/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Парсинг – это автоматизированный сбор информации, её преобразование и выдача в структурированном виде.
Цель поста: рассмотреть парсинг данных сразу, непосредственно в приложение.
Эта публикация будет полезной для всех, кто только начинает знакомиться с Django и писать свои первые проекты.
Рассмотрю на примере приложения по поиску работы, данные буду брать с популярного сайта HeadHunter.
Первым шагом создам файл «parsers.py» в приложении.
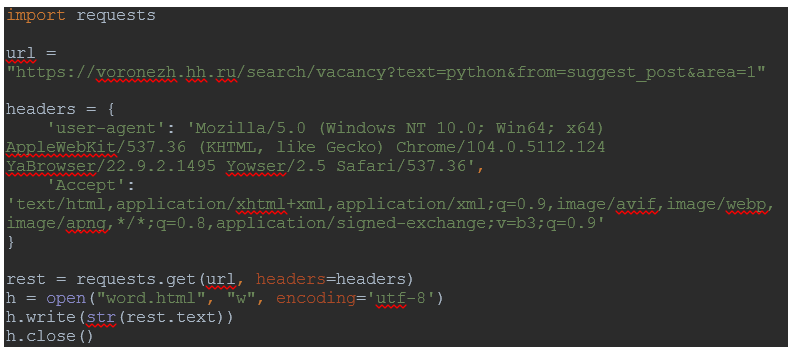
Прописываю данный код в файле и запускаю его. В приложении появится файл «work.html». Открываю созданный файл и вижу идентичную страницу hh.ru, url-адрес которой я указал. Простым языком, я скопировал нужную информацию сразу в приложение.
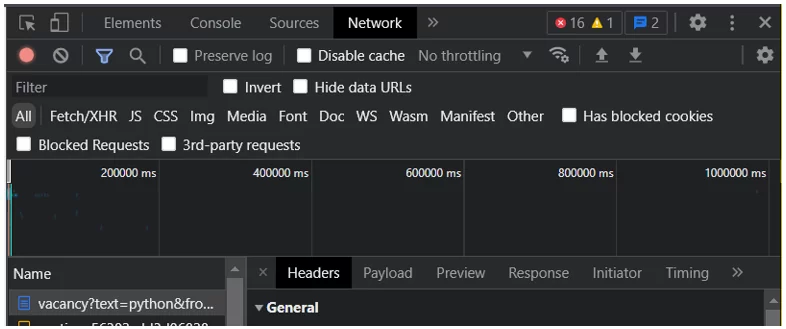
За отображение страницы отвечает словарь «headers», в нём указаны «user-agent» и «Accept». Эти данные беру с сайта hh.ru во вкладке «Network»
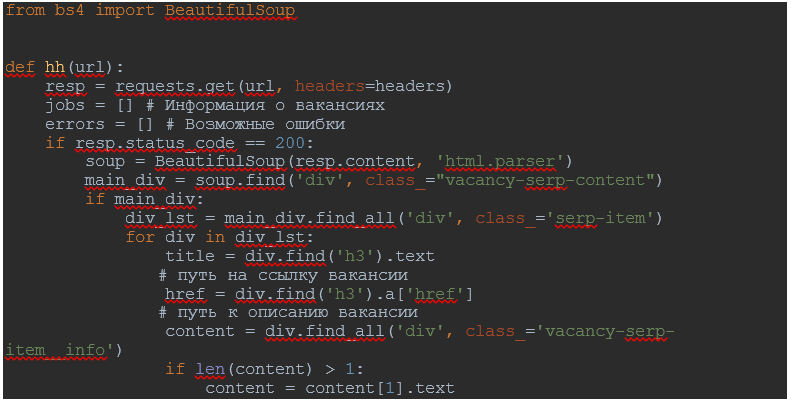
Далее напишу функцию, которая будет собирать всю нужную информацию о вакансиях.
Произведу импорт библиотеки для парсинга HTML и XML документов BeautifulSoup.
Создам два списка: список, в который буду помещать информацию о вакансии и список с возможными ошибками, чтобы во время работы сервер работал исправно.
В коде сайта нахожу html разметку, в которой находятся нужные поля, для того, чтобы прописать к ним путь.
Для наглядности возьму несколько полей: название вакансии, её описание, ссылку и компанию, которая эту вакансию предоставляет.
Сделаю дополнительные проверки для полей с описанием и компанией, так как бывают случаи, что они отсутствуют, этим самым исключу появление ошибок.
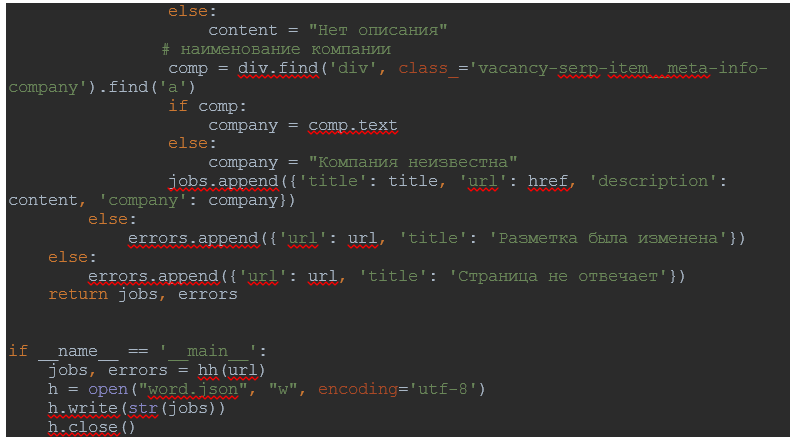
Меняю формат файла «word.html» на «word.json» и запускаю его. Если консоль не выдала никаких ошибок, в содержимом файла увижу списки с вакансиями, которые у меня получились. Таким образом, я выбрал только необходимые поля и наполнил приложение информацией.
Таким же образом я могу сделать несколько подобных функций для нескольких сайтов с вакансиями для более обширного поиска.
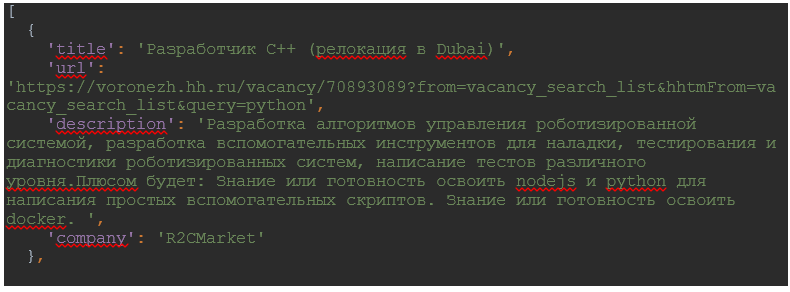
Списки с информацией есть, теперь их необходимо связать с приложением и базой данных.
В корне приложения создаю файл «run_service.py», пропишу в нём связь между Django и собранными данными.
Произведу необходимые импорты.


Покажу файлу “run_server” в каком конкретно приложении он находится. Простым языком, получаю его полный путь.
При помощи библиотеки «sys» добавляю системные пути. И покажу файлу из какого приложения ему брать необходимые настройки.
Методом «setup» свяжу файл с приложением Django.

После того как я связал информацию о вакансиях с приложением, импортирую ранее созданные модели. Если произвести импорт выше, связка работать не будет.

Пропишу «url» сайтов, с которых беру информацию о вакансиях.

Объявлю переменными города и языки программирования.
Создам два цикла, один из них будет собирать всю информацию в одно целое, а второй сохранять наши готовые вакансии в базу данных. Предусмотрю появление ошибок.
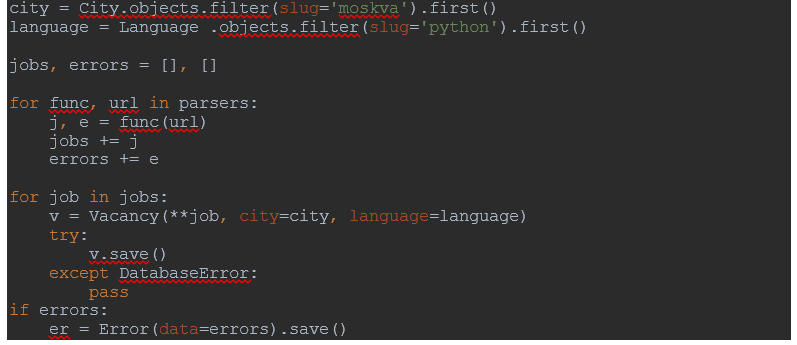
Запускаю сервер и делаю проверку приложения.
Выставляю параметры поиска.
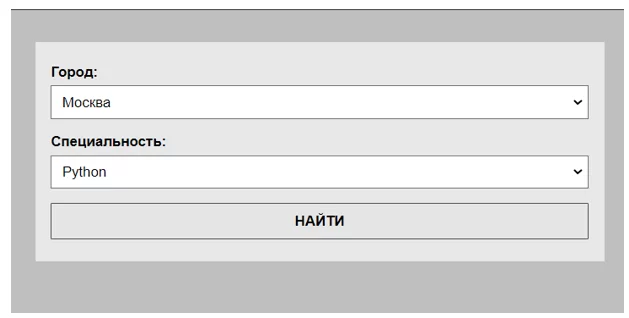
Получаю список вакансий.

Естественно, на оригинальных сайтах по поиску работы намного удобнее и эффективнее искать вакансии, но это приложение написано для наглядного примера реализации парсинга в Django.
В заключение можно сказать, что данный способ парсинга удобен в том случае, если вам необходимо быстро наполнить свое приложение информацией (если база данных отсутствует) для проверки его работоспособности, будь то интернет-магазин или сайт с публикациями.
Спасибо за уделённое время, удачи!