/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Необходимо быстро, качественно и в короткие сроки обработать большое количество данных, но у вас нет ни примерного алгоритма для написания своей модели, ни данных для её обучения? Выход есть! Можно использовать предобученные модели трансформеры.
Модели трансформеры (transformers) пришли на смену рекуррентным нейронным сетям, из-за своего специального механизма внимания (self-attention), который позволяет хранить связи между всеми словами в тексте.
Существует множество моделей для решения различных задач, которые находятся в открытом доступе, но как понять, какая модель больше подходит для решения поставленной перед вами задачи?
Передо мной стояла задача провести анализ отзывов пользователей. Это задача сентиментного анализа текста или же задача мультиклассовой классификации, где необходимо отнести текст к одному из этих трёх классов. Основная цель – это найти как можно больше негативных отзывов, чтобы узнать, на что жалуются люди и решить эти проблемы.
Сразу обозначу классы, для дальнейшего анализа:
- 0 – нейтральный;
- 1 – положительный;
- 2 – отрицательный.
Поскольку для решения данной задачи будут использоваться модели трансформеры, необходимо понимать, какая из многих моделей будет подходить для решения поставленной задачи лучше остальных. Потому что от этого напрямую будет зависеть точность полученных результатов и соответственно успех в выполнении задачи.
Загрузка и подготовка датасета к анализу
В качестве данных буду использовать датасет с отзывами пользователей, который я заранее самостоятельно разметил.

#импорт библиотеки pandas для работы с большими данными
import pandas as pd
#убирю ограничения на ширину и длину столбцов
pd.set_option('display.max_columns',None)
pd.set_option('display.max_colwidth',None)
#загружаю датасет
df = pd.read_excel('data.xlsx')В датасете есть два столбца: «Target», в котором содержится метка тональности текста, и «message», где содержится сам текст.
У многих моделей существует ограничение по длине токенов, обычно их длина не должна быть более 512 значений. Но в результате токенизации создаются два дополнительных токена, обозначающие начало и конец предложения в самой модели, поэтому, чтобы не возникало ошибки, количество токенов не должно превышать 510. Чтобы в дальнейшем не возникло с этим проблем уберу все тексты, которые длиннее этого значения.
#делю каждый текст на токены
df['tokens'] = df['message'].apply(lambda x: x.split())
#считаю количество токенов
df['len'] = df['tokens'].apply(lambda x: len(x))
#убираю тексты, длина которых больше 510 токенов
df = df[df['len'] < 510]Чтобы с датафреймом было легче работать, оставлю в нем только нужные мне столбцы, а остальные удалю.
df.drop(columns = [‘date_send’,’sender_role’,’age’,’id_room’, 'tokens', 'len'], inplace = True)Обзор выбранных моделей
В публикации буду сравнивать между собой три модели для сентиментного анализа текста:
- blanchefort/rubert—base—cased—sentiment, которая основана на модели DeepPavlov/rubert-base-cased-conversational, и обучена на таких датасетах как: RuTweetCorp, RuReviews, RuSentiment и отзывах о медучреждениях;
- blanchefort/rubert—base—cased—sentiment—rurewiews, которая, как и первая модель, основана на DeepPavlov/rubert-base-cased-conversational, обучалась только на датасете RuReviews;
- cointegrated/rubert—tiny—sentiment—balanced, которая основана на модели cointegrated/ rubert-tiny, и дообучена на датасете SentiRuEval2016, для сентиментного анализа коротких текстов на русском языке.
Ещё стоит сказать о том, что не все модели одинаково выдают предсказания, например, первые две модели для каждого сообщения будут выдавать такие предсказания как: POSITIVE, NEGATIVE, NEUTRAL. А третья — предсказание в виде цифр 0, 1, 2.
Классификация моделей
Перед загрузкой моделей необходимо импортировать специальные библиотеки для работы с трансформерами.
from transformers import pipeline
from transformers import AutoTokenizer, AutoModelForSequenceClassification
#Загрузка модели трансформера
tokenizer = AutoTokenizer.from_pretrained("blanchefort/rubert-base-cased-sentiment")
model = AutoModelForSequenceClassification.from_pretrained("blanchefort/rubert-base-cased-sentiment")
Напишу функцию, которая будет прогонять значения через пайплайн и возвращать полученные в ходе классификации значения:
def classification(document):
#в пайплайне указывается задача, модель и токенизатор, а top_k = 1 означает, что нужно вывести 1 подходящий класс
classifier = pipeline('text-classification', model = model, tokenizer=tokenizer, top_k = 1)
return classifier(document)
#далее применяю эту функцию к каждому значению из датафрейма
df['pred'] = df['message'].apply(lambda x: classification(x))
В результате в столбце «pred» будут содержаться такие записи.

Теперь необходимо из него вытащить значения лейбла, чтобы остались только названия классов. Сделать это можно с помощью регулярных выражений.
#прохожу по всем значениям столбца «pred» и вытаскиваю всё, что расположено между «label': '» и «', 'score»
df['pred'] = df ['pred'].apply(lambda x: re.findall(r"label': '([\s\S]+?)', 'score", str(x), flags = re.I))
#Поскольку найденные значения пишутся в квадратных скобках, их в итоге тоже необходимо убрать
df ['pred'] = df ['pred'].apply(lambda x: re.sub("[^A-Za-z0-2]", "", str(x)))
В итоге получаю результат, который показан на рисунке ниже

В столбце «pred» и «Target» содержатся предсказанная и заданная заранее метка класса, теперь необходимо произвести заметку меток, на те, что были указаны в начале поста. Поскольку третья модель уже выдает результат в виде 0,1,2, её предсказания менять не нужно.
df['pred'] = df.pred.replace('neutral', 0).replace('positive', 1).replace('negative', 2)
df['Target'] = df.Target.replace('Neutral', 0).replace('Good', 1). replace('Bad', 2)
Чтобы оценить качество работы модели из библиотеки «sklearn» импортирую «classification_report»
from sklearn.metrics import classification_report
#необходимо привести сравниваемые столбцы к числовому формату и задать имена классов
print(classification_report(pd.to_numeric(df[‘Target’]),pd.to_numeric([‘pred’]),target_names = [‘Neutral’,’Positive’,’Negative’]))
Результаты классификации модели blanchefort/rubert-base-cased-sentiment:
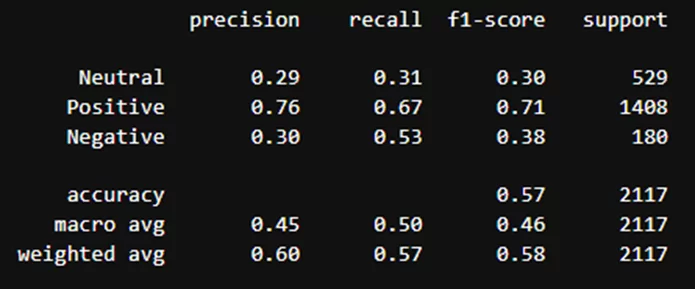
Аналогичные действия провожу для двух оставшихся алгоритмов.
Результаты классификации модели blanchefort/rubert-base-cased-sentiment-rurewiews:
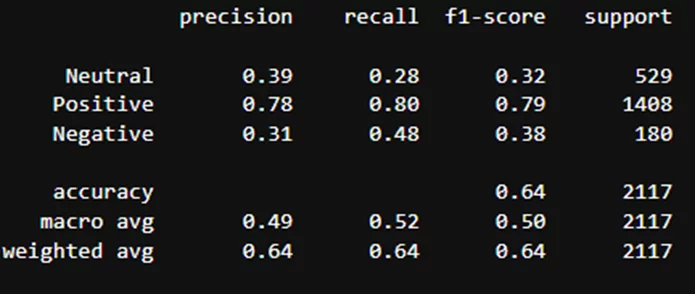
Результаты классификации модели cointegrated/rubert-tiny-sentiment-balanced:
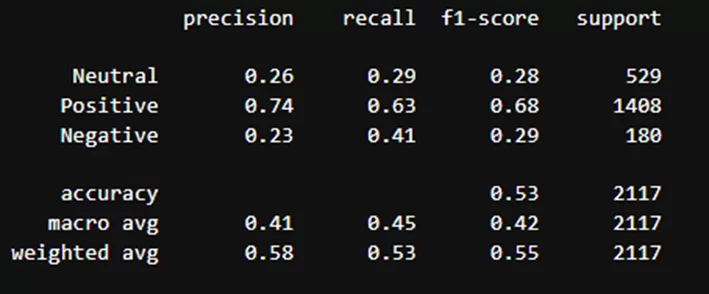
Видно, что модели лучше всего определили только положительные отзывы. Причина – датасет не сбалансирован, на что указывают данные в столбце «support»: положительных отзывов существенно больше.
Классификация моделей на сбалансированном датасете
Сбалансирую датасет и посмотрю, улучшатся ли результаты классификации.
Для этого разделю датасет на три части и в каждую выведу одинаковое количество значений каждого класса. По-другому сбалансировать датасет невозможно, поскольку векторное представление текста происходит внутри модели.
df1 = df[df ['Target'] == 0]
df1 = df1[:180]
df2 = df [df ['Target'] == 1]
df2 = df2[:180]
df3 = df [df ['Target'] == 2]
df3 = df3[:180]
#Теперь объединю их в один датафрейм
new_df = pd.concat([df1, df2, df3], ignore_index=True)Результаты классификации модели blanchefort/rubert-base-cased-sentiment:
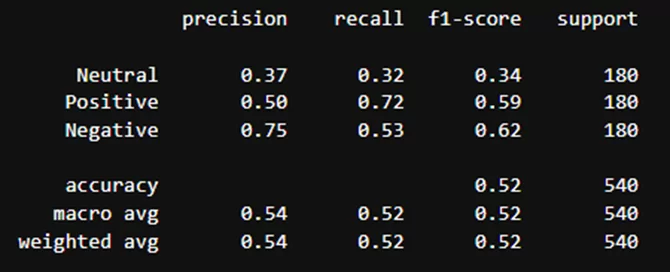
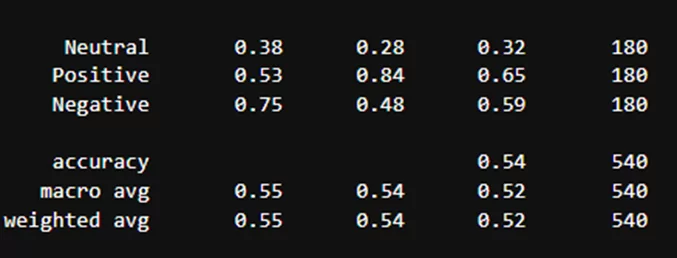
Результаты классификации модели blanchefort/rubert-base-cased-sentiment-rurewiews:
Результаты классификации модели cointegrated/rubert-tiny-sentiment-balanced:
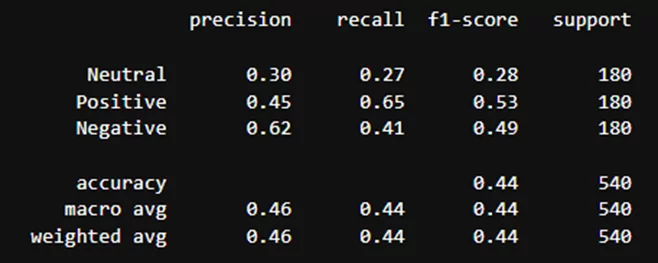
Как можно заметить, балансирование датасета также немного сбалансировало метрики. Поэтому для итогового вывода буду использовать метрики, полученные на сбалансированном датасете:
- precision (точность) – дает информацию о том, что доля объектов, названными классификатором положительными, при этом действительно являются положительными;
- recall (полнота) – дает информацию о том, какую долю объектов положительного класса из всех объектов положительного класса нашла модель;
- f1 – score – дает информацию балансе между precision и recall;
- accuracy – дает информацию об отношении правильных ответов ко всем
Итоговая таблица с результатами
Для моей задачи наиболее важна такая метрика как f1( score), поскольку мне необходимо найти как можно больше отрицательных отзывов, и мы должны быть уверены, что отзыв является отрицательным, чтобы успешно устранить проблемы, на которые жалуются клиенты, именно поэтому важно, чтобы соблюдался баланс между recall и precision.
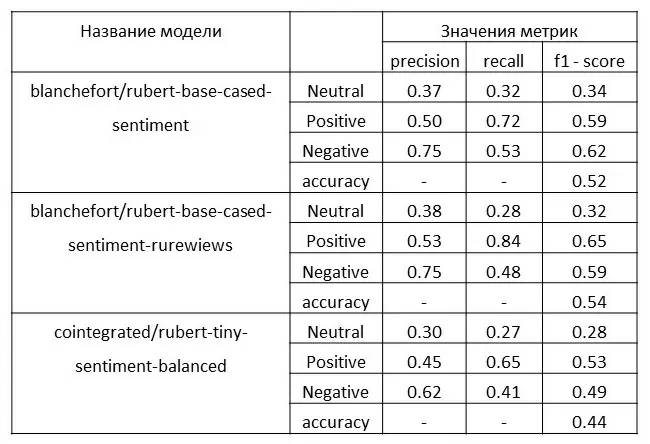
Максимальную точность дает модель blanchefort/ rubert-base-cased-sentiment-rurewiews,модельblanchefort/rubert-base-cased-sentiment показала результат немногим хуже. Это обусловлено одной и той же моделью, взятой за основу, но метрики у blanchefort/ rubert-base-cased-sentiment-rurewiews лучше, потому что она обучалась на специализированном датасете с различными отзывами, blanchefort/rubert-base-cased-sentiment же более универсальна, поскольку обучалась на большом количестве различных датасетов. Хуже всего показала себя модель cointegrated/rubert-tiny-sentiment-balanced, что неудивительно, поскольку она была обучена для работы с короткими текстами, а отзывы в большинстве своём имеют большую длину.
Из всего вышесказанного делаю вывод, что наиболее подходящая для моей задачи модель – это blanchefort/ rubert-base-cased-sйentiment-rurewiews.
Метрики модели зависят от того, на какой модели она основана, на каких датасетах обучалась и для данных какой длины она предназначена. Конечно же это не всё, но основное, поскольку всю эту информацию найти гораздо быстрее, чем, например, настраивать гиперпараметры самой модели и заново её обучать.
Также следует обратить внимание на то, для какой задачи и для какого языка обучалась модель, поскольку очевидно, что модель для поиска и выделения именованных сущностей не справится с задачей классификации текста. А модель, которая обучалась на многих языках, будет показывать результаты хуже, чем модель, которую тренировали на одном языке.
В результате можно быстро и без особых проблем найти подходящую под вашу конкретную задачу модель и быть уверенным, что она хорошо справится с ней. Также можно улучшить качество работы модели, дообучив её на своих специфичных данных, после чего она покажет ещё большую точность. Про дообучение моделей трансформеров можно почитать здесь или в этой статье. Полный код статьи можно найти на github.