/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Не так давно я столкнулся с задачей классификации отзывов на сотовые телефоны при помощи стандартных методов машинного обучения. Зачастую отзывы, оставляемые клиентами, слабо структурированы и сформировать мнение о тональности отзыва становится тривиальной задачей. В последнее время методы обработки естественного языка сделали большой скачок и достигли высокой точности в определении тональности отзывов, что нашло применение в маркетинговых целях.
Для решения задачи был рассмотрен корпус из 5000 отзывов на мобильные телефоны. Было принято решение о создании системы классификации, работающей автономно от модуля создания, настройки и тестирования модели машинного обучения – предварительно обученная модель может быть сохранена в файл в виде настроек и затем загружена для решения задачи классификации в режиме реального времени. Поскольку метод опорных векторов является лучшим выбором для небольших объемов данных, был сделан вывод о том, что для использования в качестве модели машинного обучения лучше всего подходит линейный классификатор опорных векторов – метод опорных векторов, который использует линейное ядро для решения задачи классификации.
Текстовые данные (документы в корпусе отзывов на мобильные телефоны) представлены в строковом формате, который не воспринимается моделью машинного обучения. Поэтому для решения задачи необходимо выполнить конвертацию строкового представления в числовое, к которому легко применить алгоритмы машинного обучения.
Одним из самых доступных, но при этом эффективных и распространенных способов обработки текста для представления в виде входного сигнала системы машинного обучения – это так называемый «мешок слов» (англ. bag-of-words). Используя это представление, можно удалить структуру исходного документа (разделы, подразделы, абзацы, предложения, настройки форматирования и т.д.) и посчитать частоту встречаемости каждого слова в каждой точке данных корпуса. Именно эти простые действия позволяют представить исходный текст в виде «мешка слов».
Получение «мешка слов» включает в себя следующие три этапа:
- Токенизация (англ. tokenization). Каждый документ разбивается на слова, которые встречаются в нем (токены), например, с помощью пробелов и знаков пунктуации.
- Построение словаря (англ. vocabulary building). Выполняется занесение в словарь всех слов, которые появляются в каждом из документов, и их упорядочение (как правило, в алфавитном порядке).
- Создание разреженной матрицы (англ. sparse matrix encoding). Для каждого точки данных корпуса выполняется подсчет, насколько часто каждое из слов, занесенных в словарь, встречается в данном документе.
Для построения «мешка слов» в работе была использована Scikit-Learn – это библиотека для Python, впервые разработанная Дэвидом Курнапо в 2007 году. Несмотря на то, что в библиотеке scikit-learn не реализован ни один из способов нормализации, CountVectorizer позволяет задать собственный токенизатор, который преобразует каждый документ в список токенов с помощью параметра tokenizer.
Для избавления от неинформативных слов в работе был использован список стоп-слов русского языка из пакета nltk – ведущей платформы для создания программ на Python для работы с данными на человеческом языке.
Следующий метод вместо исключения несущественных признаков пытается масштабировать признаки в зависимости от степени их информативности. Одним из наиболее распространенных способов такого масштабирования является «частота термина-обратная частота документа» (англ. Term Frequency-Inverse Document Frequency, TF-IDF). Идея этого метода заключается в том, чтобы присвоить большой вес термину, который часто встречается в конкретном документе, но при этом редко встречается в остальных документах корпуса. В библиотеке scikit-learn метод TF-IDF реализован в двух классах: TfidfTransformer, который принимает на вход разреженную матрицу, полученную с помощью CountVectorizer, и преобразует ее, и TfidfVectorizer, который принимает на вход текстовые данные и выполняет как выделение признаков «мешок слов», так и преобразование TF-IDF.
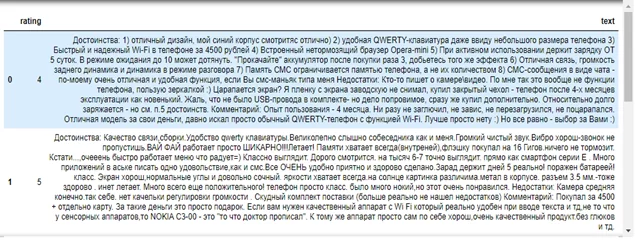
Корпус отзывов на мобильные телефоны представляет собой набор текстов, полученных в результате парсинга с сайта market.yandex.ru и сохраненных в формате *. json. Данные считываются в табличную структуру данных DataFrame библиотеки Pandas для анализа данных. Этот объект представляет собой аналог структуры данных «словарь», в котором ключами выступают заголовки столбцов данных, а значениями – непосредственно столбцы. Пример данных, загруженных в таблицу, приведен на рисунке 1.
Программный код для загрузки данных и вывода заголовка таблицы приведен в листинге 1.
Листинг 1. Загрузка данных в табличной форме
train = pd.read_json('train.json', orient='records', encoding = 'utf-8', lines=True).drop_duplicates()
train.head()
Распределение рейтинга пользователей представлено на рисунке 2.
На рисунке 3 представлен график распределения длин текстов отзывов, полученных от пользователей.
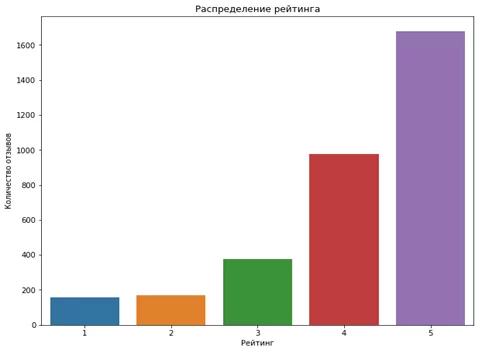
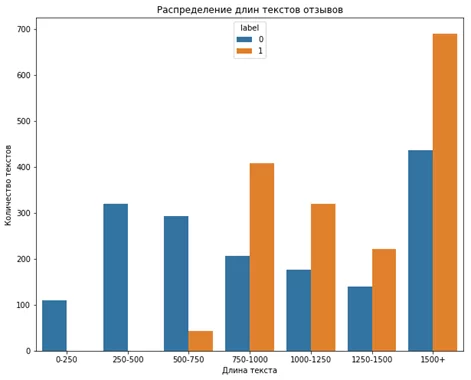
Рисунок 3 – Распределение длин текстов отзывов
Оценки варьируются от 1 до 5, при этом каждый отзыв имеет метку класса – 0 (негативный) или 1 (позитивный), которую необходимо получить для отзыва, заданного пользователем.
Так как целевая переменная не сбалансирована, были выбраны только 1680 самых развернутых положительных отзывов в обучающую выборку.
Каждый отзыв состоит из трех частей – первая содержит описанные достоинства, вторая – недостатки, третья – комментарий. В качестве данных для обучающей выборки из отзыва выделяется содержимое этих составляющих отзыва при помощи регулярных выражений (для этого реализована функция extract_info). Перед этим отзывам назначаются соответствующие их оценкам метки – «1» для отзывов с рейтингом «5» и «0» для остальных отзывов.
В листинге 2 описывается функция создания конвейерной модели, принцип действия которой состоит в последовательном применении трех алгоритмов: векторизации, TF-IDF преобразования и классификации. В качестве классификатора в работе используется линейный классификатор метода опорных векторов.
Листинг 2. Функция построения конвейерной модели
def make_pipeline(vectorizer, transformer, classifier):
return Pipeline([
('vectorizer', vectorizer),
('transformer', transformer),
('classifier', classifier)
])
Перед обучением модели на обучающей выборке был выполнен подбор оптимальных для задачи параметров при помощи метода RandomizedSearchCV. Исходный код функции поиска параметров приведен в листинге 3
Листинг 3. Функция поиска лучших параметров
from sklearn.model_selection import RandomizedSearchCV
def make_estimator(classifier, params_grid, scorer, data, labels):
pipeline = make_pipeline(CountVectorizer(), TfidfTransformer(), classifier)
grid_cv = RandomizedSearchCV(pipeline, params_grid, scoring=scorer, cv=5,
random_state=777, n_iter=100, verbose=1, n_jobs=-1)
grid_cv.fit(data, labels)
return grid_cv
Для настройки параметров были использованы несколько константных значений, которые применялись к каждой из составных частей конвейерной модели. Например, для векторизации выбираются следующие параметры: минимальное значение количества документов, в которых должно появиться слово (1, 10, 20); доля от общего числа документов, в которых будут исключены часто встречающиеся слова (от 0,85 до 1.00); диапазон токенов, которые рассматриваются в качестве признаков (одиночные символы, а также идущие друг за другом пары, тройки и т.д. – юниграммы, биграммы, триграммы и т.д.); а также признак использования списка стоп-слов в выбранном языке (использовать этот список или нет). Соответствующие параметры были выбраны также для объекта класса TfidfTransformer, выполняющего TF-IDF преобразование, и для линейного классификатора метода опорных векторов LinearSVC. В качестве метрики используется accuracy (точность классификации). Также используется кросс-валидация с параметром k = 5.
Результат подбора лучших параметров модели представлен на рисунке 4. Как следует из рисунка 4, точность классификации на тестовой выборке достигла значения 92%.
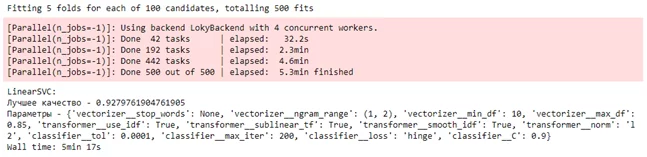
Модель классификации с полученными параметрами также была проверена на обучающей выборке отзывов; точность классификации составила 97%. Параметры этой модели машинного обучения были сохранены в бинарный файл для ее использования в дальнейшем.
Результаты классификации негативного и позитивного отзывов, полученных от пользователя, представлены на рисунках 5 и 6.
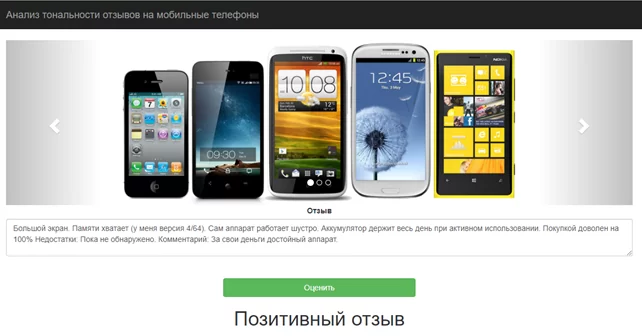
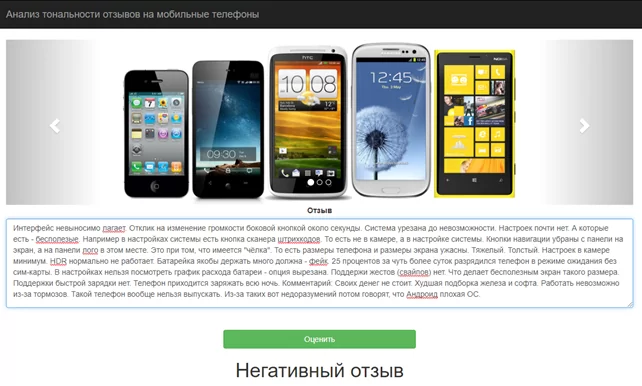
Статистические методы недостаточны для интеллектуального анализа текста. Текстовое представление является важной проблемой. Большая часть литературы дает лишь синтаксическое решение для представления текста. Однако модель представления зависит от семантики той информации, которая нужна. Концептуальная база или семантическое представление документов требуют дополнительных исследований. С добавлением онтологии и семантики для представления документов будет улучшена точность и процесс классификации. Таким образом, выявление признаков, которые захватывают семантический контент, является одной из важных областей для исследований. Общие проблемы множественного обучения зашумленных данных – это чрезвычайно сложная задача, которая только сейчас формулируется и, вероятно, потребует дополнительной работы, чтобы успешно разработать необходимую стратегию.
В целом существуют другие методы классификации текста, такие как Байесовская классификация, pLSA, Многомерная модель, Мултиномиальная модель и т.д. Но классификатор метода опорных векторов был признан одним из наиболее эффективных методов классификации текста при сравнении алгоритмов обучения с учителем. Классификатор лучше отражает характеристики, присущие данным, и встраивает принцип минимизации структурного риска, который позволяет снизить верхнюю границу ошибки в процессе тестирования, а также его способность к обучению может быть независимой от размерности признаков. Именно эта модель машинного обучения была выбрана в качестве основы для реализации системы анализа тональности отзывов на мобильные телефоны. В работе была успешно решена задача бинарной классификации – разработано и протестировано простейшее веб-приложение, которое позволяет определить, негативный или позитивный характер имеет отзыв, введенный в специальную форму пользователем, с точностью в 92%.