/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
В своей работе я использую несколько серверов (MSSQL и ORACLE), на которых живет большое количество баз. Аудит этих серверов — стандартный , то есть можно посмотреть кто, когда, из-под какого приложения и какой запрос к какой базе отправил.
Учетные записи глобально делятся на два типа:
- Пользовательские: из-под них обычные пользователи баз (аналитики, DS, DE) отправляют запросы на разовые выгрузки,
- Технические: под ними запускаются регулярные выгрузки, обычно это бывает для отчетов и наполнения баз.
Иногда обычные пользователи «безобразничают» и начинают отправлять свои запросы из-под технических учетных записей. Так как учетки такого типа выдаются под задачу на команду, доступ к ней может быть у многих участников спринта. Отправление запросов, которые раскрывают персональные данные, из-под такой учетной записи – гарантия определенного уровня анонимности автора. Необходимо поймать хулиганов, и фактически единственный инструмент в проводимом расследовании — текст запросов.
Подход:
Подозрение, что такая проблема действительно существует было подкреплено несколькими реальными случаями, которые выявили админы. Из текста некоторых запросов читается, что запрос написан пользователем: он как правило селективный и содержит перечисляемые вручную параметры, без объявления переменных, циклов и прочего (или содержит персональные данные). Была поставлена задача автоматизации поиска нарушителей, для ее решения я обратилась к средствам машинного обучения. Глобально поделила на две задачи: поиск аномалий и поиск ФИО в запросах.
Модель для поиска аномалий:
Так как запросов от пользователей не может быть больше автоматических, они не будут формировать основную массу запросов. Скорее всего это будут какие-то редкие, аномальные запросы для общего контекста. Поэтому нужно было найти модель, которая сможет находить именно «НЕестественные» для общего фона формулировки. Также надо было учитывать, что обучаться не на чем. Запросов много, они приходя от разных людей и охватить все многообразие просто невозможно. Я использовала модель Local Outlier Factor.
Коротко о принципе работы:
Метод имеет достаточно много общего с кластеризацией DBSCAN, но во внимание принимается локальная плотность наблюдений из N соседей.
Путем сравнения локальной плотности объекта с локальной плотностью его соседей, можно выделить области с аналогичной плотностью, а также точки, которые имеют существенно меньшую плотность, чем её соседи. Эти точки считаются выбросами.
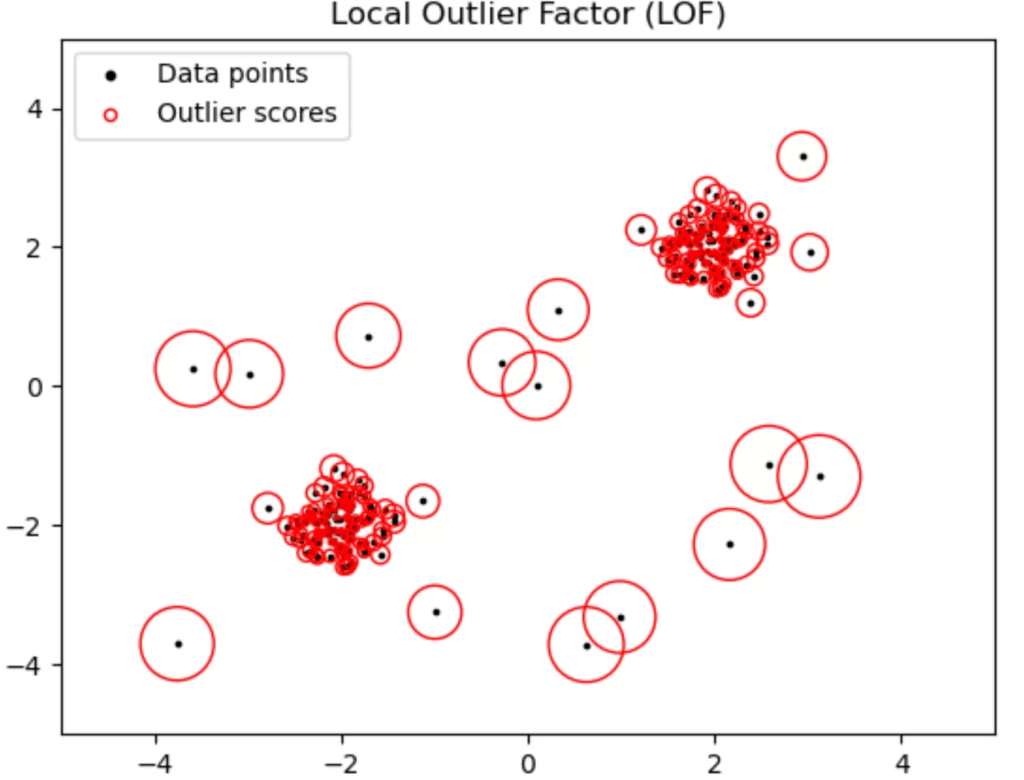
Реализация метода (Local Outlier Factor) есть в библиотеке sklearn на python —
sklearn.neighbors.LocalOutlierFactorИтогом работы является мера непохожести на нормальное наблюдение конкретной точки. Так, как видно из рисунка, более удаленные точки от плотных скоплений обладают более высоким значением «аномальности».
Для того, чтобы использовать этот подход, я провела стандартную работу с текстом запросов:
- Очистила от символов переноса и табуляции: \n, \t,
- Разделила на токены: для ORACLE это было достаточно просто, но для MSSQL ввиду синтаксиса сделала дополнительные деления по точкам и скобкам, чтобы отделить все объекты,
- С помощью CountVectorizer (из того же sklearn) перевела все запросы в векторы, чтобы можно было считать между ними расстояния.
Метод предоставляет очень гибкую настройку параметров. Можно указать:
- n_neighbors: количество соседей для определения локальной плотности, по дефолту равно 20, но если значение параметра превышает количество наблюдений, то будут использоваться все наблюдения для сравнений,
- metric: тип расстояния, который будет рассчитан для наблюдений. Выбор типа расстояния зависит от типа данных, так как я работала с текстовыми — остановилась на cosine (косинусная мера) и потестировала еще hammingdistance (сколько необходимо сделать замен внутри текста, чтобы достичь полного совпадения),
- contamination: предполагаемая пропорция аномалий в выборке, выражается долей [0,1].
Пример реализации метода:
import numpy as np
from sklearn.neighbors import LocalOutlierFactor
X = [[-1.1], [0.2], [101.1], [0.3]]
clf = LocalOutlierFactor(n_neighbors=2)
clf.fit_predict(X)
>>> array([ 1, 1, -1, 1])
clf.negative_outlier_factor_
>>> array([ -0.9821..., -1.0370..., -73.3697..., -0.9821...])
Как искала персональные данные:
Чтобы найти имена — использовала библиотеку natasha. Выбор пал на этот инструмент из-за скорости обработки, а также из-за того, что можно подавать любые по размеру последовательности на вход. В DeepPavlov есть ner, который может определить наличие имени, но на вход может принять последовательность не более 512 символов.
from natasha import NamesExtractor, MorphVocab
morph_vocab = MorphVocab()
extractor = NamesExtractor(morph_vocab)
def extract_name(string):
matches = extractor(string)
names = [_.fact for _ in matches if _.fact.first and _.fact.last and _.fact.middle]
return ' '.join([n.last + n.first + n.middle for n in names])
Запуск на регулярной основе:
Так как мониторинг должен проходить непрерывно, то нужно было регулярно запускать обработку. Для формирования контекста я использовала выгрузки всех запросов за неделю, а исполнение кода поставила на cron, так как для отработки использовали linux – сервер.
Чтобы запустить крон, нужно выполнить следующие команды:
crontab -e
i
После исполнения первой команды попадаете в редактор VIM, чтобы внести изменения нужно нажать i (insert). Далее надо заполнить шаблон, суть которого легко запомнить:
* * * * * Команда, которая будет выполнена
- - - - -
| | | | |
| | | | - День недели (0 - 7) (воскресенье = 0 или 7)
| | | --- Месяц (1 - 12)
| | --- День месяца (1 - 31)
| ---- Час (0 - 23)
----- Минута (0 - 59)
Если нужно выполнить две команды (активировать виртуальное окружение и запустить скрипт), то записать их нужно через знак операнда следующим образом:
* * * * * source home/user/folder/venv/activate && python home/user/folder/file_to_run.pyЗатем нужно сохранить изменения, которые внесены, нажать escape и ввести: wq
Резюмирую:
Так как поиск аномалий осуществляется на основе контекста, то при условии его неверного формирования, результат также может быть неверным.
В то же время, возможность провести разметку в этой задаче отсутствует, потому что разнообразие запросов просто не позволит перебрать все возможные типы запросов, которые «достают» персональные данные.
Улучшить используемый подход можно настройкой гипер-параметров, принимая во внимание особенности написания запросов.