/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Многие организации столкнулись с заболеванием своих сотрудников коронавирусом. В числе принятых мер – перевод части штата на дистанционную работу, а также тестирование сотрудников на COVID -19 на постоянной основе.
Нарушения сроков прохождения тестирования на COVID-19 ведет к распространению коронавирусной инфекции.
Рассмотрим на примере, как можно провести анализ сроков прохождения тестирования и к каким выводам можно прийти.
Лучшим помощником при решении множества задач обработки данных, конечно, является Python.
Но результаты анализа нужно визуализировать…
Кто придет на помощь аналитику? Конечно, Gephi!
Рассмотрим, как это сработает в нашей задаче.
Устанавливаем ПО (https://gephi.org), запускаем и создаем новый проект.
Теперь нужно импортировать в него данные.
Создаем общий data frame из сотрудников с положительными тестами.
Затем формируем data frame из сотрудников, которые нарушили сроки прохождения тестирования, пришли на работу без теста, а затем оказались с положительным тестом.
import pandas as pd
PositiveTestFr = pd.read_excel('StateTesting.xlsx')
# Сверяем поле 'Дата тестирования (план)' с 'Дата тестирования (факт)' для положительтных результатов теста
PositiveTestFr = PositiveTestFr.loc[(PositiveTestFr['Результат'] == 1) &
(PositiveTestFr['Дата тестирования (план)'] < PositiveTestFr['Дата тестирования (факт)'])]
Группируем отделы и выделяем отделы, где случаев заражения больше 1.
Генерируем финальный data frame, в котором выделены все сотрудники «диссиденты», и все заражения в рамках отделов.
Из списка выбираем те отделы, где больше всего заражений.
# Сумируем количество заражений по отделам
DepSumDevian = PositiveTestFr.groupby('Отдел', as_index=False)['Результат'].sum()
DepSumDevian = DepSumDevian.loc[DepSumDevian['Результат'] > 1].rename(columns={'Результат': 'Сумма по отделам'})
# Выбираем отделы с максимальным количеством заразившихся
max_devian = sorted(DepSumDevian['Сумма по отделам'].unique())[-5:]
DepSumDevian = DepSumDevian.loc[DepSumDevian['Сумма по отделам'] >= max_devian[0]]
# Формируем промежуточный data frame
IntermediateDataFrame = PositiveTestFr.merge(DepSumDevian, how='outer', on='Отдел')
IntermediateDataFrame = IntermediateDataFrame[['Сотрудник', 'Отдел', 'Дата тестирования (факт)', 'Сумма по отделам']].\
rename(columns={'Дата тестирования (факт)': 'Дата заражения'})
# FinalDataFrame.to_excel('result.xlsx')
Сортируем data frame по дате и группируем по отделам.
# Разбиваем полученный data frame по неделям
IntermediateDataFrame = IntermediateDataFrame.sort_values(by=['Дата заражения'])
Weeks_df = [g for n, g in IntermediateDataFrame.groupby(pd.Grouper(key='Дата заражения', freq='W'))]
need_dfs = list()
# Сортируем каждый из них по количеству заражений в отделах
for week_df in Weeks_df:
if week_df.shape[0] > 0:
need_dfs.append(week_df.sort_values(by=['Сумма по отделам'], ascending=False))
# Соединяем в итоговый data frame
FinalDataFrame = pd.concat(need_dfs)
FinalDataFrame.to_excel('result.xlsx')
Теперь рассчитываем связи. В нашем случае будет два вида вершин – сотрудники и периоды заражения (10-20 дней). Ребром будет являться связь с периодом заражения.
Делаем расчет по data frame – считаем разницу по времени в днях между элементами.
После обработки мы имеем на выходе такой data frame: ФИО сотрудника – дата заражения – недельный период, в котором он заразился ( 0,1,2 и т.д.).
Все, что нам необходимо для создания графа, есть.
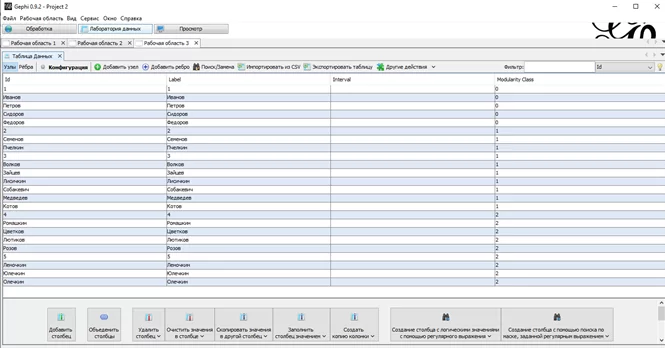
Добавляем связи по недельным периодам 1, 2, 3 и загружаем в Gephi.
В Gephi выбираем ФИО и недельные периоды, как узлы.
В ребрах добавляем связь с узлами (сотрудник-недельный период) и связь между узлами.
Формируем граф.
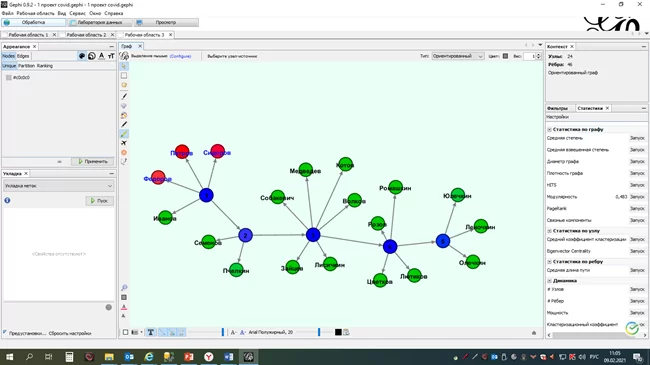
В результате выполнения анализа выявлены недостатки в организации работы, способствующие распространению COVID.
С использованием графовой аналитики удалось выявить случаи, когда нарушения сотрудников привели к каскадному распространению заболевания.
Gephi является новым и мощным средством визуализации различных данных, с помощью которых можно строить гипотезы и интуитивно обнаруживать закономерности.
Крепкого здоровья и берегите себя!