/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 10 мин.
Заглянуть в будущее
Когда мы хотим рассчитать количество звонков в колл-центр через час, поставить в пятничную смену достаточно курьеров или предсказать потребление электроэнергии небольшим городком через 5 лет, мы обращаемся к теме обработки временных рядов. На тему обработки timeseries (временной ряд, англ.) написано множество статей и создано несчетное количество часов видео. Но попробуйте задать поисковой системе вопрос: как работать с временными рядами. Уверен, вы закопаетесь в многообразии ссылок, похожих по смыслу и содержанию. Однако, ни одна из них не ответит на вопрос полностью. Авторы выдают два или три метода обработки как панацею от всех проблем в работе со временем.
Мы попробуем собрать в одной статье все классические и современные методы обработки даты и времени.
Разберем случай, когда в нашем распоряжении имеются только даты с количеством завершенных событий. В ежедневных задачах прогнозирования мы можем подгрузить дополнительные данные или иметь в своем распоряжении сразу несколько показателей для временного периода. Мы же будем извлекать максимум данных из даты и единичного значения целевого события.
TL:DR
Основная цель статьи – создание новых признаков из временных периодов для решения бизнес-задач. Информация будет полезна новичкам и специалистам, которые редко работают со временными рядами. К тексту прилагается заметка на kaggle. Вы можете изучать статью и одновременно выполнять код. Мы не будем строить графики и рассматривать особенности временных рядов.
Ничего личного – просто бизнес
Машинное обучение в бизнесе должно приносить прибыль, а качество работы моделей зависит от исходных данных. В статье я приведу несколько примеров извлечения и создания признаков. Читатель может подумать, что, если применить одновременно все полученные знания, можно получить идеальные данные.
Однако, не всегда перечень всех рассмотренных приемов помогает улучшить прогноз. Начиная работать с временными рядами, проанализируйте бизнес-метрики и горизонты событий текущей задачи. Если вы работаете с полугодовой отчетностью, выделение года, как отдельного признака только повысит количество мусора в данных. Или, если важна чувствительность модели к часовым интервалам, нет смысла выделять недельную сезонность.
Проговорите особенности задачи с менеджером проекта. Установите, на какие периоды и особенности процесса обратить внимание. Затем переходите к коду из следующих пунктов.
Курс молодого бойца
Рассмотрим особенности загрузки данных, ресемплирование временных рядов и проверку на монотонность. У функции pandas.read_csv() есть два аргумента, которые позволяют перекинуть любую колонку в индекс датафрейма и сразу преобразовать колонку в тип datetime. Экономим три строки кода и 2 минуты рабочего времени.
df = pd.read_csv(PATH, # путь к файлу
index_col=[0], # столбец, который будет индексом
parse_dates=[0] # столбец, который надо перевести в формат даты
Если у нас есть данные с часовым шагом наблюдений, а наша задача – изучить изменения за неделю, мы можем ресемплировать данные (resampling, англ. менять местами, перетасовывать). То есть задать новый шаг наблюдений и пересчитать количество событий за новый период. Полное описание функции можно найти здесь. Выбираем временной отрезок, на который будем изменять данные. В нашем случае – w (week, англ. неделя). Дата и время находятся в индексе, дополнительных колонок указывать не нужно. В конце функции добавляем агрегатор – sum() для подсчета суммы
df.resample(‘w’).sum() # Пример ресемплирования данныхДля проверки временной последовательности распределения данных можно применить функцию исследования монотонности – pandas.Series.is_monotonic. Применяем ее к столбцу с датой, в нашем случае – к индексу.
>>> df.index.is_monotonic
False
Или даты повторяются или строки перемешаны. Проверить на повторы можно функцией pandas.Series.is_unique.
>>> df.index.is_unique
True
Отсортируем индекс по возрастанию и проверим на монотонность еще раз. Кстати, sort_values() тут не работает.
>>> df.sort_index(inplace=True)
>>> df.index.is_monotonic
True
Не будем упоминать про исследование пропущенных значений, дубликаты и типы столбцов. Переходим к генерации признаков
Дни и окна
Начнем с основ — выделения отдельных периодов: дней, минут, часов, кварталов. Метод описан почти в каждой статье о временных рядах – синтаксис простой, к колонке в формате datetime дописываем признак, который необходимо выделить.
df['month'] = df.index.monthВ учебном примере на kaggle мы выделили 6 признаков – от года до номера конкретного дня в неделе. Полный список периодов, доступных для экстракции из даты можно найти здесь.
Переходим к окнам, скользящему и раскрывающемуся. Начнем со скользящего (rolling window, англ). Окно – это фиксированный временной промежуток, за который рассчитывается агрегация событий. Скользящее оно, потому что последовательно рассчитывает значения в течение всего датасета – как бы скользит по нему. Найдем среднее значение потребления энергии за шесть дней.
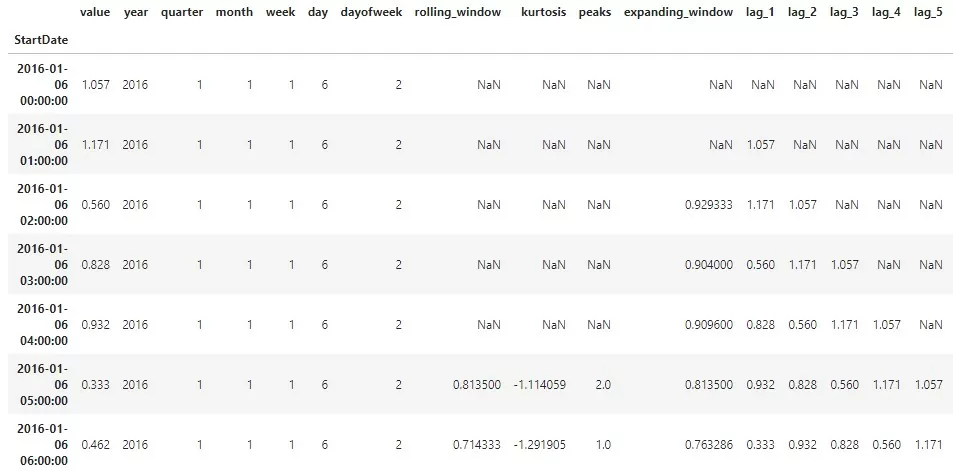
df[‘rolling_window’] = df[‘value’].rolling(6).mean()Расчет происходит на последнюю дату окна и записывается в новый столбец. На рисунке 1 показан пример скользящего окна с шагом в 6 строк. Значение 0,813500 – среднее значение value за период, отмеченный красной линией. 0,714333 – данные за промежуток, отмеченный зеленой линией.
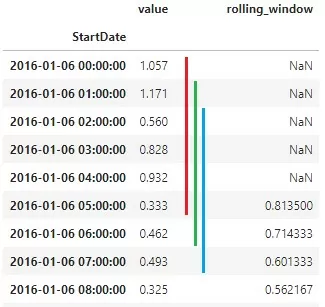
Не стоит делать окна больше 12 последовательных записей. Чем дальше вы «убегаете» от текущей даты, тем сильнее ваши новые данные будут замусоривать датасет. В большинстве задач помогает окно от 3 до 7 последовательных записей. Скользящим окном можно рассчитывать и другие агрегации, например, сумму или медиану. Вторым вариантом оконных расчетов является раскрывающееся окно (expanding window, англ). Задается начальный промежуток для калькуляции. На каждом шаге алгоритм добавляет к нему новое значение, пока не дойдет до конца ряда. В нашем случае, при расчете среднего по окну, в последней ячейке нового столбца мы получим среднее значение по всем значениям исходных данных.
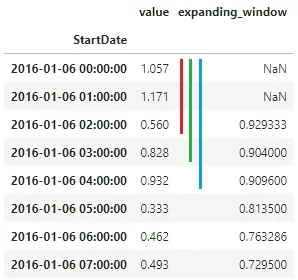
df[‘expanding_window’] = df[‘value’].expanding(2).mean()На рисунке 2 показана схема расчета раскрывающегося окна. Первое expanding_window = 0,929333 получается в результате вычисления среднего между значениями, отмеченными красной линией. Следующее – это среднее значений зеленой линии. И далее – нарастающим итогом. Данный вид окна подходит для расчета и более серьезных статистик. Например, добавим количество пиков и эксцесс Фишера. Не будем подробно останавливаться на математических определениях. Прочитать об эксцессе вы можете здесь. Прописывается команда на вычисления сразу после указания размера плавающего окна.
df[‘kurtosis’] = df[‘value’].rolling(6).apply(lambda x: len(find_peaks(x)[0]) #пики
df[‘kurtosis’] = df[‘value’].rolling(6).apply(lambda x: kurtosis(x)) # эксцессы
В отличие от скользящего, расширяющееся окно подходит только для расчета среднего значения или медианы. Калькуляция суммы измерений нарастающим итогом не поможет улучшить работу модели.
Лаги и разность
Следующий простой и действенный метод создать дополнительные временные признаки – выделить лаг. Простыми словами, задержку события. Сдвигаем события на определенное количество шагов вперед или назад во времени. Для создания лага применяем функцию shift() к нужному признаку.
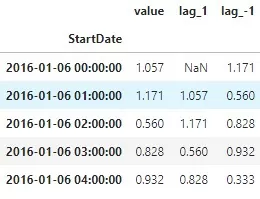
df[‘lag_1’] = df[‘value’].shift(1) # аргумент shift равен кол-ву шагов для сдвига Лаги можно создавать условно положительными, когда мы сдвигаем события в будущее и условно отрицательными, когда мы возвращаем массив в прошлое. Пример лагов на рисунке 3.
В практических задачах работает количество лагов диапазоне от 4 до 12. Прописывать 12 одинаковых строчек кода — скучно. Удобнее сделать это циклом.
for i in range(1, 10): # не выставляйте значение 0
df[‘lag_’+str(i)] = df[‘value’].shift(i) # получите сдвиг с нулевым шагом
Лаги комбинируются со скользящими окнами. При заметной недельной сезонности и имеющихся данных за каждый день, можно применить rolling_window() не текущему целевому признаку, а к седьмому или четырнадцатому лагам.
df[‘lag_7_mean’] = df[‘lag_7’].rolling(7).mean()Завершающий метод раздела – difference, или разность временного ряда. Изначально использовался для работы с нестационарными рядами. Ряд является стационарным, когда в течение времени количество событий изменяется равномерно. Например, ночью всегда поступает 10 заказов такси, а в полдень – 100. Независимо ото дня и времени года. Большинство временных рядов в реальных задачах – нестационарные.
Разность временного ряда рассчитывается по формуле:
diff(x) = x(t) – x(t – 1), где t – временной период, x – количество событий за этот период, 1 – шаг, с которым рассчитывается разность.
В коде это выглядит так:
df[‘diff’] = df[‘value’].diff()
df[‘diff’] = df[‘value’].diff(periods = 2) # periods – кол-во шагов между датами
В результате получаются значения на рисунке ниже. Первое непустое значение столбца diff 0.114 равно разности 1.117 и 1.057 из столбца value. Следующее -0.611 = 0,560 – 1.171. В столбце diff_2 значения получаются в результате разности текущего значения value и количество потребленной энергии 2 часа назад.
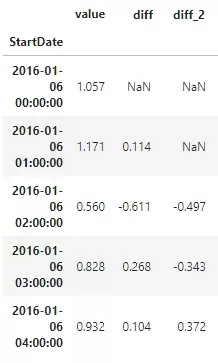
В боевых задачах обычно достаточно создать один столбец diff. Период для вычислений в нем выбирается на основании сезонности данных.
После выполнения кода из предыдущих разделов в датасете появятся пропущенные значения. Как на рисунке 5. Не забудьте удалить их перед обучением модели с помощью
df.dropna(inplace=True)Если у вас небольшой датасет, не рекомендуем создавать признаки с большим шагом окна для расчетов. При удалении первых строк с пропущенными значениями есть шанс потерять ценную информацию.
В заключение раздела добавим информацию о кодировании категориальных признаков. Для обучения моделей мы рекомендуем уменьшать размерность массивных значений, например, переводить полное написание года в единичное значение. В нашем примере мы вычтем текущий год из 2021.
df[‘year’] = df[‘year’].apply(lambda x: 2021 – x) Вместо значения 2016 получаем 5, вместо 2020 – 1. Метод позволяет увеличить качество работы моделей и ускорить вычислительные процессы. Данный прием хорошо работает с минутами, если данные представлены с 10 или 15 минутным шагом.
Воскресенье – радостный день
Мы отмечали, что не будем подгружать дополнительные данные. Однако, для обогащения выборки, можно создать новые признаки из выделенных. Как и в задаче про количество таксистов из вступления к этой статье, для расчета потребления электроэнергии нам пригодятся флаги рабочих и выходных дней. Выделяются они из столбца weekday. Логика простая – если день недели 5 или 6 по счету, перед нами выходной. Дополнительно стоит прописать выходные дни в государственные праздники. В этом случае мы затронем дополнительно признаки с номерами дней и недель. Код достаточно объемный, ознакомьтесь с ним в ноутбуке.
В результате выполнения мы получаем новый столбец с бинарным признаком. Метод помогает в решении задач, где количество событий сильно зависит от внутринедельной сезонности. Если мы видим сезонность событий, которая зависит от дня, создаем бинарный признак из него.
Автоматизация
На сегодняшний день есть два решения, которые облегчают работу с временными рядами: tsfresh и featuretools. Разберем работу второй, а tsfresh оставим для самостоятельного изучения.
Библиотека featuretools позволяет одновременно генерировать признаки из столбцов с различными типами данных. В нашем случае мы обработаем дату и расход энергии за одну итерацию. Четыре строки кода построят нам 8 так называемых «примитивных» признаков. Не будем дублировать ячейку ноутбука в статью. Разберем список фичей, которые переданы в переменную primitives. Библиотека умеет выделять временные отрезки, распознавать рабочий день или выходной и работать со значениями целевого признака. В нашем случае – мы рассчитали кумулятивное среднее. Возможно, автоматизация не дает построить углубленные признаки из имеющихся данных, однако в бытовых задачах значительно экономит время.
Заключение
Мы рассмотрели методы генерации новых признаков из даты и единичных значений целевого признака. С помощью ручного или автоматического создания фичей можно создать или обогатить датасет для обучения моделей. Главное – подходить к обработке временных рядов с продуманным планом действий. Не загрязнять имеющиеся данные лишними фичами. Дополнительно рекомендуем изучить вопросы стационарности и сезонности временных рядов. А затем применять полученные знания в совокупности, чтобы смотреть в будущее с оптимизмом.