/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Краткое описание библиотеки NetworkX с некоторыми примерами можно увидеть здесь, тут же размещена документация и другие публикаций, в разной степени затрагивающие NetworkX.
Для начала введу основные определения, необходимые для последовательного и плавного погружения в данную область по мере изложения материала.
Простым графом G(N, V) в теории графов называют совокупность двух множеств — множества вершин графа N и множества его рёбер E — неупорядоченных пар различных элементов множества N.
Построю с помощью библиотеки NetworkX первый граф G(N, V) , состоящий из множества вершин
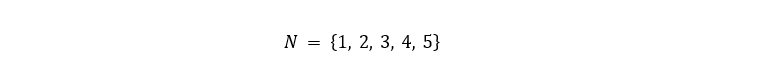
и множества рёбер
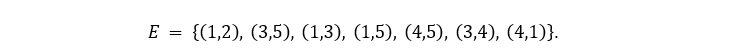
import networkx as nx # импортируем библиотеку
G = nx.Graph() # создаем пустой граф
G.add_nodes_from([1, 2, 3, 4, 5]) # добавляем вершины в граф
G.add_edges_from([(1, 2), (3, 5), (1, 3), (1, 5), (4, 5), (3, 4), (4, 1)]) # добавляем ребра в граф
nx.draw(G, node_size=500, with_labels=True, node_color='y') # визуализация графа
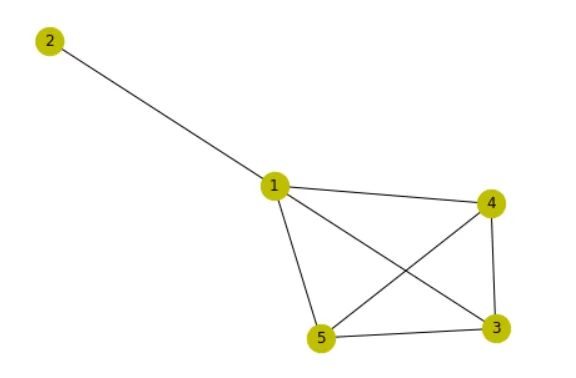
Такая модель позволяет удобно работать с данными, представляющими из себя объекты, между которыми можно выделить связи. Одна из самых популярных областей, в которой используются графы является Process Mining – область, фокусирующаяся на обнаружении, анализе и оптимизации бизнес-процессов на основе данных из журналов событий.
Конечно же, область применения графов совсем не ограничивается одним только Process Mining; если данные возможно спроецировать на граф, то, сделав это, вы откроете для себя богатый спектр различных методов исследования, а библиотека NetworkX поможет в этом.
В данном посте исследую датасет, описывающий взаимодействия героев фэнтези-романа “Песнь Льда и Огня” Джорджа Мартина. Два героя связаны ребром, если их имена появляются в тексте на расстоянии не более 15 слов в соответствующей книге. Данные находятся в открытом доступе для 5 книг. Построенная по этим данным сеть является взвешенной, где вес ребра определяется числом взаимодействий (упоминаний в тексте).
import pandas as pd
book5 = pd.read_csv('game_of_thrones_network/asoiaf-book5-edges.csv')
book5.head()
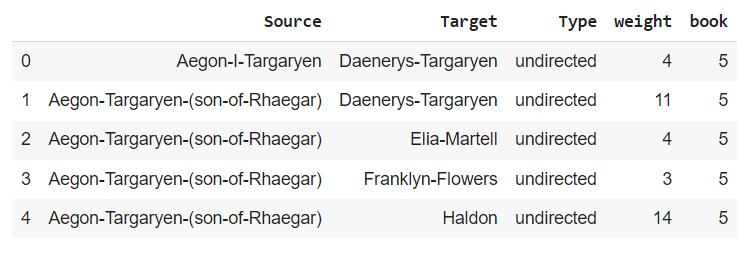
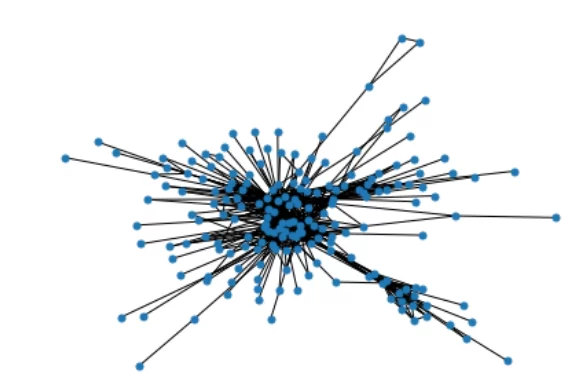
Построю сеть (граф) персонажей по первой книге и посмотрю на структуру произвольного ребра такого графа.
G1=nx.from_pandas_edgelist(book1,'Source', 'Target', edge_attr=True, create_using=nx.Graph())
nx.draw(G1, node_size=25)
print(list(G1.edges(data=True))[16])
('Jaime-Lannister', 'Loras-Tyrell', {'Source': 'Jaime-Lannister', 'Target': 'Loras-Tyrell', 'Type': 'Undirected', 'weight': 3, 'book': 1})
Видно, что в получившемся графе есть связь между Джейме Ланнистером и Лорасом Тиреллом со значением веса 3.
Не буду рассматривать простейшие характеристики полученного графа: число ребер, число вершин, плотность графа, степени вершин и т.д., сразу перейду к знакомству с новой характеристикой — центральностью вершин и мер для её определения.
Характеристика «центральность» позволяет определить степень важности вершины графа, основываясь на её расположении. Рассмотрю несколько способов её вычисления.
1. Центральность по степени (degree centrality)
Центральность по степени показывает, насколько важна конкретная вершина с точки зрения количества связей с другими вершинами в сети, и для взвешенного графа вычисляется следующим образом:
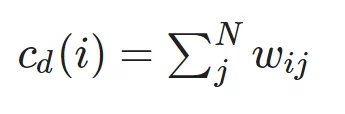
где i — индекс рассматриваемой вершины, w_{ij} — вес ребра (i, j), N — число вершин в графе.
Посмотрю на персонажей первой книги с наибольшим значением центральности по степени.
# топ-10 персонажей по убыванию значения центральности по степени
characters = sorted(list(nx.degree_centrality(G1).items()), key=lambda i: i[1], reverse=True)
print(*characters[:10], sep='\n')

2. Центральность по собственному вектору (eigenvector centrality)
Недостаток предыдущей меры заключается в том, что она учитывает только ближайших соседей рассматриваемой вершины, эта же мера учитывает “влиятельность” (центральных) ближайших соседей самих по себе. Принцип данной меры можно описать так: “если мои друзья влиятельны, то и я буду более влиятельным”. Формула для вычисления данной меры:
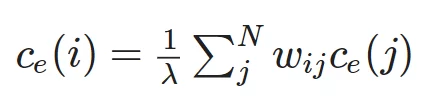
где i — индекс рассматриваемой вершины, w_{ij} — вес ребра (i, j), \lambda — некоторый нормировочный коэффициент.
Для вычисления центральности по собственному вектору необходимо преобразовать данную формулу, введя обозначения
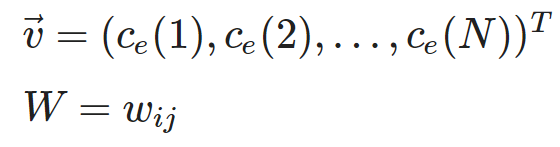
где \vec{v} — вектор, состоящий из значений центральностей каждой вершины, W — матрица весов рассматриваемого графа.
Используя введенные обозначения, исходная формула преобразуется к
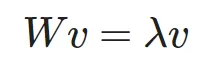
а это уже классическая задача на поиск собственных векторов матрицы, в качестве окончательного ответа необходимо брать собственный вектор, соответствующий максимальному собственному значению.
Посмотрю на топ-10 персонажей по мере центральности по собственному вектору.
# топ-10 персонажей по убыванию значения центральности по собственному вектору
characters = sorted(list(nx.eigenvector_centrality(G1).items()), key=lambda i: i[1], reverse=True)
print(*characters[:10], sep='\n')

Видно, что Санса Старк поднялась в топ-3 по сравнению с топ-10, соответствующим центральности по степени.
3. Центральность по близости (closeness centrality)
Предыдущие меры обычно относят к структурным, следующие же рассматриваемые две меры принято относить к геометрическим, так как они основаны на кратчайших путях в графе.

Данная мера имеет простой физический смысл: чем меньше расстояния от i-ой вершины до остальных j-ых вершин графа (в экстремальном случае dij = 1, т. е. вершины i и j связаны ребром), тем меньше будет знаменатель в формуле для cc (i), и тем больше будет значение самой центральности. Важно отметить, что данная мера имеет смысл только для связных графов, так как при наличии изолированных вершин или целых компонент кратчайшие пути до этих объектов будут вырождаться в бесконечность со всеми вытекающими последствиями.
Как обычно, вычислю значение данной меры для каждой вершины графа и посмотрю, какие персонажи теперь попадут в топ-10.
# топ-10 персонажей по убыванию значения центральности по близости
characters = sorted(list(nx.closeness_centrality(G1).items()), key=lambda i: i[1], reverse=True)
print(*characters[:10], sep='\n')

4. Центральность по посредничеству (betweenness centrality)
Данная мера очень популярна, и часто в различных литературных источниках по Network Science при упоминании термина «центральность», имеется в виду как раз центральность по посредничеству. Формула для вычисления значения данной меры для i-ой вершины графа уже будет выглядеть сложнее:

Простыми словами, данная мера показывает насколько часто рассматриваемая вершина i является «перевалочным пунктом» при переходах от одной вершины графа до любой другой. Она позволяет достаточно хорошо определять «узкие места» в графе — вершины, входящие в состав ребра или набора рёбер, соединяющих два ярко выраженных кластера.
Посмотрю на топ-10, формируемый посредством вычисления значения данной меры.
# топ-10 персонажей по убыванию значения центральности по посредничеству
characters = sorted(list(nx.betweenness_centrality(G1).items()), key=lambda i: i[1], reverse=True)
print(*characters[:10], sep='\n')

Видно, что впервые в топе, причем достаточно высоко, появилась Дейенерис Таргариен, что говорит о том, что данный персонаж является важным с точки зрения посредника между остальными персонажами книги.
5. Page Rank
Последняя из рассматриваемых мер в данном посте является тоже довольно популярной, но стоит немного особняком относительно предыдущих мер. Интересно, что изначально данная мера вводилась для того, чтобы ранжировать страницы при поисковом запросе в браузере Google Chrome. Раньше даже можно было смотреть, чему равен page rank открытого сайта. Важно отметить, что несмотря на популярность данной меры в области ранжирования веб-страниц, такое название она приобрела не из-за слова «page» («страница» с англ.), а благодаря её автору Ларри Пейджу (Larry Page).
Так как данная мера изначально применялась именно в веб-сети, то и вводилась она именно для направленного графа, каким как раз и является веб сеть, где некоторая страница может содержать в себе ссылку на другую страницу, но обратной ссылки может и не быть. Тем не менее, это не мешает обобщать данную меру на ненаправленный граф, просто считая, что при наличии ребра между двумя вершинами имеем два направленных ребра (от одной вершины к другой и наоборот).
Воспользуюсь готовой реализацией данной меры из библиотеки NetworkX и выведу топ-10 персонажей книги по мере Page Rank.
# топ-10 персонажей по убыванию значения Page Rank
characters = sorted(list(nx.pagerank(G1, alpha=0.85).items()), key=lambda i: i[1], reverse=True)
print(*characters[:10], sep='\n')

Функция nx.pagerank в качестве второго параметра принимает некое a,которое отвечает за вклад каждой из компонент в формуле для вычисления Page Rank, но часто принято для этого параметра указывать именно значение
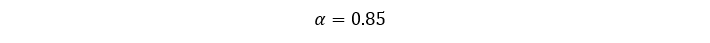
В этом посте я представил основные и наиболее часто используемые меры центральности в Network Science, в действительности же их существует не один десяток. Искренне надеюсь, что вы почерпнете полезную или просто интересную для вас информацию, а может быть и примените этот материал в своих исследования в области Network Science и смежных областях.