/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 4 мин.
PyCaret — достаточно свежая Python библиотека, предназначенная для машинного обучения. Она достаточно проста в использовании и интуитивно понятна. Сегодня постараемся разобраться в некоторых тонкостях данной библиотеки на примере встроенного в PyCaret датасета. Для начала установим библиотеку и проверим ее версию:
pip install pycaret
from pycaret.utils import version
version()
Актуальная на данный момент версия 2.3.1. Далее импортируем нужные модули с датасетами и классификацией, и выведем стандартные для этой библиотеки датасеты:
from pycaret.datasets import get_data
from pycaret.classification import *
index = get_data('index')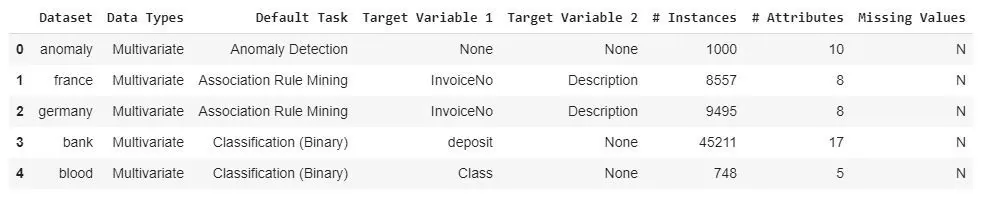
Разберем задачу классификации на датасете ‘Juice’ (размером в 1070 строк и 19 столбцов):
data = get_data('juice')
Датасет представляет из себя стандартный pandas dataframe.
Библиотека работает достаточно быстро, давайте посмотрим на свойства датафрейма, передадим в setup данные и целевую переменную:
clf = setup(data, target = 'Purchase', session_id = 1)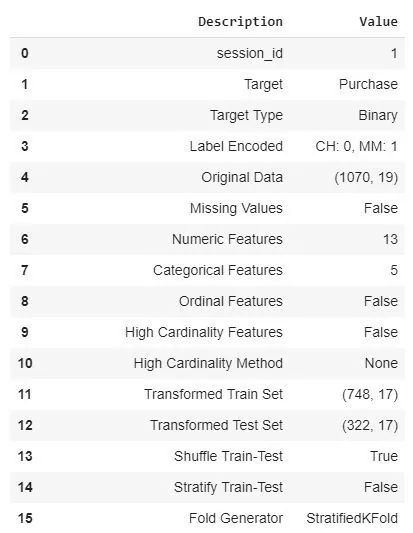
Узнаем информацию о задаче (бинарная классификация), пропущенных значениях, размерности (также размерности при делении на train и test), и многое другое (в нашем случае 58 строк различной информации).
Давайте найдем оптимальные модели для наших данных и сравним их:
%%time
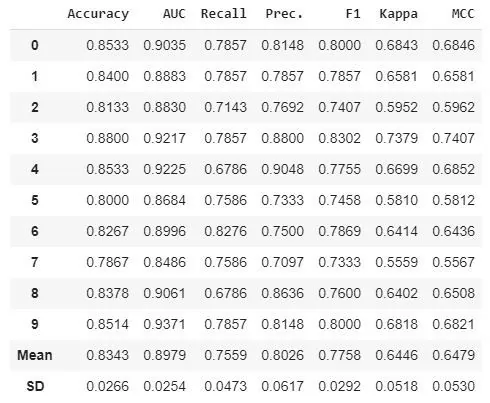
best_model = compare_models()
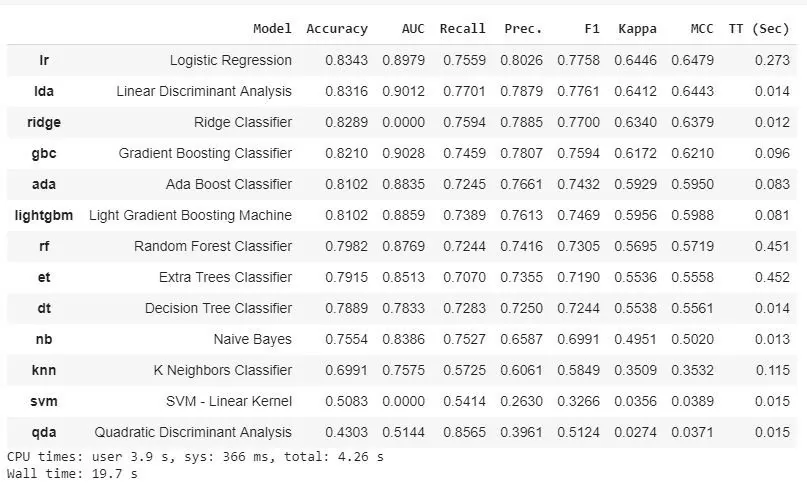
На выходе получаем результаты 13 различных моделей за 20 секунд. И все это в одну строчку кода. Модели разные — от логистической регрессии до наивного Байеса, а обучение происходит на 10 фолдах. В таблице указаны основные метрики (Accuracy, AUC, F1) и интересная информация о времени выполнения. В нашем случае логистическая регрессия показывает accuracy — 0.8343, а Ridge Classifier имеет 0.8289, но отрабатывает в несколько раз быстрее.
Для тех, кому хочется знать все, что “под капотом” у данных моделей:
models()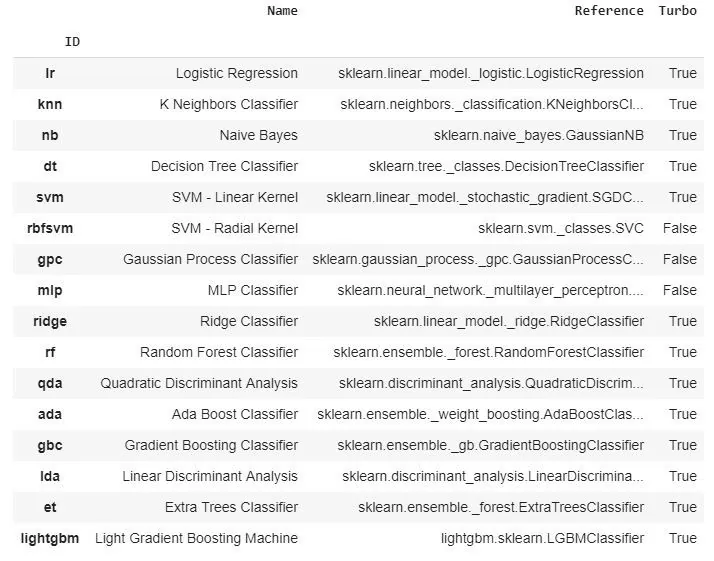
Видим библиотеки, с помощью которых и функционирует PyCaret.
Также можем создать отдельно модель (с самым высоким Accuracy) логистической регрессии и подробнее рассмотреть метрики полученные с помощью данной модели (построим ROC-кривую и матрицу ошибок):
lr = create_model(‘lr’)
plot_model(lr)
plot_model(lr, plot = 'confusion_matrix')

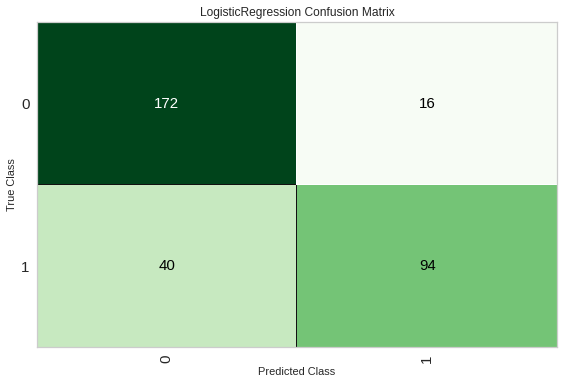
Хочется отметить, что графики получаются достаточно информативными и красивыми из коробки. Также можем построить график с feature importance и посмотреть на важность признаков:
plot_model(lr, plot = 'feature')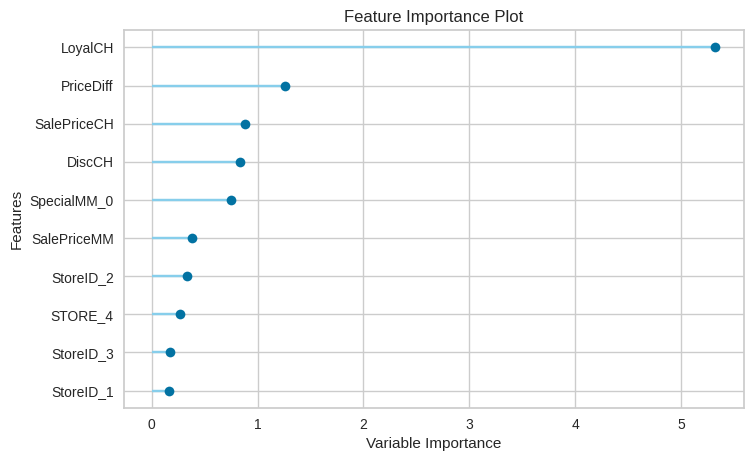
Ну и конечно можно сделать предсказание:
pred_holdouts = predict_model(lr)В итоге получаем очень мощный инструмент, который способен ускорить получение некого бейзлайна для некоторых задач. Конечно, стоит отметить, что в данной статье мы использовали датасет с 1 тысячей строк и все может быть не так радужно на больших наборах данных.