/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 10 мин.
Сегментация клиентов – это практика разделения клиентов на группы, которые отражают сходство между клиентами в каждом кластере. Я разделю клиентов на сегменты, чтобы оптимизировать значимость каждого клиента для бизнеса. Это помогает модифицировать продукты в соответствии с четко определёнными потребностями и поведением клиентов. Кроме того, это помогает бизнесу удовлетворять потребности различных типов клиентов.
Импортируем библиотеки, которые будут нужны для решения задачи:
import matplotlib
import datetime
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import colors
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
from sklearn.cluster import KMeans
from sklearn import metrics
from sklearn.cluster import AgglomerativeClustering
from yellowbrick.cluster import KElbowVisualizer
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt, numpy as np
from mpl_toolkits.mplot3d import Axes3D
import sys
import warnings
if not sys.warnoptions:
warnings.simplefilter("ignore")
np.random.seed(42)
Загружаем датасет для анализа:
#Загружаем данные
data = pd.read_csv("…./mark_camp.csv", sep="\t")
print("Количество данных в наборе:", len(data))
data.head()
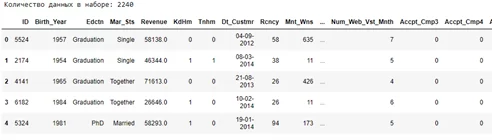
Займемся очисткой данных. Взглянем на информацию, содержащуюся в данных, для того, чтобы понять, что нужно для их очистки.
data.info()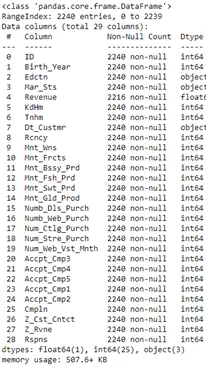
Из использованной выше функции можно отметить, что:
- В доходах присутствуют недостающие значения
- Dt_Customer, который указывает дату, когда клиент появился в базе данных,не анализируется как дата и время
- В нашем фрейме данных есть некоторые категориальные функции; так же, как есть некоторые функции dtype: object). Поэтому позже нам нужно будет закодировать их в числовые формы.
Прежде всего, для отсутствующих значений я просто удалю строки, в которых отсутствуют значения дохода.
data = data.dropna()
print("Общее количество точек данных после удаления строк с пропущенными значениями составляет:", len(data))
Вывод функции:
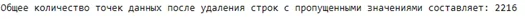
Следующим шагом, я создам функцию из «Dt_custmr», которая указывает количество дней, в течение которых клиент зарегистрирован в базе данных фирмы. Однако, чтобы упростить задачу, я беру это значение относительно последнего клиента в записи.
Таким образом, чтобы получить значения, я должен проверить самые новые и самые старые записанные даты.
data["Dt_Custmr"] = pd.to_datetime(data["Dt_Custmr"])
dates = []
for i in data["Dt_Custmr"]:
i = i.date()
dates.append(i)
#Dates of the newest and oldest recorded customer
print("Дата регистрации последнего клиента в записях:",max(dates))
print("Самая старая дата регистрации клиента в записях:",min(dates))
Вывод функции:

Создание функции («Cust_f») количества дней, в течение которых клиенты начали совершать покупки в магазине, относительно последней зарегистрированной даты.
#Создаем колонку "Cust_F"
days = []
d1 = max(dates) #принимаем за нового клиента
for i in dates:
delta = d1 - i
days.append(delta)
data["Cust_F"] = days
data["Cust_F"] = pd.to_numeric(data["Cust_F"], errors="coerce")
Теперь мы рассмотрим уникальные значения в категориальных функциях, чтобы получить четкое представление о данных.
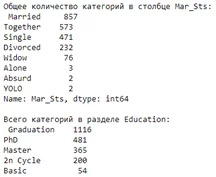
print("Общее количество категорий в столбце Mar_Sts:\n", data["Mar_Sts"].value_counts(), "\n")
print("Всего категорий в разделе Education:\n", data["Edctn"].value_counts())
Вывод функций, написанных выше:
Далее выполним следующие шаги для разработки некоторых новых функций:
- Извлечем «Age» клиента по «Birth_Year», указав год рождения соответствующего лица.
- Создадим еще одну колонку «Spent», указывающую общую сумму, потраченную клиентом, в различных категориях, в течение двух лет.
- Создадим колонку «Living_with» из «Mar_sts», чтобы извлечь семейное положение пар.
- Создадим колонку «Children», чтобы указать общее количество детей в семье.
- Чтобы иметь понимание о количестве членов семьи, создадим колонку «Family_size».
- Создадим колонку «Is_parent», чтобы указать статус родителя.
- Предпоследним пунктом создадим три категории, в разделе «Education», для упрощения подсчета его стоимости.
- Удалим лишние колонки.
#Разработка функций
#Возраст клиента сегодня
data["Age"] = 2021-data["Birth_Year"]
#Общие расходы на различные предметы
data["Spent"] = data["Mnt_Wns"]+ data["Mnt_Frcts"]+ data["Mnt_Bssy_Prd"]+ data["Mnt_Fsh_Prd"]+ data["Mnt_Swt_Prd"]
+ data["Mnt_Gld_Prod"]
#Определение жизненного положения по семейному положению "Alone"
data["Living_With"]=data["Mar_Sts"].replace({"Married":"Partner", "Together":"Partner", "Absurd":"Alone",
"Widow":"Alone", "YOLO":"Alone", "Divorced":"Alone", "Single":"Alone",})
#Характеристика, указывающая общее количество детей, проживающих в домохозяйстве
data["Children"]=data["KdHm"]+data["Tnhm"]
#Характеристика для всех членов домохозяйства
data["Family_Size"] = data["Living_With"].replace({"Alone": 1, "Partner":2})+ data["Children"]
#Особенность относящаяся к статусу родителей
data["Is_Parent"] = np.where(data.Children> 0, 1, 0)
#Разделение уровней образования на три группы
data["Edctn"]=data["Edctn"].replace({"Basic":"Undergraduate","2n Cycle":"Undergraduate", "Graduation":"Graduate",
"Master":"Postgraduate", "PhD":"Postgraduate"})
#Для ясности
data=data.rename(columns={"Mnt_Wns": "Wines","Mnt_Frcts":"Fruits","Mnt_Bssy_Prd":"Meat","Mnt_Fsh_Prd":"Fish",
"Mnt_Swt_Prd":"Sweets","Mnt_Gld_Prod":"Gold"})
#Удаление некоторых избыточных функций
to_drop = ["Mar_Sts", "Dt_Custmr", "Z_Cst_Cntct", "Z_Rvne", "Birth_Year", "ID"]
data = data.drop(to_drop, axis=1)
Теперь, когда у нас появились новые колонки, взглянем на данные еще раз:
data.describe()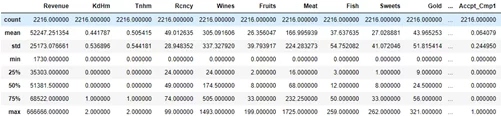
В этой задаче существует множество факторов, на основе которых будет сделана окончательная классификация. Эти факторы в основном являются атрибутами или особенностями, но чем больше количество колонок, тем сложнее с ними работать. Многие из этих столбцов взаимосвязаны и, следовательно, избыточны. Поэтому будем выполнять уменьшение размерности выбранных объектов, прежде чем пропускать их через классификатор. Уменьшение размерности – это процесс уменьшения числа рассматриваемых случайных величин путем получения набора основных переменных.
Анализ компонентов (Principal component analysis (PCA)) – это метод уменьшения размерности таких наборов данных, повышения интерпретируемости, но в то же время минимизации потерь информации.
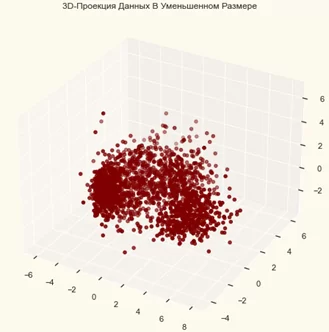
Для этого проекта уменьшим размеры до 3.
pca = PCA(n_components=3)
pca.fit(scaled_ds)
PCA_ds = pd.DataFrame(pca.transform(scaled_ds), columns=(["column1","column2", "column3"]))
PCA_ds.describe().T

#3D-Проекция данных в уменьшенном размере
x =PCA_ds["column1"]
y =PCA_ds["column2"]
z =PCA_ds["column3"]
#Построение
figure = plt.figure(figsize=(10,8))
at = figure.add_subplot(111, projection="3d")
at.scatter(x,y,z, c="maroon", marker="o" )
at.set_title("3D-Проекция Данных В Уменьшенном Размере")
plt.show()
Теперь, когда мы сократили атрибуты до трех измерений, будем выполнять кластеризацию, а именно агломерационную кластеризацию. Агломеративная кластеризация – это метод иерархической кластеризации, он включает в себя объединение примеров до тех пор, пока не будет достигнуто желаемое количество кластеров.
Шаги, связанные с кластеризацией:
- Метод локтя для определения количества кластеров, которые должны быть сформированы;
- Кластеризация с помощью агломерационной кластеризации;
- Изучение кластеров, сформированных с помощью точечной диаграммы.
#метод локтя, чтобы найти количество кластеров для создания.
print('Метод локтя для определения количества кластеров, которые должны быть сформированы:')
Elbow_M = KElbowVisualizer(KMeans(), k=10)
Elbow_M.fit(PCA_ds)
Elbow_M.show()
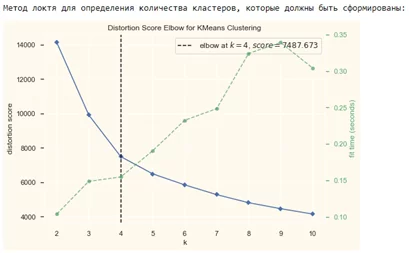
По приведенному выше графику, можно сделать вывод, что 4 будет оптимальным количеством кластеров для этих данных. Далее мы будем подгонять модель агломерационной кластеризации, чтобы получить окончательное количество кластеров.
Для этого проекта уменьшим размеры до 3.
#Инициирование модели агломеративной кластеризации
AC = AgglomerativeClustering(n_clusters=4)
#подгонка модели и прогнозирование кластеров
yhat_AC = AC.fit_predict(PCA_ds)
PCA_ds["Clusters"] = yhat_AC
#Добавление функции кластеров в исходный фрейм данных
data["Clusters"]= yhat_AC
Чтобы изучить сформированные кластеры, давайте взглянем на трехмерное распределение кластеров.
#Построение графиков кластеров
fig = plt.figure(figsize=(10,8))
ax = plt.subplot(111, projection='3d', label="bla")
ax.scatter(x, y, z, s=40, c=PCA_ds["Clusters"], marker='o', cmap = cmap )
ax.set_title("Построение кластеров")
plt.show()
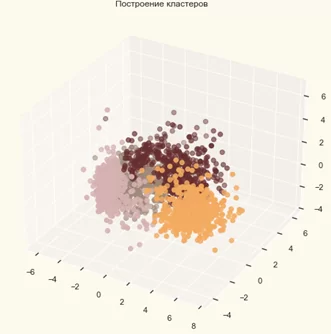
Так как это неконтролируемая кластеризация у нас нет помеченной функции для оценки нашей модели. Цель этой части статьи – изучить закономерности в сформированных кластерах и определить природу закономерностей кластеров.
Для этого рассмотрим данные в свете кластеров с помощью исследовательского анализа данных и сделаем выводы.
Во-первых, взглянем на групповое распределение кластеризации.
#Построение графика подсчета кластеров
pal = ["#682F2F","#B9C0C9", "#9F8A78","#F3AB60"]
pl = sns.countplot(x=data["Clusters"], palette= pal)
pl.set_title("Распределение Кластеров")
plt.show()
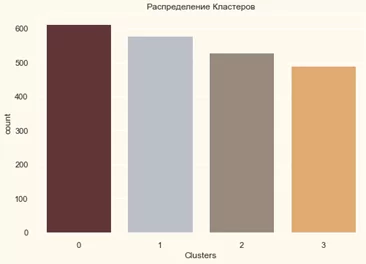
Кластеры, как мы можем увидеть, распределены довольно равномерно.
pl = sns.scatterplot(data = data,x=data["Spent"], y=data["Revenue"],hue=data["Clusters"], palette= pal)
pl.set_title("Профиль Кластера, Основанный На Доходах И Расходах")
plt.legend()
plt.show()
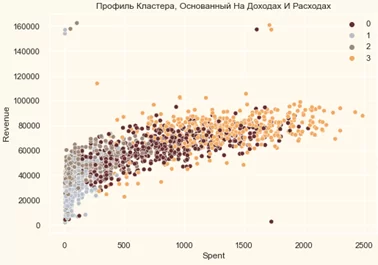
График соотношения доходов и расходов, показывает структуру кластеров
группа 0: высокие расходы и средний доход
группа 1: высокие расходы и высокий доход
группа 2: низкие расходы и низкий доход
группа 3: высокие расходы и низкий доход
Далее я рассмотрю подробное распределение кластеров в соответствии с различными продуктами в данных. А именно: вина, фрукты, мясо, рыба, сладости и золото.
plt.figure()
pls=sns.swarmplot(x=data["Clusters"], y=data["Spent"], color= "#CBEDDD", alpha=0.5 )
pls=sns.boxenplot(x=data["Clusters"], y=data["Spent"], palette=pal)
plt.show()
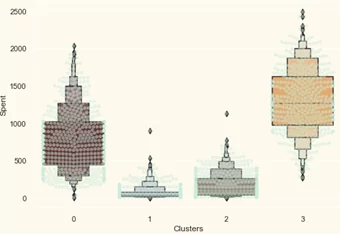
Из приведенного выше графика ясно видно, что кластер 1 – это наш самый большой объем клиентов, за которым следует кластер 0. Мы можем изучить на что тратится каждый кластер для целевых маркетинговых стратегий.
Теперь давайте рассмотрим, как проходили наши компании в прошлом.
#Создание функции для получения суммы принятых рекламных акций
data["Total_Promos"] = data["Accpt_Cmp1"]+ data["Accpt_Cmp2"]+ data["Accpt_Cmp3"]+ data["Accpt_Cmp4"]+ data["Accpt_Cmp5"]
#График подсчета общего количества принятых кампаний
plt.figure()
pls = sns.countplot(x=data["Total_Promos"],hue=data["Clusters"], palette= pal)
pls.set_title("Количество Принятых Поощрений")
pls.set_xlabel("Общее Количество Принятых Рекламных Акций")
plt.show()
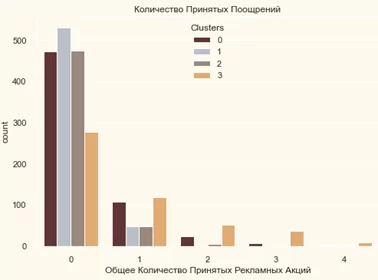
До сих пор не было подавляющего отклика на эти кампании, в целом очень мало участников. Более того, никто не принимает участия во всех 5 из них. Возможно, для увеличения продаж требуются более целенаправленные и хорошо спланированные кампании.
#График количества проведенных сделок
plt.figure()
pl=sns.boxenplot(y=data["Numb_Dls_Purch"],x=data["Clusters"], palette= pal)
pl.set_title("Количество проведенных Сделок")
plt.show()
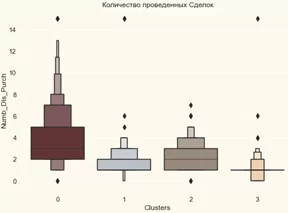
В отличии от кампаний, предлагаемые сделки были успешными. Они имеют наилучший результат с кластером 0 и кластером 3, тем не менее, наши успешные клиенты из кластера 1 не очень заинтересованы в сделках, кажется, что, в подавляющем большинстве, ничего не привлекает.
Теперь, когда мы сформировали кластеры и изучили их покупательские привычки, можем рассмотреть клиентов, которые находятся в этих кластерах. Для этого проведем профилирование сформированных кластеров и придем к выводу о том, кто является нашим главным клиентом и кому требуется больше внимания со стороны маркетинговой команды розничного магазина. Чтобы это решить я буду изображать характеристики, которые указывают на личные качества клиента, ввиду кластера, в котором они находятся. На основе результатов можно будет сделать выводы.
Person = [ "KdHm","Tnhm","Cust_F", "Age", "Children", "Family_Size", "Is_Parent", "Edctn","Living_With"]
for i in Person:
plt.figure()
sns.jointplot(x=data[i], y=data["Spent"], hue =data["Clusters"], kind="kde", palette=pal)
plt.show()
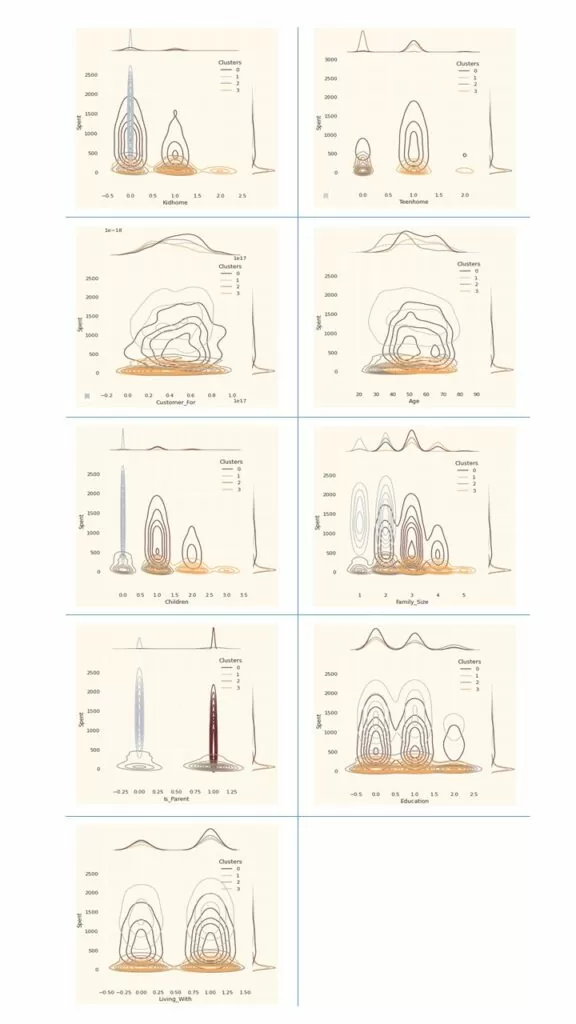
Далее представлена информация, которая может быть получена о клиентах в разных кластерах.
Кластер с номером 0:
- являются родителями
- имеют не более 4 членов семьи и не менее 2
- родители-одиночки являются частью этой группы
- люди более старшего возраста
Кластер с номером 1:
- не являются родителями
- максимум два члена семьи
- немного больше пар, чем одиноких людей
- охват разных возрастов
- группа с высоким уровнем дохода
Кластер с номером 2:
- большинство из этих людей – родители
- максимум три члена семьи
- как правило, в семье один ребенок, и он не подросток
- относительно прошлого кластера, молодые
Кластер с номером 3:
- являются родителями
- в семье не более пяти членов семьи и не менее двух
- у большинства в семье есть подросток
- относительно старше других групп
- группа с низким доходом
В данной статье я выполнил неконтролируемую кластеризацию, с использованием уменьшения размерности с последующей агломерационной кластеризацией.
Я пришёл к 4 кластерам и в дальнейшем использовал их для профилирования клиентов в кластерах в соответствии с их семейными особенностями и доходами/расходами. Это может быть использовано при планировании более эффективных маркетинговых стратегий.