/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Предположим, что имеется файл payments.csv с данными об оплате клиентами некоторых товаров, содержащий четыре столбца: date — дата совершения платежа, customer — идентификатор клиента, category — категория товара/услуги, amount — сумма платежа.
| date | customer | category | amount |
Как известно, количество строк в pandas можно определить с помощью функции len или свойства shape:
import pandas as pd
df = pd.read_csv('payments.csv')
n_rows = df.shape[0]
print(n_rows)
Теперь установим dask:
python -m pip install "dask[complete]"Решим ту же задачу в dask:
import dask.dataframe as dd
df = dd.read_csv('payments.csv')
n_rows = df.shape[0].compute()
print(n_rows)
Для того, чтобы рассчитать сумму платежей по категориям с помощью pandas, необходимо выполнить следующий код:
import pandas as pd
df = pd.read_csv(‘payments.csv’)
sum_by_category = df.groupby('category')['amount'].sum()
print(sum_by_category)То же действие в dask:
import dask.dataframe as dd
df = dd.read_csv('payments.csv')
sum_by_category = df.groupby('category')['amount'].sum().compute()
print(sum_by_category)
Как видно из примера выше, отличие в коде при использовании dask заключаются только в появлении метода compute.
В отличие от pandas, dask позволяет обрабатывать датасеты, размер которых значительно превышает объем оперативной памяти компьютера.
Для сравнения возможностей pandas и dask был проведен ряд экспериментов, заключающихся в замере скорости расчета суммы платежей с группировкой по категориям. Было использовано две платформы с двумя типами накопителей (см. таблицу ниже) и 15 файлов в формате CSV размером от 0,14 Мб (20 тыс. строк) до 27 Гб (480 млн строк).
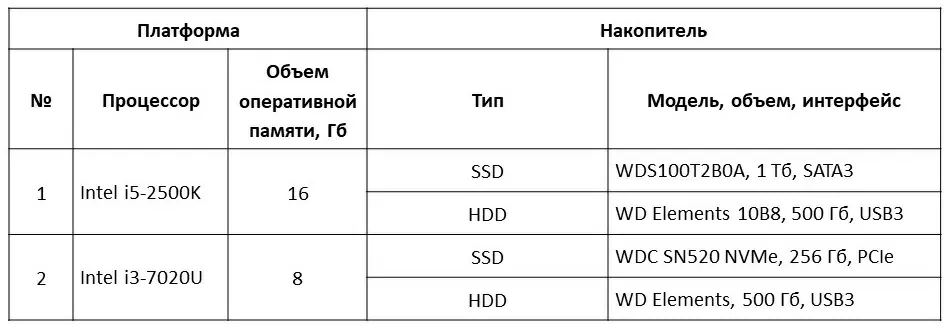
Для каждого сочетания «платформа — накопитель — размер датасета – библиотека» была проведена серия из пяти экспериментов с замером времени выполнения, результаты в сериях усреднены.
Визуализация скорости обработки датасетов относительно небольшого размера (до 200 Мб) на платформе №1 представлена на диаграмме.
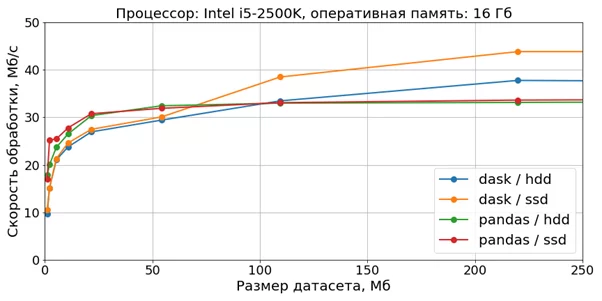
Из диаграммы следует, что при размере датасета приблизительно до 100 Мбайт скорость обработки с помощью pandas слегка превосходит скорость обработки с помощью dask, для больших размеров картина меняется на противоположную.
Диаграмма, охватывающая весь спектр датасетов, приведена ниже:
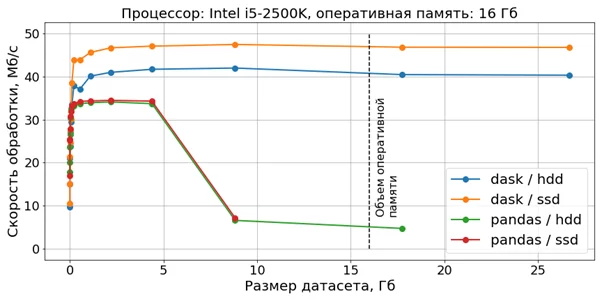
Из этой диаграммы можно сделать следующие выводы:
— для dask скорость обработки не зависит от размера датасета;
— для pandas при размере датасета, большем чем 25% от объема оперативной памяти, происходит существенное уменьшение скорости обработки, а при размере, сопоставимом с объемом оперативной памяти, наблюдаются сбои в работе.
На платформе №2 диаграмма выглядит схожим образом:
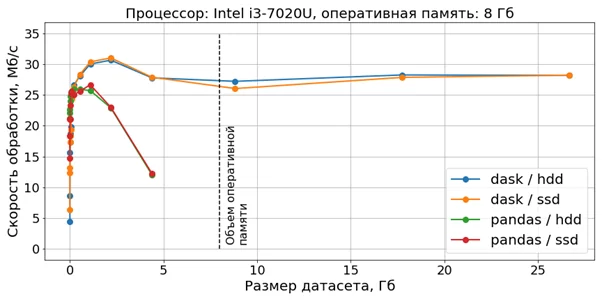
Таким образом, на относительно больших наборах данных dask выигрывает у pandas с позиций скорости обработки и стабильности работы.
В случае, когда данные представлены не в одном, а в нескольких файлах, их обработка в pandas становится затруднительной, а при использовании dask требуется лишь небольшая модификация приведенного выше кода, заключающаяся в замене методе read_csv имени файла на маску для имен файлов.
Например, код для определения суммарного количества строк во всех csv-файлах будет выглядеть следующим образом:
import dask.dataframe as dd
df = dd.read_csv('*.csv')
n_rows = df.shape[0].compute()
print(n_rows)
Код для расчета суммы платежей по категориям:
import dask.dataframe as dd
df = dd.read_csv('*.csv')
sum_by_category = df.groupby('category')['amount'].sum().compute()
print(sum_by_category)
Функциональность dask не ограничивается решением задач, подобных рассмотренным. Так, механизм Dask Arrays существенно расширяет возможности по вычислениям на больших массивах по сравнению с “чистым” numpy, а надстройка Dask-ML позволяет строить модели машинного обучения на больших обучающих выборках. Исчерпывающее описание можно найти в документации по библиотеке.
Подводя итоги, можно сказать, что библиотека dask позволяет более полно использовать ресурсы персональных компьютеров для обработки данных и может быть рекомендована к широкому применению.
Код приведенных примеров, а также экспериментальные данные можно найти в репозитории автора.