<start to="run-py-script"/>
<action name="run-py-script">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<exec>${ScriptFileName}</exec>
<file>${ScriptFilePath}#${ScriptFileName}</file>
<capture-output/>
</shell>
<ok to="end"/>
<error to="kill"/>
</action>
<kill name="kill">
<message>Error occured during execution, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
coordinator.xml:
<coordinator-app name="ClusterDefenderCoordinator" frequency="${frequency}" start="${startTime}" end="${endTime}" timezone="${timezone}" xmlns="uri:oozie:coordinator:0.1">
<action>
<workflow>
<app-path>${workflowPath}</app-path>
</workflow>
</action>
</coordinator-app>
2. Разместить скрипт, файлы workflow.xml и coordinator.xml на HDFS;
3. Запустить задачу используя следующую команду:
oozie job -config coordinator.properties -oozie <<Ссылка на API Oozie>> -run4. Отслеживать и, при необходимости, корректировать выполнение в Hue или в терминале при помощи команд:
oozie job -info jobId -oozie <<Ссылка на API Oozie>>
oozie jobs -jobtype coordinator -oozie <<Ссылка на API Oozie>>
Итог
Таким образом, была решена задача по устранению нежелательных TEZ сессий на кластере. Надеюсь мой опыт окажется полезным, спасибо за внимание!