/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
У нас есть персональные данные покупателей сервиса, их местоположение, а также данные о статусе покупки сервиса и обратна связь по качеству сервиса в одном предложении.
Для того, чтобы решить задачу о прогнозе оттока клиентов необходимо прежде всего оценить качество имеющихся данных. Вопрос качества данных важен потому, что от него напрямую зависит корректность решения задачи машинного обучения.
Предлагаю рассмотреть имеющиеся данные на вопрос наличия в них пустых значений, чтобы оценить полноту предоставленной информации. Для того, чтобы вопрос качества имеющихся данных был наглядным визуализируем полноту данных при помощи разных инструментов.
Рассмотрим мой стандартный способ визуализации полноты данных с помощью диаграммы, дендрограммы и тепловой карты корреляции наличия данных.
Прежде всего необходимо получить информацию о ненулевых данных в датафрейме с данными d.
import pandas as pd
d = pd.read_csv(‘test.csv’)
d.info()
Построим столбчатую диаграмму, каждый столбец которой отражает количество ненулевых значений в каждом столбце датафрейма. На оси х находятся названия всех столбцов датафрейма, на оси у отражено количество заполненных строк в каждом столбце.
import numpy as np
import matplotlib.pyplot as plt
fig, axes = plt.subplots()
axes.bar(x, y)
axes.set_facecolor('seashell')
fig.set_facecolor('floralwhite')
fig.set_figwidth(20)
fig.set_figheight(10)
for tick in axes.get_xticklabels():
tick.set_rotation(45)
plt.show()
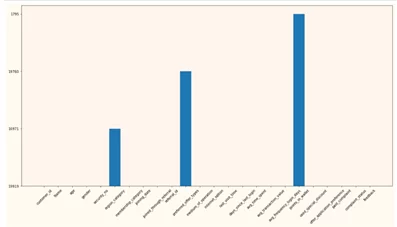
Насколько мы можем видеть данная диаграмма достаточно тяжела в понимании, потому что в ней не отражены столбцы датафрейма в которых нет пустых данных.
Для решения этой проблемы и наглядной визуализации используем другой способ построения столбчатого графика при помощи библиотеки missingno.
import missingno as msno
msno.bar(d)
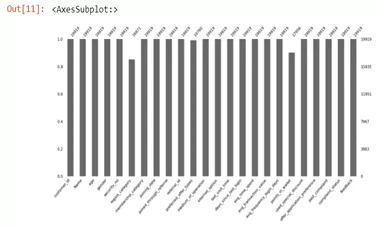
Теперь мы наглядно видим столбцы с отсутствующими значениями, а также количество ненулевых строк в каждом столбцу датафрейма.
Теперь рассмотрим корреляцию пустых значений в столбце датафрейма для этого используем дендрограмму и тепловую карту корреляции, которые также будут построены стандартным способом и используя инструментов из missingno.
import plotly.figure_factory as ff
fig = ff.create_dendrogram(d.corr())
fig.update_layout(width=700, height=400)
fig.show()
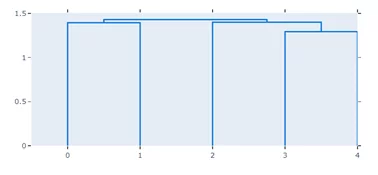
Диаграмма представляет собой дерево. Метод create_dendrogram кластерезирует найденные попарно коррелированные столбцы в датафрейме по иерархии и визуализирует в итоге дерево. Иерархия значений строится на основе столбцов с числовыми значениями, игнорируя нулевые, таких в нашем датафрейме 4 и они отражены на оси х. Значения на оси у соответствуют расстоянию между полученными кластерами.
Исходя из этого графика, мы не можем сделать вывод о коррелированности столбцов с пустыми значениями в датафрейме, поэтому построим при помощи инструмента построения дендрограммы в missingno.
msno.dendrogram(d)
Данный инструмент позволяет нам сделать точный вывод о наличии столбцов с пустыми значениями в датафрейме. Построение дендрограммы в missingno происходит на основе группировки столбцов с нулевыми значениями и строит иерархию от самого маленького количества пропущенных значений в столбце к самому большому. Количество пропущенных значений в столбце указано по оси у.
Рассмотрим другой способ визуализации корреляции столбцов с пустыми значениями в датафрейме – построение тепловой карты корреляции.
На тепловой карте отображается корреляция нулевого значения между столбцами датафрейма. Это позволяет нам понять, как отсутствующее значение одного столбца связано с отсутствующими значениями в других столбцах.
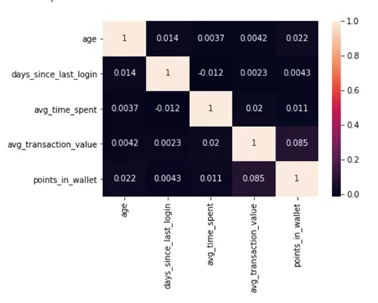
import seaborn as sns
sns.heatmap(d.corr(), annot=True)
Предлагаю теперь рассмотреть построение корреляции столбцов с пустыми значениями при помощи инструментария библиотеки missingno.
В тепловой карте missingno значения корреляции колеблются от -1 до 1, т.е. отражает разные степени влияния отсутствующих значений друг от друга. Отрицательное значение единицы показывает, что при наличии переменной в одном столбце точно будут отсутствовать значения в другом, а при положительном значении корреляции отражается что при наличии переменной в одном столбце точно будет иметься данные в другом. При нулевом значении показывается отсутствует влияние переменных в разных столбцах друг на друга.
msno.heatmap(d)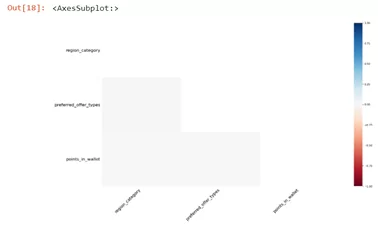
В данном случае лучше использовать стандартный способ построения тепловой карты корреляции данных при помощи библиотеки seaborn, потому что график этой библиотеки является более наглядным и информативным.
Мы рассмотрели различные инструменты и способы построения визуализации полных данных. Выявление недостающих данных для применения машинного обучения – ключевой элемент процесса по обеспечению качества данных. Этого можно достичь, используя различные методы библиотек pandas, seaborn, matplotlib.pyplot и missingno. Используя серию визуализаций библиотеки missingno, можем понять, сколько недостающих данных присутствует, где они возникают и как возникновение пропущенных значений связано между различными столбцами данных.