/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 9 мин.
В рамках данной публикации я постарался не только поделиться своим практическим опытом решения аналитической задачи, но и уделить внимание профессиональным особенностям, связанным и с софт-скиллами, так как глубоко убеждён, что когнитивные умения в работе не менее важны, чем умение использовать тот или иной инструмент.
Постановка и понимание задачи
Своевременное и качественное выполнение поставленных задач может отличать успешный бизнес от неуспешного. Однако, та же успешность выполнения задачи зачастую прямым образом зависит от того, насколько прозрачно дошла её постановка от источника до исполнителя. Поясню на основе простейшего принципа: «делать не значит сделать». Идея практически любой задачи представлена концепцией из трёх шагов:
- Субъект А ставит задачу;
- Субъект Б её выполняет;
- Субъект А оценивает результат её выполнения.
Но на самом деле, в большинстве случаев, отношения вышеупомянутых субъектов продолжаются гораздо дольше и, в лучшем случае, на основе хорошего опыта от взаимной работы, а в худшем (и самом реалистичном), Субъект А будет постоянно отправлять замечания с требованиями переделать выполненную задачу Субъекту Б, а он в свою очередь, переделывать и отправлять обратно до тех пор, пока не будет достигнуто взаимное понимание или, пока отношения не расстроятся окончательно.
Природа такого происшествия интуитивно понятна: люди по-разному смотрят на одну и ту же задачу. Причины могут быть разные, вероятно, постановщик задачи слишком сильно акцентируется на своём видении того, что он хочет, а не на конкретной проблеме, которую необходимо решить. Но с той же вероятностью исполнитель задачи может сделать не то, потому что изначально увидел постановку проблемы отличной от конкретной. И все это нормально.

Итак, я определился, с ролью правильного понимания и постановки задачи на старте её решения, и с должной ответственностью можем приступать к знакомству с задачей. Запрос от бизнеса был таков: «Выяснить, почему похожие клиенты приносят разное количество прибыли». С виду задача сформулирована довольно понятно и вроде сходу в голове представляется, как может выглядеть конечный вывод по задаче! Но стоит только задуматься о погружении в практику процессов взаимодействия с заказчиком или практического решения для бизнеса и появляются вопросы:
- Насколько сложное технически должно быть решение, чтобы эффективно интерпретировать его заказчику?
- Каким образом будет оцениваться результат исследования?
- Позволяют ли возможности заказчика реализовать потенциальное решение?
- В каком виде заказчик ожидает результат решения задачи?
По идее, эти вещи чуть тоньше, чем видится постановка задачи самим заказчиком или попросту он может о них даже не задумываться и не разбираться. И за это ни одного заказчика нельзя винить – у каждого своя работа и своя ответственность. Самое лучшее что можно сделать на месте исполнителя — это сформировать оставшиеся непрозрачными вопросы и ДО начала осуществления решения прояснить вместе с заказчиком все эти моменты. Те, кто опрометчиво брал на себя ответственность «подумать обо всем», представляют какое количество часов, сил и нервов можно было бы сэкономить всем участникам процесса просто назначив «обсуждение на берегу» между исполнителем и заказчиком в необходимый момент.
Вернусь к задаче. Данные, которые можно собрать, позволяют разделить пользователей по группам и, на основе объективных скрытых и явных зависимостей, составить стандартное поведение представителя каждой группы. Получится этакий «портрет» клиента. Это поможет проранжировать значимость клиентов и их продуктов и сформировать потенциальное решение. Начну с изучения данных.
Изучение и подготовка данных
Использовать буду подходящие средства для работы с данными: Python и Jupyter Notebook.
Библиотеки, которые понадобятся для решения задачи:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler, normalize
from IPython.display import Markdown
Загружаю данные, указав признак даты:
df = pd.read_csv(‘data.csv’, parse_dates=['mon'])
И теперь взгляну на базовую статистику по выгрузке:
display(df.info())
display(df.corr())
display(df.shape)
display(df.describe())
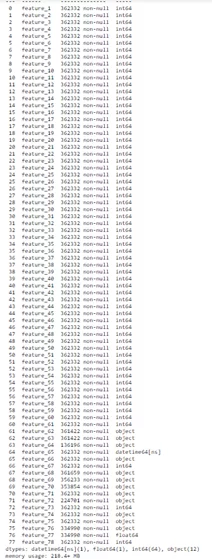
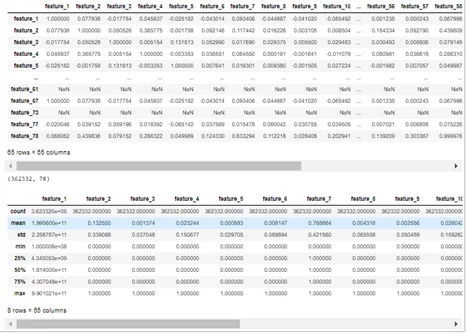
В рамках данной задачи не буду извлекать признаки, оттолкнусь от того, что есть. В данном случае, очистка данных представляет собой только удаление от неинформативных признаков (признаки, где все значения – это нули и признаки со слишком большим количеством пропусков), удаления десятков строк с пропущенными значениями, а также удаления не интерпретируемых признаков. Сделаю это и перемещусь к более интересным вещам.
Кластеризация – это класс задач машинного обучения без учителя, чтобы математически и логически корректно «отдать» модели данные, необходимо провести с ними некоторые преобразования. Все эти преобразования оберну в функцию с пояснением:
# Стандартизация, one-hot кодирование, нормализация, PCA-преобразование
def preproces(df):
num_cols = df.select_dtypes(exclude=['object']).columns.tolist()
num_transform = StandardScaler()
num_scaled = num_transform.fit_transform(df[num_cols])
df[num_cols] = num_scaled
cat_cols = df.select_dtypes(include=['object']).columns.tolist()
ohe = pd.get_dummies(df[cat_cols])
df = df.drop(cat_cols, axis=1)
df = df.join(ohe)
df = normalize(df)
df = pd.DataFrame(df)
pca = PCA(n_components=2)
df = pca.fit_transform(df)
df = pd.DataFrame(df)
df.columns = ['PCA1', 'PCA2']
return df
Для начала, с помощью метода StandardScaler, стандартизирую данные, то есть приведу к единой дисперсии. Сделать это необходимо, чтобы количественные признаки не имели для модели повышенную значимость над категориальными. Она должна понимать, что значение полученного дохода, измеряемое тысячами и миллионами, не важнее признака пола, принимающего значение, например, 0 или 1. Дальше, применю процедуру OneHot-кодирования, призванную для преобразования в целочисленный вид признаков с текстовыми данными. Таким образом, тот же признак пола будет вместо вида «муж» представлен как 1, «жен» как 0 соответственно.
Практически готовые данные приведу к единому масштабу путем нормализации. Очень важной процедурой в рамках предобработки будет являться понижение размерности. Данные имеют большое количество признаков, с которыми модели будет сложно работать, и которые можно обобщить, путем понижения размерности. Как это сделать? С помощью PCA (анализ главных компонент), повышу интерпретируемость данных для модели, с минимальной потерей информативности. Все рассматриваемые признаки обобщу до двух, чтобы можно было доступно представить данные на визуализации в двухмерном пространстве. В итоге предобработанные данные имеют следующий вид:
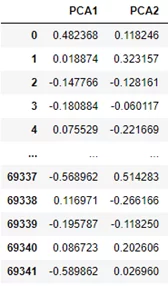
Выбор алгоритма
Одним из самых интересных этапов исследования является выбор подходящего алгоритма. Дело в том, что идея разделения на кластеры понятна: поделить все объекты на группы по схожести так, чтобы была ясна разница между ними. Однако, если разобраться в математической концепции расчёта схожести между объектами разных алгоритмов, отталкиваясь от конкретных данных, конечно, то ясно будет только одно – всё не так просто. Идея наглядна на довольно популярной картинке:
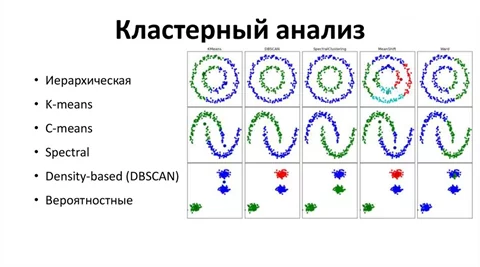
Пояснять как работает каждый отдельный алгоритм в посте не буду, благо, актуальный материал очень хорошо гуглится. Кратко выделю только то, что одни алгоритмы работают по иерархическому принципу, то есть каждому объекту присваивают собственный кластер, и затем объединяют два ближайших до тех пор, пока не образуется общий. Другие обобщают на основе расстояний к центральным точкам кластеров – центройдам. Необходим алгоритм, который будет подходить к данным, взгляну на их визуальное представление:
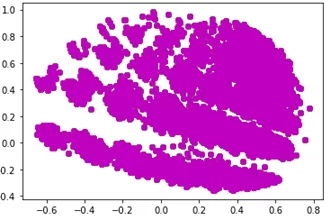
В двумерном пространстве, которое я определил, понизив размерность, данным характерна очень высокая плотность. Согласитесь, что алгоритмы, призванные отлавливать схожесть в данных следующего вида, вряд ли логично применять в данном случае:
Поверьте, к таким данным, даже подобрать предварительное число кластеров представится не таким очевидным. Отличным кандидатом на место в инструментарии моего исследования будет алгоритм «плотностной кластеризации» DBSCAN (Density-Based Spatial Clustering of Applications with Noise)! Он не требует на вход предварительного числа кластеров и хорошо работает с шумами. Интуитивная идея алгоритма такова: если несколько людей общаются друг с другом и находятся достаточно близко, то они образовывают компанию. Это логично, и неважно, что вокруг может быть сколько угодно подобных компаний или компаний из одного человека – схожесть зафиксирована. Основными параметрами алгоритма являются: максимальное расстояние между соседними точками (eps) и минимальное количество объектов в кластере (min_samples).
Применение и выводы
Возьму необходимую выборку и применю алгоритм:
def dbscan_clusters(df, min_samples):
db_default = DBSCAN(eps=0.0375, min_samples=min_samples).fit(df)
df['db_cluster'] = db_default.labels_
return df
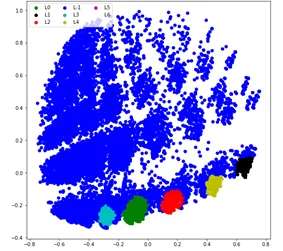
Если постараться, то какие-то выводы всё-таки можно сделать, но без конкретных цифр смысла решительно немного. Для того чтобы интерпретировать результат работы алгоритма, выведем статистику по каждому полученному кластеру, и эта статистка будет отражать среднестатистического пользователя-объекта соответствующей группы:
def description_seg(df, name):
display(Markdown(f'\n**Портрет клиента в группе {name}**\n'))
display(Markdown('\n***Средний доход:***\n'))
display(round(df['feature_34'].mean(), 2))
display(Markdown('\n***Среднее количество продуктов:***\n'))
display(round(df[‘feature_43’].mean(), 2))
display(Markdown('\n***Среднее количество продуктов группы 1:***\n'))
display(round(df[‘feature_54'].mean(), 2))
display(Markdown('\n***Топ отраслей:***\n'))
display(df['feature_23'].value_counts().head())
Соберу вывод в таблицу:
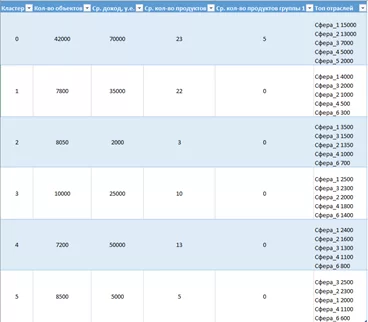
**прим. Данные умышленно изменены без потери сути.
Теперь, как минимум, «синее пятно» стало осмысленнее, а самое главное – появилась возможность анализировать! Уже можно выделить, к примеру, группы 1 и 2, участники которых схожи по большинству признаков, однако одни приносят доход, а другие нет. Почему так? Судя по всему, что-то «недопредложили», а может где-то отдел продаж работает не так добросовестно? Самое главное – подсвечена проблема и наглядно показаны закономерности. Изначальная задача исследования выполнена, а дальше эти данные ждёт более детальный разбор с формированием практических решений.
Итог
Возможности кластерного анализа на самом деле далеко не ограничиваются применением, изложенным в публикации. Метод является очень гибким в плане использования в различных сферах и не менее полезным. Приведу несколько примеров из практики:
Анализ можно использовать в сфере кадров, он может помочь увидеть более объективную картину рынка кадров и строить стратегию подбора.
Также, в сфере страхования кластеризация может дать актуальную информацию (средний возраст, количество заболевании и т.д.) и, исходя из этого, формировать бизнес-политику.
Наконец, крайне успешно кластерный анализ применяется в исследованиях, связанных с социологией.
Сфер применения ещё больше, потому что анализ можно применять практически в любом случае, где данные нужно систематизировать и структурировать, но не стоит забывать об идеологической стороне исследования, ведь сделать можно любой анализ, суть в том, чтобы понимать и осознавать его практический смысл и пользу для бизнеса.