/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Прежде чем разобраться импортируем необходимые библиотеки:
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
В первую очередь понадобится понимание, из каких элементов состоит график. За ним можно обратиться к документации библиотеки matplotlib:
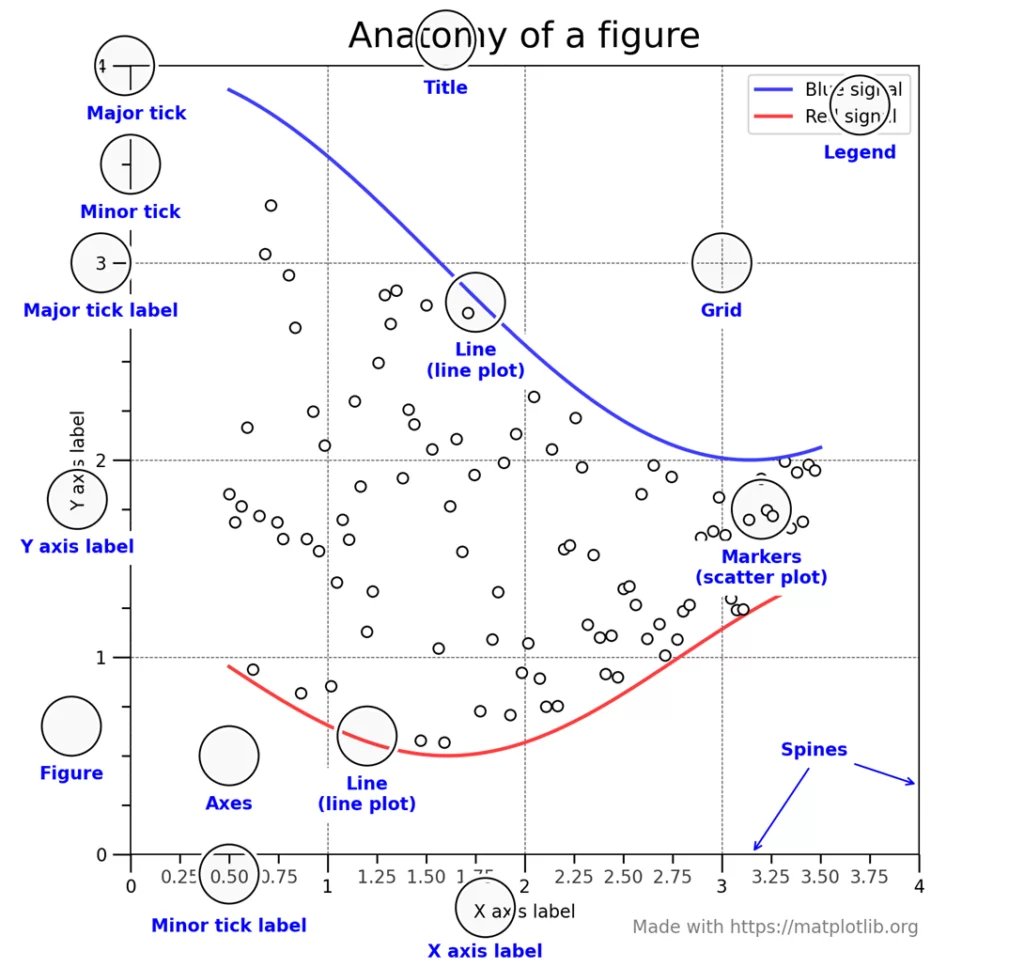
Всё пространство (figure) включает в себя график (Axes), который, в свою очередь, состоит из таких элементов, как границы (Spines), сетки (Grid), описания (Legend), самого графика (Line) и других.
Графики отражают зависимость, при этом элементы графика — оси, подписи и др. — открыты к настройке.
Базовый элемент figure может содержать в себе как один график, так и несколько.
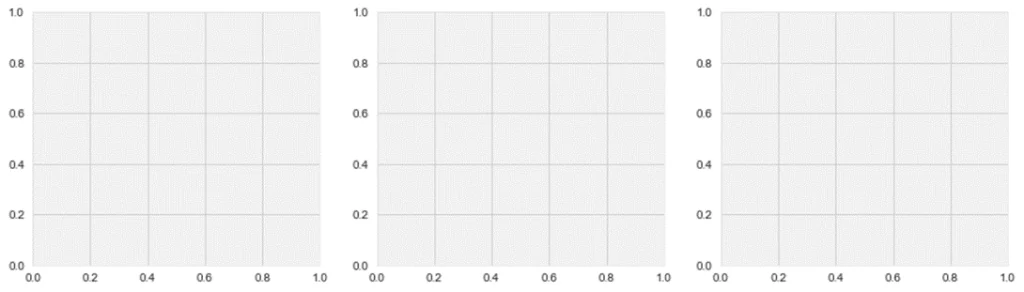
Например, создание нескольких графиков в одном окне может быть выполнено как:
fig, axes = plt.subplots(
1, #одной строкой
3, #три графика
figsize=(15, 4) #вписать в размер 15х4 дюйма
)
или…
fig = plt.figure(figsize=(16, 8)) #задаем фигуру
ax = [None for _ in range(6)]
ax[0] = plt.subplot2grid( #первый график сетки
(3,4), #размер сетки = 3 ряда по 4 элемента
(0,0), #локация первого элемента
colspan=4
)
ax[1] = plt.subplot2grid((3,4), (1,0), colspan=1) #аналогично задаем параметры остальных графиков
ax[2] = plt.subplot2grid((3,4), (1,1), colspan=1)
ax[3] = plt.subplot2grid((3,4), (1,2), colspan=1)
ax[4] = plt.subplot2grid((3,4), (1,3), colspan=1,rowspan=2) #этот график займет 1 колонку, но 2 ряда
ax[5] = plt.subplot2grid((3,4), (2,0), colspan=3)
for num in range(6):
ax[num].set_title(f'ax[{num}]')
ax[num].set_xticks([]) #подпишем каждый
ax[num].set_yticks([]) #..и уберем подписи осей

или…
fig = plt.figure(figsize=(16, 8))
gs = fig.add_gridspec(3, 4) #задаем сетку 3х4
ax = [None for _ in range(6)]
ax[0] = fig.add_subplot(gs[0, :]) #для каждого графика задаем позицию и размер
ax[0].set_title('gs[0, :]') #через элементы сетки
ax[1] = fig.add_subplot(gs[1, 0])
ax[1].set_title('gs[1, 0]')
ax[2] = fig.add_subplot(gs[1, 1])
ax[2].set_title('gs[1, 1]')
ax[3] = fig.add_subplot(gs[1, 2])
ax[3].set_title('gs[1, 2]')
ax[4] = fig.add_subplot(gs[1:, -1])
ax[4].set_title('gs[1:, -1]')
ax[5] = fig.add_subplot(gs[-1, :-1])
ax[5].set_title('gs[1, :-1]')
for num in range(6):
ax[num].set_xticks([])
ax[num].set_yticks([])

…или отрисовывать однотипные графики циклом/функцией (об этом ниже). Title, yticks, xticks, axes есть, поработаем над визуальным оформлением на реальных данных. В качестве них будет выступать информация о недвижимости на вторичном рынке.
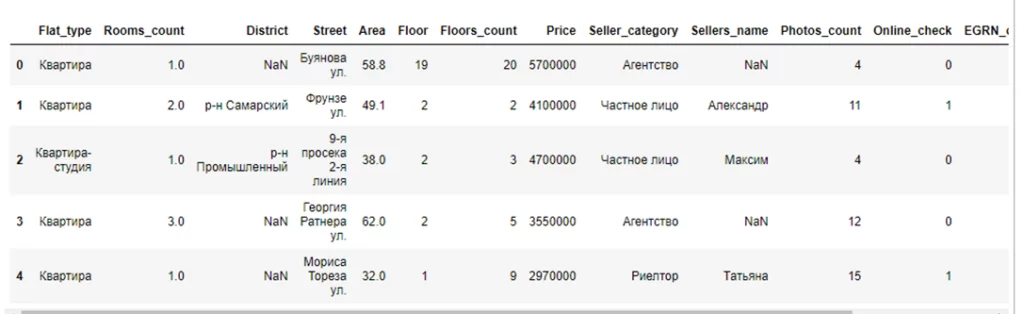
df = pd.read_csv('df_filtered.csv', index_col=0)
df.head()
print(f"{df.shape[0]} объектов, {df.shape[1]} признаков \
\nКатегориальные признаки: \n{list(df.select_dtypes(include=['object']).columns)}")
4460 объектов, 15 признаков
Категориальные признаки:
['Flat_type', 'District', 'Street', 'Seller_category', 'Sellers_name', 'Photos_count']
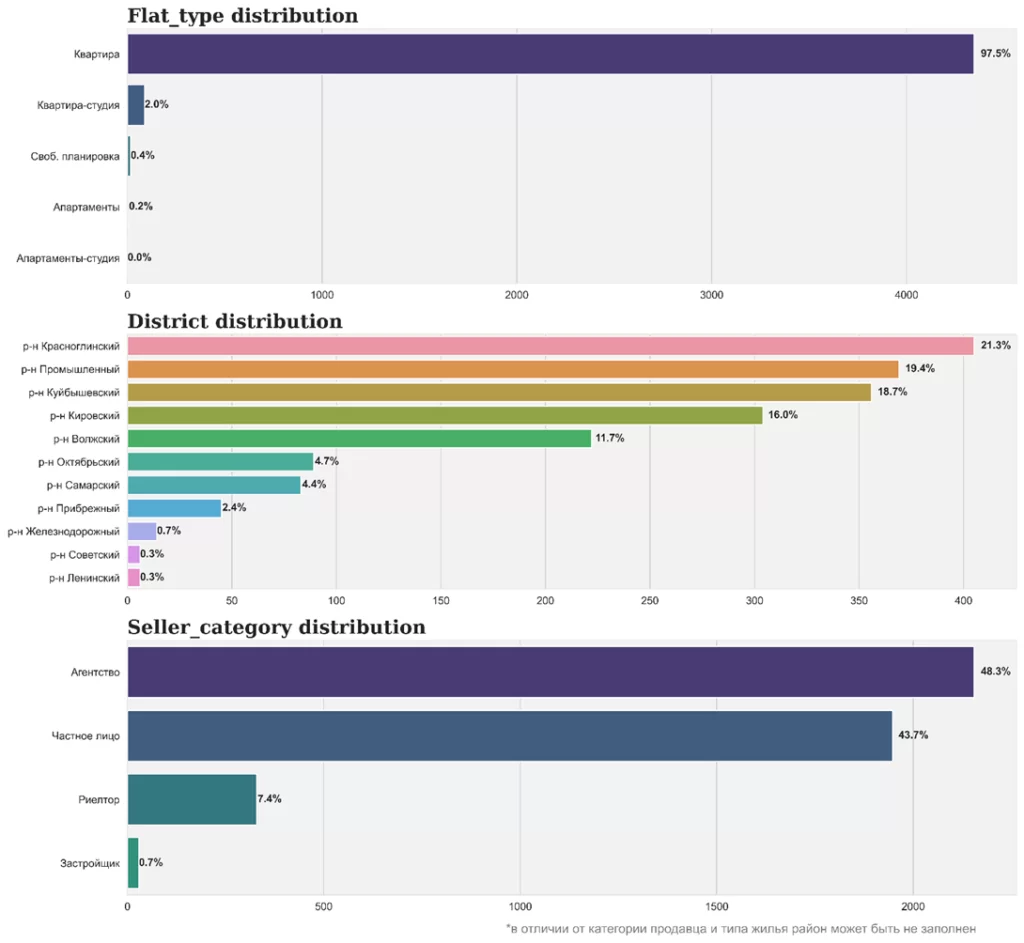
Как мы видим, в таблице содержится информация о почти 4,5 тыс. объектов недвижимости, категориальные признаки: Тип объекта недвижимости, Район, Улица, Категория продавца, Количество фотографий.
Я хочу посмотреть на графики распределений для типа жилья, района и категории продавца, отрисуем сразу все
cat_data = df.select_dtypes(include=['object']).columns[[0, 1, -3]] #выбираем колонки с типом жилья, районом и продавцом
fig, ax = plt.subplots(1, 3, figsize=(15, 5)) #создаем фигуру 'fig' размером 15х5 дюймов
#в ней будет 1 ряд из 3х осей (графиков) 'ах'
for num, col in enumerate(cat_data): #отрисовываем в цикле, даем название
sns.countplot(data = df, x = col, ax = ax[num])
ax[num].set_title(f'{col} distribution') 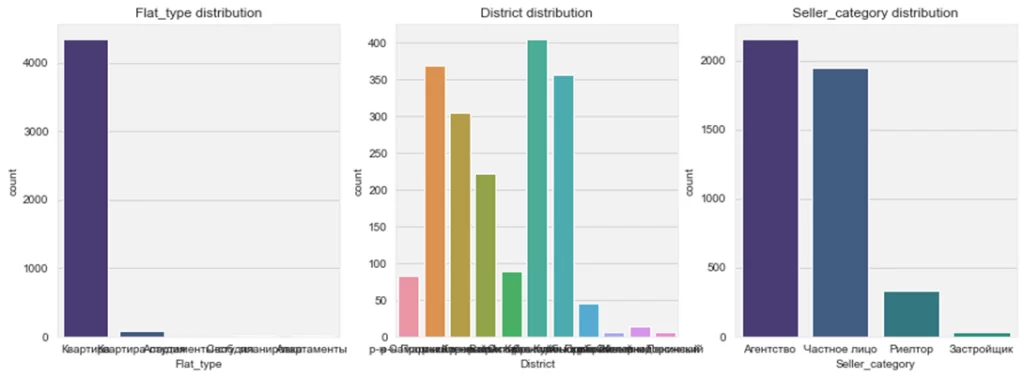
Первая проблема — все районы слились в один. Вторая — то же произошло с типом жилья. Можно повернуть подписи:
ax = sns.countplot(data = df, x = 'District')
ax.set_title('District distribution')
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right') #поворачиваем подписи
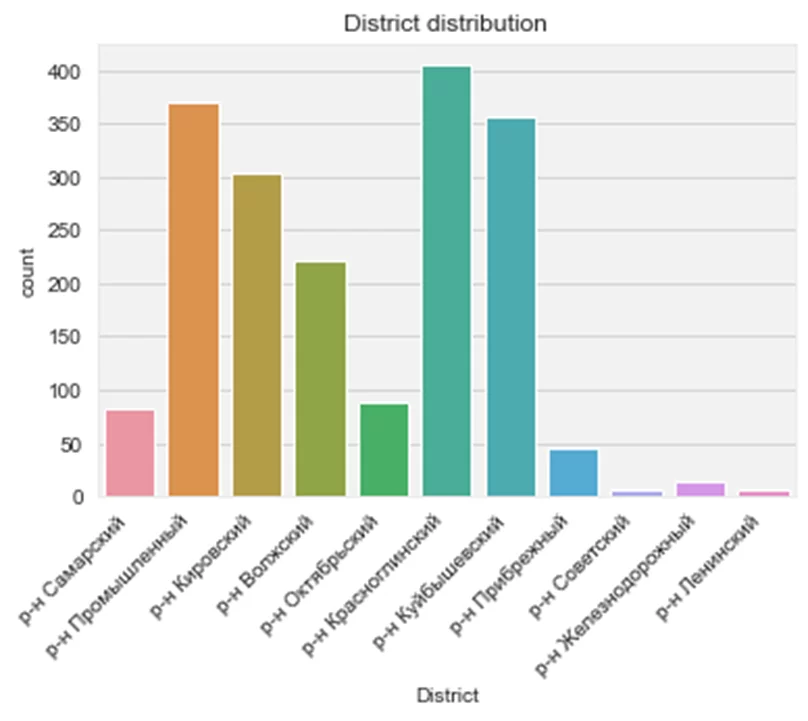
…или графики, передав ось X на Y:
fig, ax = plt.subplots(3, 1, figsize=(15, 15)) #сделаем 3 ряда по 1 графику, чтобы они не мешали друг другу
for num, col in enumerate(cat_data):
sns.countplot(
data = df,
y = col,
ax = ax[num],
order = df[col].value_counts().index #передадим порядок сортировки
)
ax[num].set_title(f'{col} distribution')
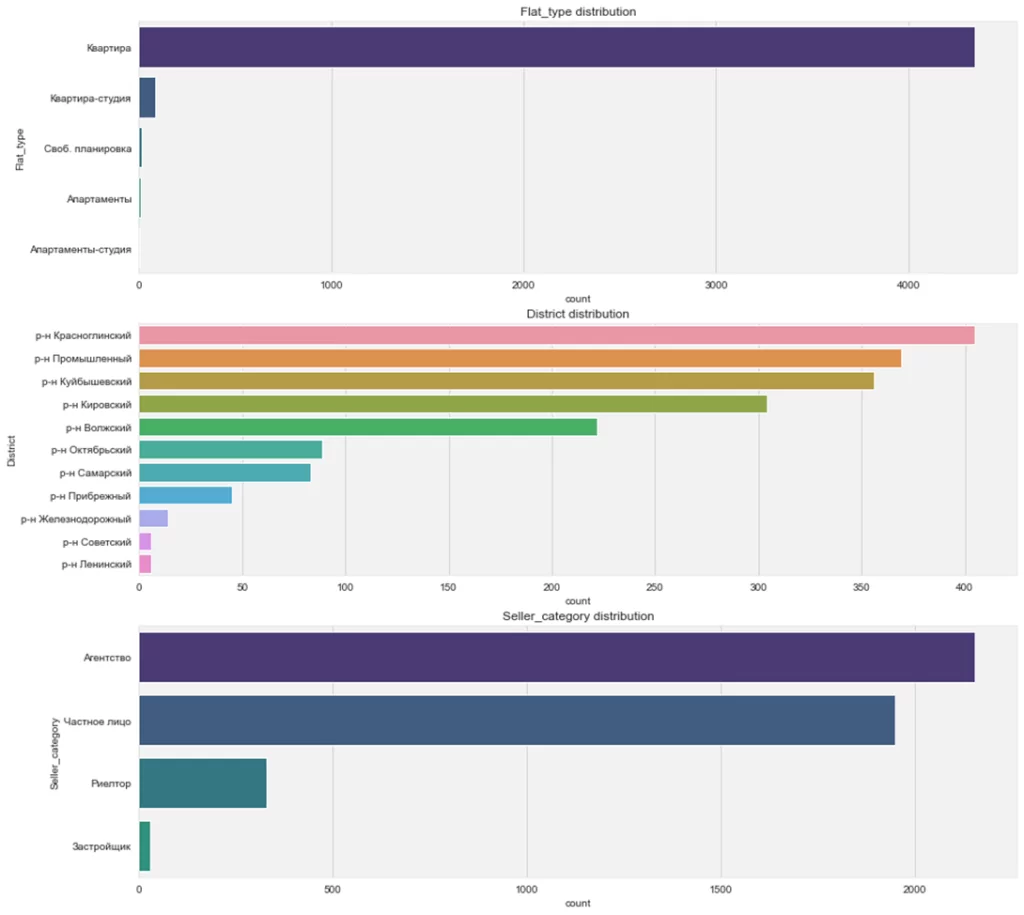
Поиграемся немного со шрифтами и цветом:
sns.set_palette('viridis') #выбираем цветовую схему
sns.set_style('whitegrid') #и фон
Цветовую схему можно не только выбрать из предустановленных https://matplotlib.org/stable/tutorials/colors/colormaps.html, но и создать самостоятельно https://matplotlib.org/stable/tutorials/colors/colormap-manipulation.html
sns.set_style({
'axes.facecolor': '.95', #яркость фона в диапазоне [0-1]
'axes.edgecolor':'.9' #яркость рамок в диапазоне [0-1]
})
fig, ax = plt.subplots(3, 1, figsize=(15, 15), dpi = 500) #увеличим разрешение
for num, col in enumerate(cat_data):
sns.countplot(
data = df,
y = col,
ax = ax[num],
order = df[col].value_counts().index
)
ax[num].set(xlabel=None, ylabel=None) #уберем подписи осей
ax[num].set_title(f'{col} distribution',fontdict= { #зададим размер, шрифт и положение заголовков
'fontsize': 18, 'fontweight':'bold', 'fontfamily':'serif'
}, loc = 'left')
counts = df[col].value_counts()
for i, j in enumerate(counts.index):
ax[num].annotate( #подставим проценты
f'{counts[j] / counts.sum():.1%}', #(первый аргумент - текст,
xy=(counts[j] + 0.008*counts[j], i), #второй аргумент - его место на графике - х,у)
va = 'center',
fontweight='bold'
)
plt.suptitle( #...и комментарий
'*в отличии от категории продавца и типа жилья район может быть не заполнен',
x=0.66, y=0.1, color='gray'
); 
Ок, мы увидели распределение, теперь настроим тепловую карту матрицы корреляции. Сначала с дефолтными параметрами:
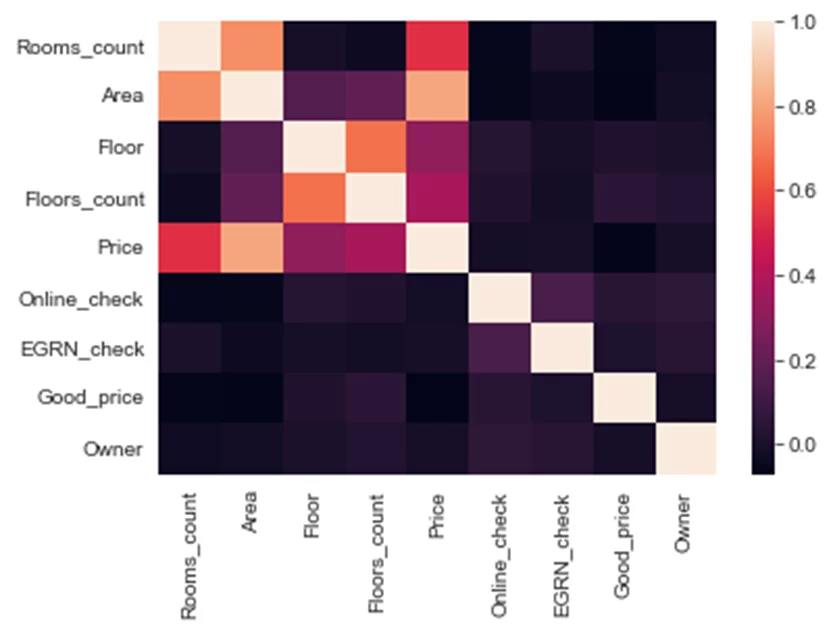
Кстати, символ «;» позволяет избавиться от подписи объекта.
Чем светлее секция — тем выше линейная зависимость признаков. Цена сильно зависит от площади и количества комнат, что очевидно. Увеличим график и поиграем с цветами:
plt.figure(figsize=(10, 7)) #задаем размер
cmap = sns.diverging_palette(200, 5, as_cmap=True) #цветовую палитру
mask = np.zeros_like(df.corr(), dtype=bool)
mask[np.triu_indices_from(mask)] = True #оставим половину карты (инфо дублируется)
sns.heatmap(df.corr(), mask=mask, cmap=cmap);
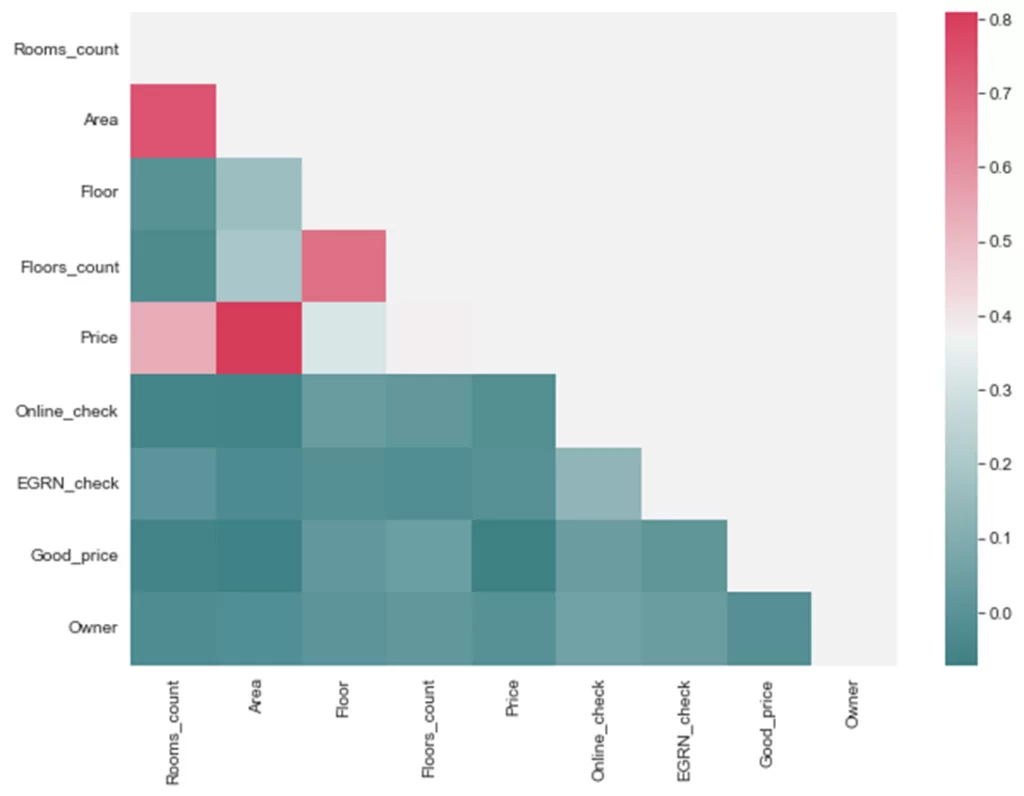
Теперь посмотрим на плотность распределения цен:
sns.kdeplot(df['Price']);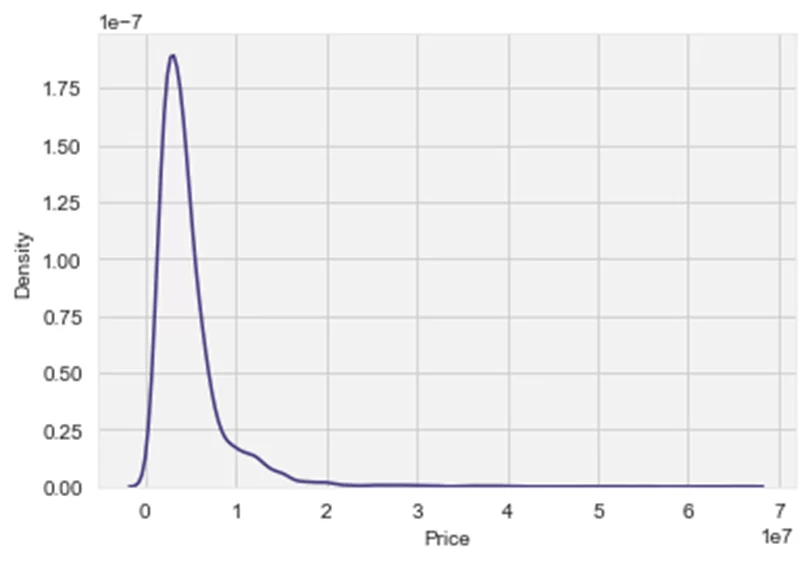
В разрезе количества комнат:
rooms = sorted(df[df['Rooms_count'].notnull()]['Rooms_count'].unique())
fig, ax = plt.subplots(len(rooms), 1, figsize=(15, 15), dpi = 500)
for r, idx in zip(rooms, range(len(rooms))):
sns.kdeplot(x = 'Price', data = df[df['Rooms_count'] == r], ax = ax[idx])
ax[idx].set(xlabel=None, ylabel=None)
ax[idx].set_title(f'Комнат: {int(r)}')
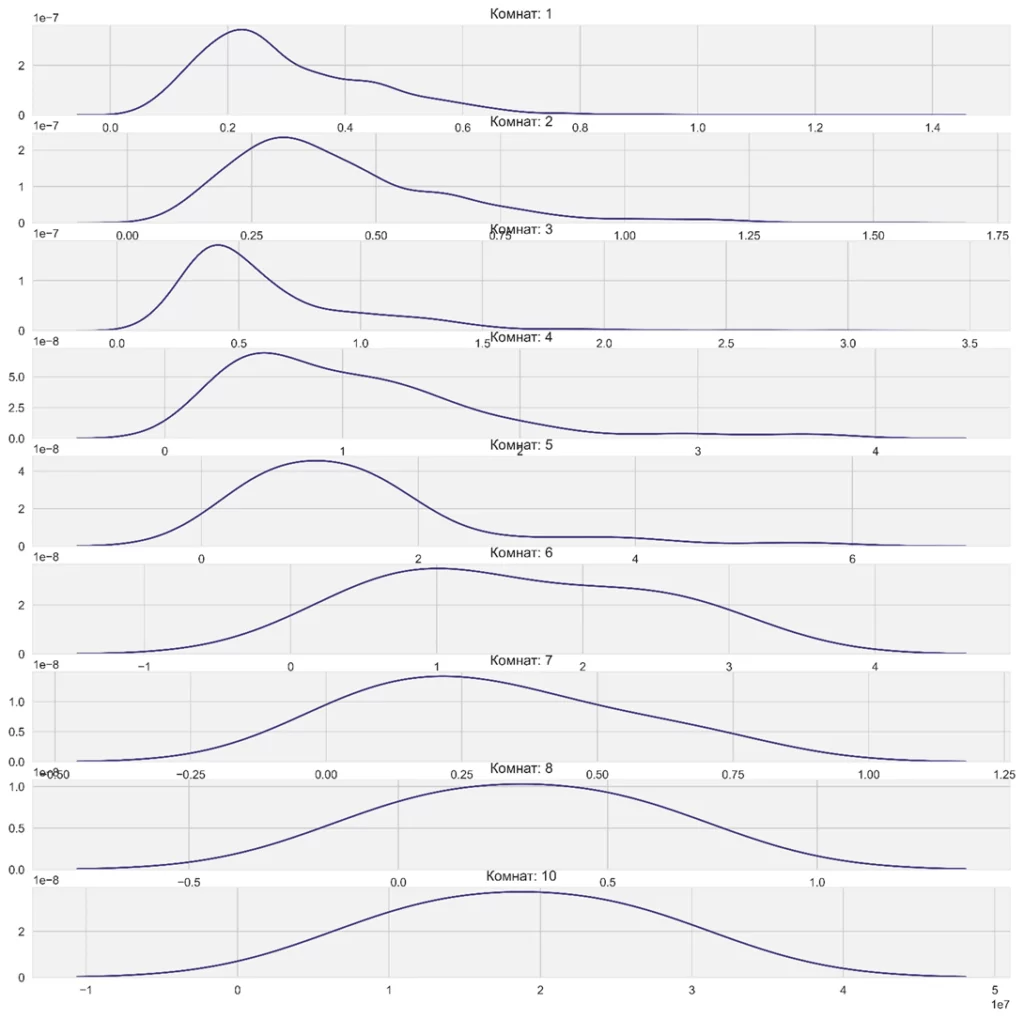
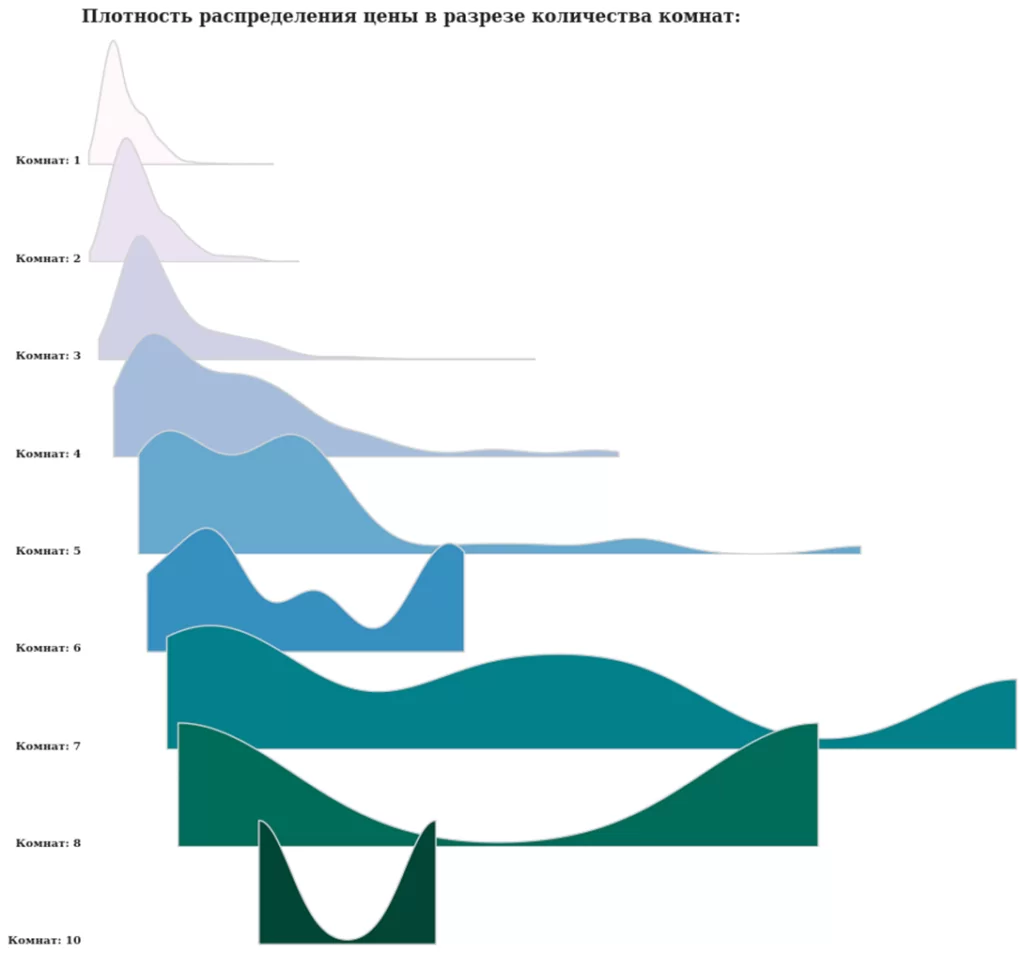
В глаза бросаются 2 вещи: несовпадение по оси Х и перекрытие названия снизу подписями по оси Х выше. Отрисуем заново через add_gridspec:
fig = plt.figure(figsize=(15, 15))
gs = fig.add_gridspec(len(rooms),1)
gs.update(hspace= -0.25)
axes = []
for idx, r in zip(range(len(rooms)), rooms):
axes.append(fig.add_subplot(gs[idx, 0]))
sns.kdeplot(x='Price', data=df[df['Rooms_count'] == r], #каждый график будет закрашен
fill=True, ax=axes[idx], cut=0, bw_method=0.25, #контур светло-серый
lw=1.4, edgecolor='lightgray', alpha=1)
axes[idx].set_xlim(0, max(df['Price']))#отмасштабируем графики по
#единой шкале Х
axes[idx].set_xticks([]) #по осям не будет шкал
axes[idx].set_yticks([])
axes[idx].set_ylabel('') #и подписей
axes[idx].set_xlabel('')
spines = ['top','right','left','bottom'] #и границ
for spine in spines:
axes[idx].spines[spine].set_visible(False)
axes[idx].patch.set_alpha(0)
axes[idx].text(0,0,f'Комнат: {int(r)}', fontweight='bold', fontfamily='serif',
fontsize=10, ha='right')
fig.text(0.125,0.89, 'Плотность распределения цены в разрезе количества комнат:', fontweight='bold', fontfamily='serif', fontsize=16);
В данном случае (мы смотрим на плотность распределения) нас интересует визуальная часть, поэтому абсолютными значениями и шкалами мы можем пренебречь:
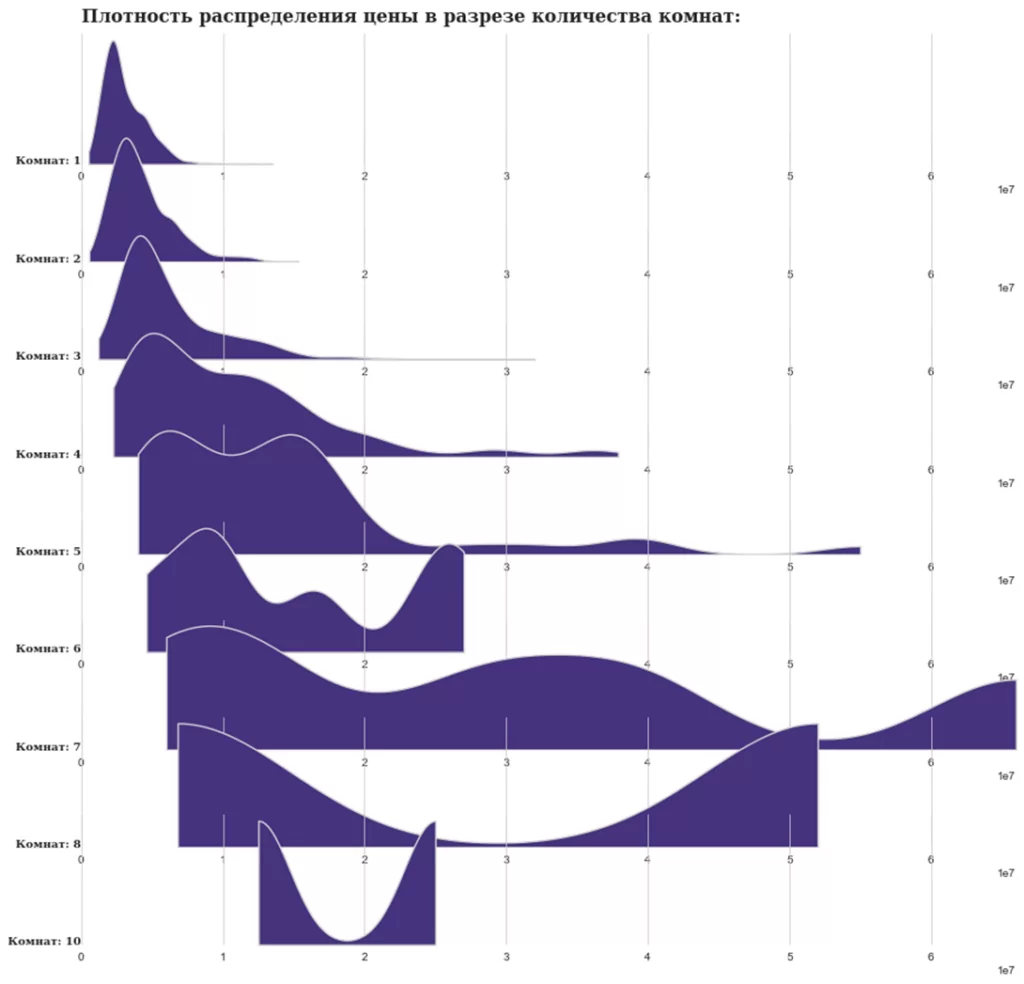
Добавим градиентную заливку. Для этого выберем colormap (например, PuBuGn) и с помощью функции get_cmap обратимся к нему и скажем, сколько хотим цветов (в нашем случае по количеству вариантов rooms):
matplotlib.cm.get_cmap('PuBuGn', len(rooms))
С помощью rgb2hex нужно перевести полученные цвета (они в формате rgba) в необходимый нам формат (hex):
matplotlib.cm.get_cmap('PuBuGn', len(rooms))
colors = []
for i in range(cmap.N):
rgb = cmap(i)[:3]
colors.append(matplotlib.colors.rgb2hex(rgb))
…и добавить в список, элементы которого мы будем передавать в качестве аргумента при построении графика:
fig = plt.figure(figsize=(15, 15))
gs = fig.add_gridspec(len(rooms),1)
gs.update(hspace= -0.25)
axes = []
for idx, r, c in zip(range(len(rooms)), rooms, colors): #список цветов
axes.append(fig.add_subplot(gs[idx, 0]))
sns.kdeplot(x='Price', data=df[df['Rooms_count'] == r],
fill=True, ax=axes[idx], cut=0, bw_method=0.25,
lw=1.4, color=c, edgecolor='lightgray', alpha=1) #передаем элементы в функцию
axes[idx].set_xlim(0, max(df['Price']))
axes[idx].set_xticks([])
axes[idx].set_yticks([])
axes[idx].set_ylabel('')
axes[idx].set_xlabel('')
spines = ['top','right','left','bottom']
for spine in spines:
axes[idx].spines[spine].set_visible(False)
axes[idx].patch.set_alpha(0)
axes[idx].text(0,0,f'Комнат: {int(r)}', fontweight='bold', fontfamily='serif',
fontsize=10, ha='right')
fig.text(0.125,0.89, 'Плотность распределения цены в разрезе количества комнат:', fontweight='bold', fontfamily='serif', fontsize=16);
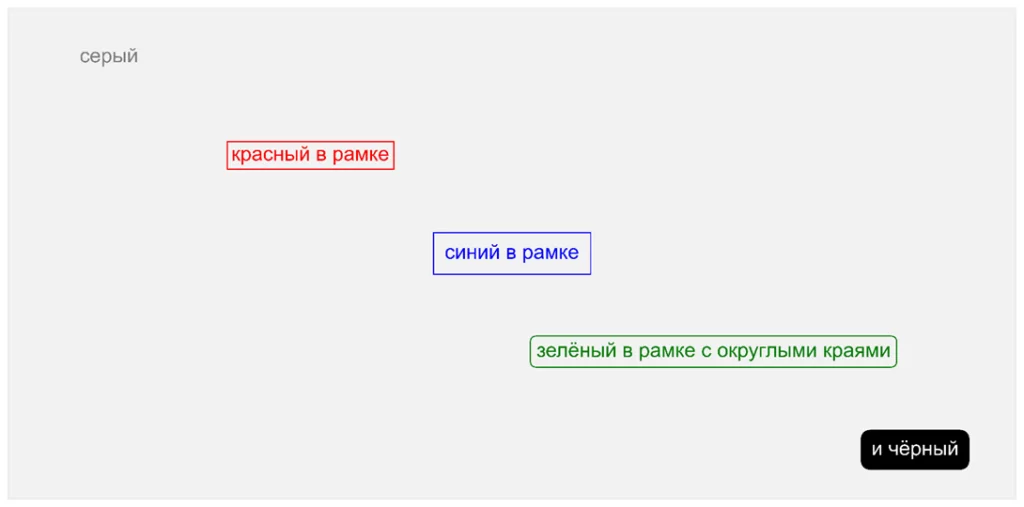
Также стоит остановиться у функции text – она позволяет без привязки к осям, заголовку или графику прокомментировать элемент:
fig, ax = plt.subplots(figsize=(16, 8), dpi=500) #фигура, размер, разрешение
ax.text(
0.1, #позиция по оси Х
0.9, #позиция по оси Y
'серый', #текст
color='gray', #цвет
va='center', #центрируем по вертикали
ha='center', #и горизонтали
fontsize=18 #размер шрифта
)
ax.text(0.3, 0.7, 'красный в рамке', color='red', va='center', ha='center', #аналогично + параметры рамки
bbox=dict(facecolor='none', edgecolor='red'), fontsize=18)
ax.text(0.5, 0.5, 'синий в рамке', color='blue', va='center', ha='center',
bbox=dict(facecolor='none', edgecolor='blue', pad=10.0), fontsize=18)
ax.text(0.7, 0.3, 'зелёный в рамке с округлыми краями', color='green', va='center', ha='center',
bbox=dict(facecolor='none', edgecolor='green', boxstyle='round'), fontsize=18)
ax.text(0.9, 0.1, 'и чёрный', color='white', va='center', ha='center',
bbox=dict(facecolor='black', edgecolor='black', boxstyle='round', pad=0.5), fontsize=18)
ax.set_xticks([])
ax.set_yticks([])
Как итог — библиотека matplotlib позволяет строить графики любых, даже самых сложных форм, а впоследствии настраивать их так, чтобы добиться максимальной читаемости и информативности.
PS. В matplotlib есть встроенный модуль xkcd (в честь известного комикса) — настройка позволяет отрисовывать графики в скетч-стиле:
with plt.xkcd():
fig = plt.figure(figsize=(10,7))
ax = fig.add_axes((0.1, 0.2, 0.8, 0.7))
ax.spines['right'].set_color('none') #убираем рамку справа
ax.spines['top'].set_color('none') #и слева
ax.set_xticks([]) #убираем подписи осей
ax.set_yticks([])
x = [i for i in range(15)]
y = [i**0.5 for i in x]
ax.plot(x,y)
ax.set_title('Learning Python:')
ax.set_xlabel('for funny drawing')
ax.set_ylabel('for being DS')