/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Создание отчетов графовой аналитики является важной частью работы многих проектов и бизнес-процессов. Однако, процесс создания и настройки таких отчетов может быть сложным и требовать больших усилий. В этом посте рассмотрю, как использование языка программирования Python и его библиотек может значительно упростить генерацию отчетов графовой аналитики в формате PDF.
Для работы с PDF в Python есть множество библиотек, самые популярные из них: PyPDF2, ReportLab, FPDF.
Коротко приведу сравнение основных библиотек:
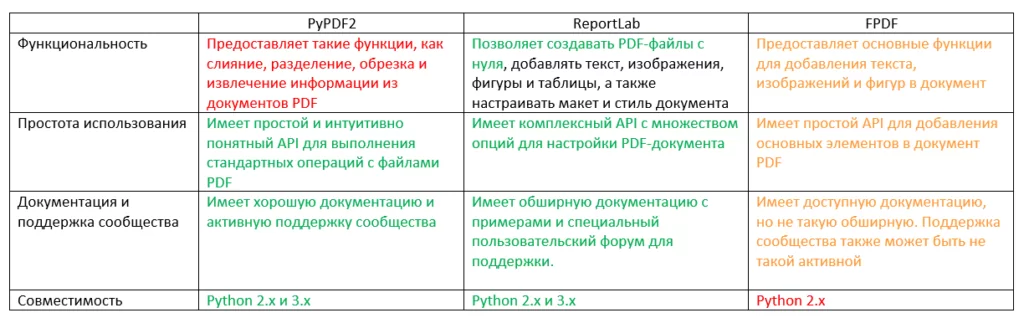
По совокупным критериям для дальнейшего разбора мной была выбрана библиотека ReportLab.
Одной из самых популярных библиотек для работы с графами в Python является NetworkX. Она предоставляет широкий набор инструментов для создания и анализа графов. Ее и буду использовать для создания графа и анализа данных.
В посте приведен код, необходимый для воспроизведения. Полный код доступен по ссылке.
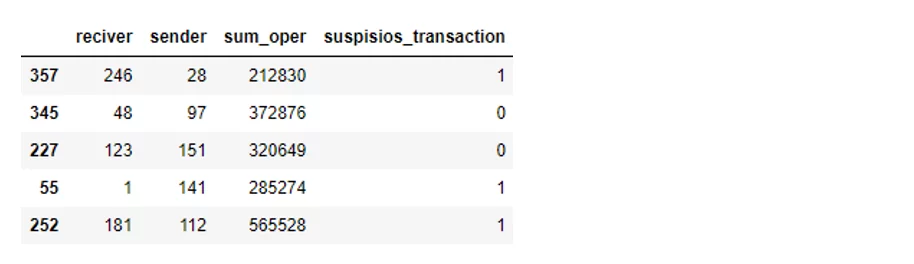
Данные сгенерирую с помощью Python. Пусть будет 500 операций, где будет информация об отправителе, получателе, сумме операции и флаг подозрительности операции.
df_dict = {}
count_operation = 500
for i in range(count_operation):
df_dict[i] = {'reciver' : random.randint(1, count_operation/2),
'sender': random.randint(1, count_operation/2),
'sum_oper': random.randint(1000, 1000000),
'suspisios_transaction': random.randint(0, 1)}
Добавлю 100 переводов, где получателем будет клиент 1, а отправителем- любой другой клиент из основного датасета:
for i in range(100):
df_dict[i] = {'reciver' : 1,
'sender': random.randint(1, count_operation/2),
'sum_oper': random.randint(1000, 1000000),
'suspisios_transaction': random.randint(0, 1)}
df = pd.DataFrame().from_dict(df_dict).T
Получится вот такой датасет:
Создам направленный граф на основе сгенерированного датасета:
graph = nx.DiGraph()
for loc in range(len(df)):
rec = df.iloc[loc].reciver
send = df.iloc[loc].sender
sum_o = df.iloc[loc].sum_oper
flag = df.iloc[loc].suspisios_transaction
graph.add_edge(rec, send, sum_oper = sum_o, suspisios_transaction=flag)
Отрисую граф с помощью библиотеки networkX. Для начала рассчитаю позиции вершин и отрисую граф с помощью networkx:
func_for_pos = nx.kamada_kawai_layout
nx.draw_networkx(graph, pos = func_for_pos(graph), ax=plt.subplots(figsize=(15,15))[1])
По результату отработки кода, получу граф:

Приступлю к написанию непосредственно кода отчета. Каждый отчет PDF можно персонализировать, выделяя наиболее важные вещи. В свой отчет я хочу добавить следующую информацию:
- Количество вершин и узлов в графе
- Представление графа с использованием аналитической раскладки
- Degree centrality
- Betweenness centrality
- Pagerank
- Выделение подозрительных операций
- Количество связанных компонент
Начну создавать PDF-отчет. Создам первую страницу:
c = canvas.Canvas("Отчет по графовой аналитике.pdf")Для того, чтобы в отчете корректно отображалась кириллица, необходимо скачать любой шрифт в формате .ttf (для отчета возьму: ‘DejaVuSerif.ttf’) и выполнить следующую настройку:
pdfmetrics.registerFont(TTFont('DejaVuSerif', 'DejaVuSerif.ttf'))где в TTFont передам имя шрифта и путь до файла (если в текущей директории, то просто имя файла). В дальнейших установках шрифта можно обращаться просто по объявленному имени.
Добавлю заголовок – 14 размера шрифта:
c.setFont("DejaVuSerif", 14)
c.drawString(beg_str, 750, 'Отчет анализа операций с использованием графовой аналитики')
Теперь размещу информацию о количестве вершин и ребер в графе:
c.setFont("DejaVuSerif", 12)
c.drawString(beg_str+20, 700, "Метрики графа:")
c.drawString(beg_str+40, 680, f"Количество вершин: {graph.number_of_nodes()}")
c.drawString(beg_str+40, 660, f"Количество ребер: {graph.number_of_edges()}")
Для сохранения отчета необходимо выполнять команду:
c.save()В текущей директории создался PDF-отчет: «Отчет по графовой аналитике.pdf» с одной страницей:

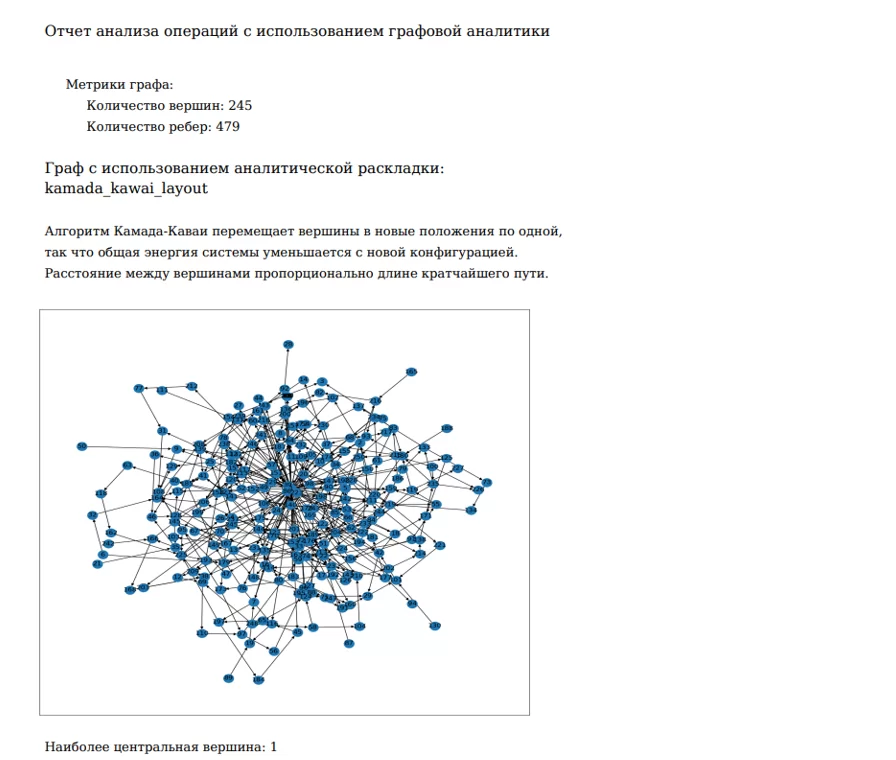
Добавлю рисунок в отчет с отрисовкой графа с помощью аналитической раскладки графа Камада-Каваи, который сделан ранее.
Для того, чтобы добавить рисунок в отчет (самый простой, но не самый оптимальный способ) необходимо сохранить рисунок в текущей директории, отрисовать в отчете и затем удалить с помощью библиотеки os.
plt.savefig('network_plot.png')
c.drawImage('network_plot.png', beg_str-beg_str, 50, 600, 500)
os.remove('network_plot.png')
Добавлю заголовок:
c.setFont("DejaVuSerif", 14)
c.drawString(beg_str, 620, "Граф с использованием аналитической раскладки:")
c.drawString(beg_str, 600, f"{str(func_for_pos).split(' ')[1]}")
Добавлю небольшое описание алгоритма раскладки:
c.setFont("DejaVuSerif", 12)
c.drawString(beg_str, 560, "Алгоритм Камада-Каваи перемещает вершины в новые положения по одной,")
c.drawString(beg_str, 540, "так что общая энергия системы уменьшается с новой конфигурацией.")
c.drawString(beg_str, 520, "Расстояние между вершинами пропорционально длине кратчайшего пути.")
Добавлю информацию о том, какая вершина находится в центре:
cent_node = 1
c.drawString(beg_str, 70, f"Наиболее центральная вершина: {cent_node}")
В итоге получилась вот такая простая, но информативная страница:
Создам новую страницу:
c.showPage()Добавлю заголовок с размером шрифта 14, затем верну 12 для основного текста:
c.setFont("DejaVuSerif", 14)
c.drawString(beg_str, 750, 'Метрики графа:')
c.setFont("DejaVuSerif", 12)
Рассчитаю 3 метрики графа и занесу их в отдельные датафреймы:
df_degrees = pd.DataFrame().from_dict(nx.degree(graph)).sort_values(1, ascending=False).rename(columns={0:'node', 1:'degree'})
bet = dict([(k, round(v,2)) for k,v in nx.betweenness_centrality(graph).items()])
pagerank = dict([(k, round(v,2)) for k,v in nx.pagerank(graph).items()])
df_betwenness = pd.DataFrame().from_dict(bet, orient='index').reset_index().sort_values(0, ascending=False).rename(columns={'index':'node', 0:'betweenness'})
df_pagerank = pd.DataFrame().from_dict(pagerank, orient='index').reset_index().sort_values(0, ascending=False).rename(columns={'index':'node', 0:'pagerank'})
Теперь отображу топ-7 вершин в каждой метрике в виде таблицы с заголовком:
table = Table([df_degrees.columns.tolist()] + df_degrees.iloc[:7].values.tolist())
table.wrapOn(c, 100, 70)
table.drawOn(c, beg_str, 570)
c.drawString(beg_str, 720, 'Cтепени вершин')
Аналогично для остальных таблиц, меняя только расположение на листе.
Получу вот такой раздел с таблицами:
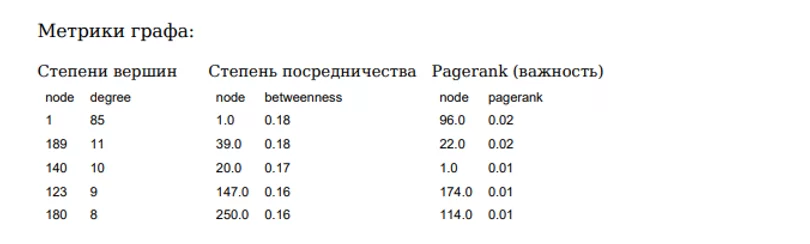
Задам цвета:
• ребрам – в соответствии с флагом подозрительности,
• вершинам – в зависимости от степени. Если степень вершины больше 6, то красный, иначе – зеленый.
df['color_edge'] = df.suspisios_transaction.apply(lambda x: 'red' if x==1 else 'green')
color_node = df_degrees['degree'].apply(lambda x: 'red' if x>6 else 'green')
Отрисую граф с цветами ребер и вершин и также добавлю в отчет:
nx.draw_networkx(graph, pos = nx.kamada_kawai_layout(graph),
edge_color=list(df.color_edge),
node_color=color_node,
ax=plt.subplots(figsize=(15,15))[1])
plt.savefig('network_plot2.png')
c.drawImage('network_plot2.png', 0, 100, 600, 500)
c.drawString(beg_str, 550, "Граф, где красные вершины - степень>6, ребра - с флагом 1)")
os.remove('network_plot2.png')Также добавлю строчку с количеством связанных компонент:
c.drawString(beg_str, 100, f"Количество связанных компонент в графе - {len([i for i in nx.connected_components(graph_bad_all.to_undirected())])}")Получу вторую часть страницы:
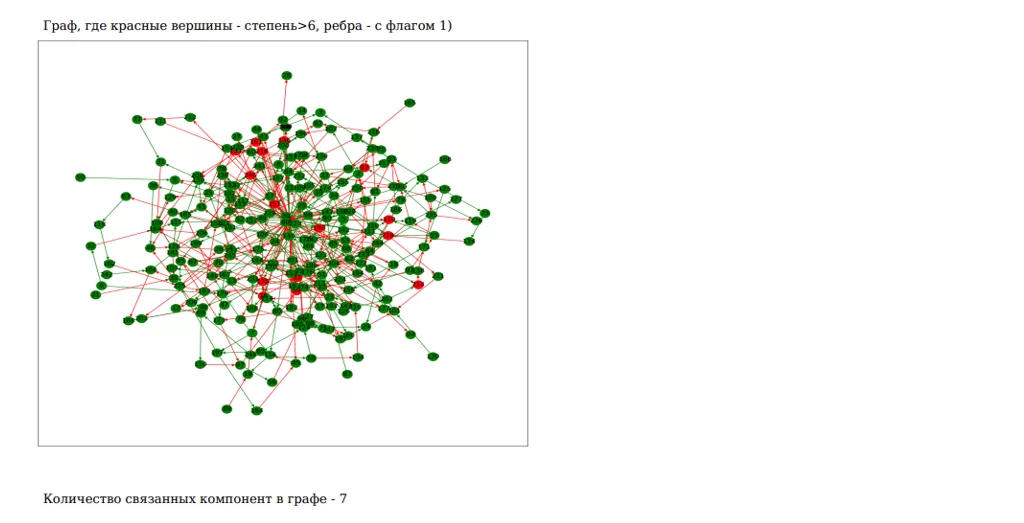
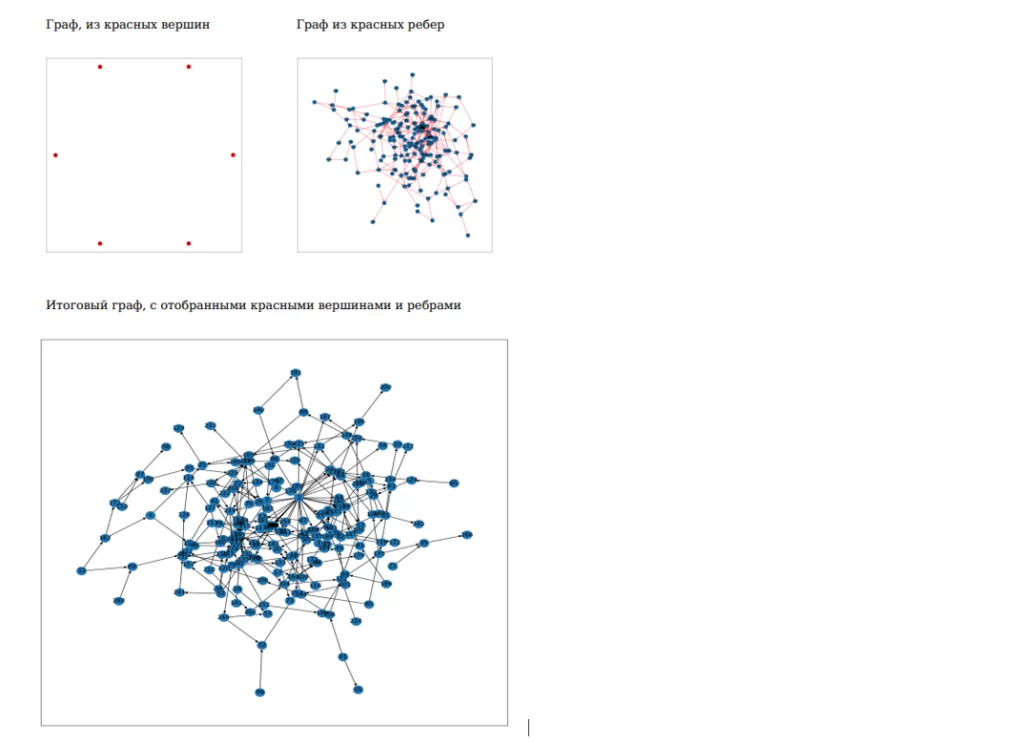
Отберу вершины и ребра красного цвета. Нарисую 3 графа, состоящие:
- Только из красных вершин,
- Только из красных ребер,
- Совместно.
Новые графы размещу на новой странице, как и делала до этого. В результате получу последнюю страницу в отчете:
В этом посте я рассмотрела только базовые возможности библиотеки и создала простой отчет в формате PDF с помощью Python. Однако библиотека обладает богатым функционалом и предоставляет множество инструментов для создания профессиональных и настраиваемых PDF-документов.
Python и его библиотеки делают процесс генерации отчетов графовой аналитики в формате PDF проще и эффективнее. Они позволяют автоматизировать создание отчетов, упрощая работу с данными и настройкой внешнего вида документов. Это особенно полезно для проектов, требующих анализа и визуализации данных.
Надеюсь, что этот пост поможет начать использовать Python для генерации отчетов в формате PDF и упростит работу с данными.