/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Обнаружение выбросов и аномалий всегда актуально для исследователя. Если решаются задачи прогнозирования, то удаление нетипичных значений, как правило, повышает точность предсказаний, поскольку данные без аномалий представляют собой нормальный (типичный) объект. Кроме того, статистические характеристики чувствительны к наличию выбросов.
Перед поиском выбросов следует помнить, что не существует формального определения выброса, и тот или иной алгоритм в силу своей жесткости или мягкости может удалять вместе с выбросами и часть нормальных данных или, наоборот, оставлять часть выбросов в данных.
Существуют различные подходы к решению этой проблемы. Разберем один из них — критерий Шовене.
Суть критерия Шовене заключается в проверке неравенства, которое приведено в следующей формуле:
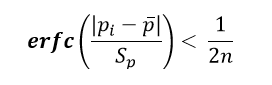
где
pi – i-тое значение ряда
p̄ — среднее значение ряда
Sp – стандартное отклонение ряда
n – число наблюдений ряда
erfc – это дополнительная функция ошибок на основе интеграла вероятности или Пуассона, который, в свою очередь, применяется в теории вероятности.
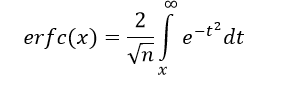
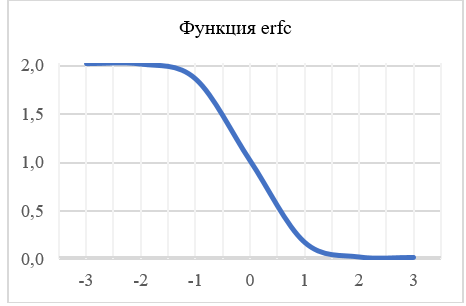
Согласно графику функции erfc, с возрастанием аргумента значение функции стремятся к нулю. Таким образом, если в левой части выражения в скобках будет слишком большое число, то искомое значение (pi) будет выбросом. Если неравенство выполняется, то значение pi является аномальным выбросом.
Поиск выбросов с помощью критерия Шовене является итерационной процедурой, которая подразумевает удаление аномального выброса после очередной итерации и последующего обнаружения выбросов на оставшихся данных. Процедура завершается в момент, когда неравенство перестает выполняться. Считается, что в момент остановки в ряду не осталось выбросов.
В Python рассчитать функцию erfc возможно с помощью библиотеки math (math.erfc() )
import math
import statistics as st
import pandas as pd
import numpy as np
def shovene(data):
df=data.iloc[:, 0].tolist()
iteration_counter = 0
pp=[ ] #запишем выбросы переменную
while True and len(df) > 1:
iteration_counter += 1
stop_iter = True
p_mean = st.mean(df)
p_stdev = st.stdev(df)
print("Итерация:", iteration_counter)# распечатывается номер итерации
for p in list(df):
if p_stdev > 0 and\
math.erfc (math.fabs (p-p_mean)/p_stdev)<1/(2*len(df)):
print("Обнаружена аномалия:", p)# распечатывается факт аномального выброса
pp.append(p)
df.remove(p)
stop_iter = False
if stop_iter:
break
d_float=np.array(pp, dtype=np.float32)
return round((len(d_float)/len(data)*100),2), d_float
Применяем функцию и получаем результат:
dd=shovene(df)
print('Шовене - процент выбросов',dd[0])# отображение процента выбросов
print('Шовене - выбросы',dd[1])# отображаются собственно выбросы
Перед применением данного критерия следует четко представлять, какие данные мы считаем аномальными. Например, ставка процента по кредиту не может быть 1000% годовых или иметь отрицательное значение, а возраст заемщика составлять 500 лет или 2 года. Также следует иметь ввиду, что монотонно возрастающий ряд не поддается детектированию в части аномалий (например, временной ряд).
Среди исследователей данных отношение к этому критерию неоднозначное. Так, в статье [2] автор не рекомендует критерий Шовене к практическому применению, в то же время указанный инструмент входит в состав межгосударственного стандарта [1] при расчете промахов измерений. Кроме того, критерий Шовене описывается в книге профессора Колорадского университета Дж. Тейлора [3], где автор приходит к оригинальному выводу о том, что данный инструмент «следует использовать для обнаружения данных, которые могли бы по крайне мере рассматриваться как кандидаты на отбрасывание». Таким образом, выбор остается за пользователем в конкретных ситуациях.
В целом, критерий Шовене не является панацеей при решении проблем очистки данных от аномальных выбросов, но вполне может использоваться в качестве своеобразного экспресс – метода определения грубых выбросов. Например, с его помощью можно в оперативном порядке оценивать качество данных перед их разведочным анализом или проводить периодическую ревизию пополняемых на постоянной основе баз данных на предмет ошибочного заполнения тех или иных данных.
Описываемый критерий реализован в Python библиотеке neulab.OutlierDetection (на момент написания статьи версия 0.0.23). Однако скорость работы указанной библиотеки далека от оптимального, что выражается в медленной обработке отдельных выборок. Поэтому пользователю надо быть готовым к длительной процедуре происка выборосов на некоторых датасетах.
Список литературы:
- ГОСТ 9.514-99. Межгосударственный стандарт. Единая система защиты от коррозии и старения. Ингибиторы коррозии металлов для водных систем. Электрохимический метод определения защитной способности. – М.: ИПК Издательство стандартов, 2001. – 19 с.
- Заляжных, В.В. О критериях одиночных выбросов / В.В. Заляжных // Журнал естественнонаучных исследований. 2022. Т. 7. № 1. С. 16-21.
- Тейлор, Дж. Введение в теорию ошибок / Дж. Тейлор; пер. с англ. Л.Г. Деденко. – М.: Мир, 1985. – 272 с.