/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
У соцсети существует качественно оформленный API, обладающий серьезным функционалом для взаимодействия со сторонними сервисами. Гипотеза поиска человека была формализована следующим образом: потенциальный партнер имеет схожие интересы и имеет близкие нам музыкальные предпочтения. Звучит слишком абстрактно или нет?! Думаю нет, это как минимум важные параметры, чтобы найти темы для общения и слушать схожую музыку в поездках. Остальные особенности человека, такие как рост, вес, цвет волос, чувство юмора, темперамент, размер стопы и т.д. не фиксируются в соцсети и передаются на ручной анализ автору. Чтобы не сильно урезать выборку их можно назвать даже лишними.
Схема поиска схожих интересов сводится к поиску групп, аналогичным тем, где состоит сам автор. Эту задачу мы реализуем с помощью API VK.
pipinstallvk_api
import requests as r
import json
import time
import os
import re
import vk_api
from vk_api import audio
Подключаемся к сторонней библиотеке vk_api для генерации токена, который в свою очередь будет использован на официальном api VK.COM
login = input('Введителогиндляvk.com: ')
passw = input('Введитепарольдляvk.com: ')
VK = vk_api.VkApi(login, passw)
VK.auth()
VK = VK.get_api()
token = 0
try:
User = VK.users.get()
except:
print("Error")
else:
print(f"\nЗдравствуйте, {User[0]['first_name']}")
with open('vk_config.v2.json', 'r') as data_file:
data = json.load(data_file)
for xxx in data[login]['token'].keys():
app_id = re.findall('\d+',xxx)[0]
for yyy in data[login]['token'][xxx].keys():
token = data[login]['token'][xxx][yyy]['access_token']
user_id = data[login]['token'][xxx][yyy]['user_id']
print(f"User_id: {user_id}")
print(f"App_id: {app_id}")
print(f"Token: {token}")
os.remove('vk_config.v2.json')
На компьютерах MAC может наблюдаться проблема с генерацией токена. Получить его можно также через сервис https://vkhost.github.io. USER_ID — цифры вашего ID VK
user_id = 63451711Получаем список групп, на которые мы подписаны.
linkg = f'https://api.vk.com/method/groups.get?user_id={user_id}&count=1000&access_token={token}&v=5.131'
mygroups= r.get(linkg).json()
group_list = mygroups['response']['items']
print(group_list)
print('len(print(group_list)=',len(group_list))
link0 = f'https://api.vk.com/method/groups.getMembers?uid={user_id}&group_id=22558194&count=1&offset=0&sort=id_asc&access_token={token}&v=5.131'
members_id_list= r.get(link0).json()
members_id_list
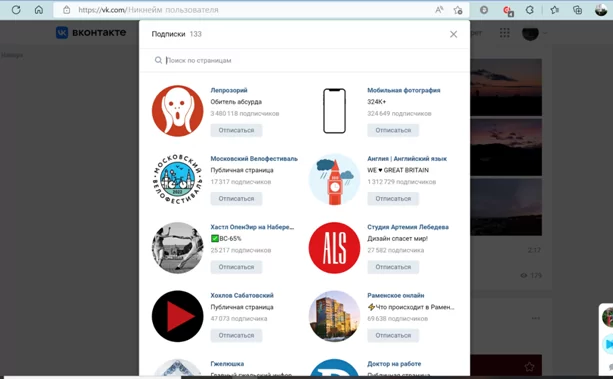
Вот так выглядит список групп, если мы смотрим в VK:
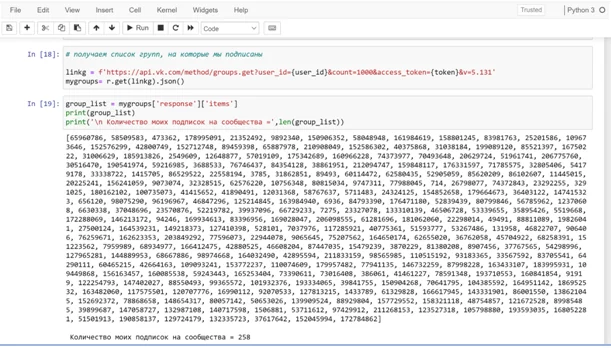
А при запуске кода, все сообщества, на которые мы подписаны, будут представлены в виде числовых идентификаторов:
API VK имеет ограничения по количеству обращений к методам, поэтому будем рассматривать небольшие по составу сообщества от 1000 до 40000 чел. В целом это даже имеет смысл так как обычно большие группы теряют некую индивидуальность по набору участников и публикуемому контенту.
def get_list_little_groups(group_list):
list_little_groups=[]
closed_group_ids = []
for group_id in group_list:
link0 = f'https://api.vk.com/method/groups.getMembers?user_id={user_id}&group_id={group_id}&count=1&offset=0&sort=id_asc&access_token={token}&v=5.131'
members_id_list= r.get(link0).json()
time.sleep(0.5)
try:
members_count = members_id_list['response']['count']
print('group_id =', group_id , 'count_members = ',members_count)
if members_count>1000 and members_count<60000:
list_little_groups.append(group_id)
except:
closed_group_ids.append(group_id)
print('group_id = ',group_id,'count members not found')
print(list_little_groups)
print(len(list_little_groups))
print('closed_group_ids:',closed_group_ids)
return list_little_groups,closed_group_ids
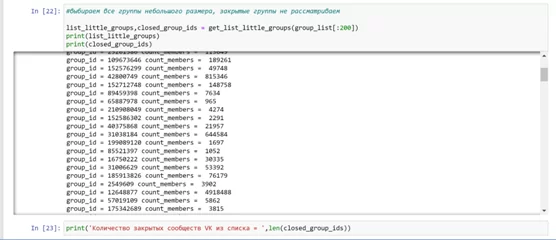
Выбираем все группы небольшого размера, закрытые группы не рассматриваем.
list_little_groups,closed_group_ids = get_list_little_groups(group_list[:200])
print(list_little_groups)
print(closed_group_ids)
У вас сформируется список сообществ и количеством участников.
print('Количество закрытых сообществ VK из списка = ',len(closed_group_ids))
print('Количество выбранных сообществ VK для анализа = ',len(list_little_groups))
# получаем массив всех пользователей всех выбранных ранее сообществ
dict_group_members={}
all_members = []
count =0
i=0
print(token)
for littlegroup_id in list_little_groups[:100]:
count+=1
print(count)
print(littlegroup_id)
all_comunity_members = []
a=0
for i in range(50):
link = f'https://api.vk.com/method/groups.getMembers?user_id={user_id}&group_id={littlegroup_id}&count=1000&offset={i*1000}&sort=id_asc&access_token={token}&v=5.131'
try:
time.sleep(0.2)
members_id_list= r.get(link).json()
all_comunity_members= all_comunity_members+members_id_list['response']['items'] список id людей состоящих в сообществе
print(len(all_comunity_members))
if len(members_id_list['response']['items'])==0:
break
except:
continue
continue
all_members = all_members+all_comunity_members
dict_group_members[littlegroup_id]=all_comunity_members
print('count group members = ',len(all_members))
Считаем количество повторений ID пользователя в разных группах. Пользователи с максимальным присутствием в исходных группах и есть целевая аудитория.
Создаем объект, подсчитывающий количество повторений USER_ID (all_members)
from collections import Counter
c = Counter(all_members)
Создаем словарь, упорядоченный по количеству повторений одного и того же USER_ID в исходных группах.
dict_members = dict(sorted(c.items(), key=lambda item: item[1],reverse = True))
dict_members
После запуска кода, будет сформирован список с ID пользователей и количеством сообществ, в которых они пересекаются с вами. Уже на данном этапе можно скопировать ID пользователя, у которого максимальное количество пересечений. Результаты группировки выглядят следующим образом:
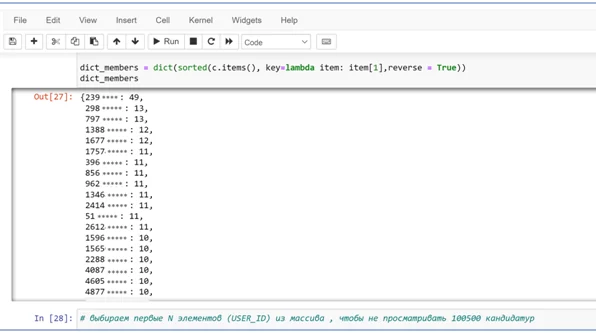
Далее выбираем первые N элементов (USER_ID) из массива
target_user_list = list(dict_members.keys())[:400]
for user in target_user_list:
print(user)
Создаем новый список, где оставляем только женщин (1-маркер женского пола, 2 — мужского)
list_of_women = []
count=0
for id in target_user_list:
count+=1
if count % 10==0:
print(count)
try:
link = f'https://api.vk.com/method/users.get?user_ids={id}&fields=sex&sort=id_asc&access_token={token}&v=5.131'
user_info= r.get(link).json()
if user_info['response'][0]['sex']==1:
list_of_women.append(id)
except:
continue
print(list_of_women)
print(len(list_of_women))
wl = list_of_women.copy()
len(wl)
wl
list_of_women = wl.copy()
list_of_women
len(list_of_women)
Удаляем женщин с закрытым профилем и тех, кто подписан на большое множество групп (более 2000 групп).
print(list_of_women)
short_list_of_women = []
for woman_id in list_of_women:
linkw1 = f'https://api.vk.com/method/groups.get?user_id={woman_id}&count=1&access_token={token}&v=5.131'
print(woman_id)
try:
time.sleep(0.5)
woman_groups = r.get(linkw1).json()
women_groups_count = woman_groups['response']['count']
print(woman_id, women_groups_count)
ifwomen_groups_count>2000:
Если у человека больше 2000 групп в подписках удалить его из целевой выборки можно следующим образом.
print('ERROR: women_groups_count>2000')
continue
except:
pass
try:
print('ERROR: ', woman_groups['error']['error_msg'])
continue
except:
short_list_of_women.append(woman_id)
print(short_list_of_women)
print(short_list_of_women)
woman_id = 40053517
linkw1 = f'https://api.vk.com/method/groups.get?user_id={woman_id}&count=1&access_token={token}&v=5.131'
woman_groups = r.get(linkw1).json()
woman_groups
print('Длина списка женщин = ', len(short_list_of_women))
for woman_id in short_list_of_women:
try:
print(woman_id)
print(f'https://vk.com/id{woman_id}')
link = f'https://api.vk.com/method/users.get?user_ids={woman_id}&fields=sex&fields=photo_400_orig&sort=id_asc&access_token={token}&v=5.131'
user_info= r.get(link).json()
except:
continue
from time import time
После запуска, система сформируют список ID с ссылками на VK.
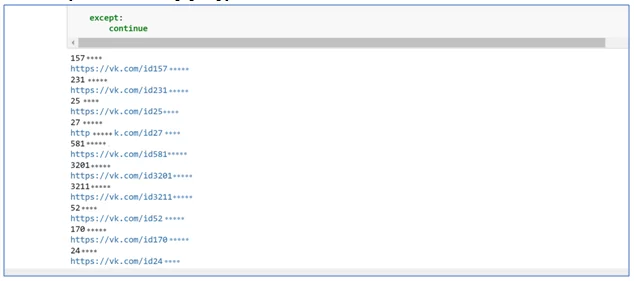
Просмотрев все предложенные варианты можно уже выбрать несколько человек и попробовать завязать с ними общение😊 Но мы пойдем дальше и проверим их на совместимость по музыкальным вкусам.
Для этого вводим ID пользователя VK с открытыми аудиозаписями (номер идет после слова id, например https://vk.com/id0000000) или находим ID через сервис на сайте https://regvk.com/id/? (подходит, если у вас есть ссылка следующего типа https://vk.com/никнейм пользователя)
whileTrue:
try:
id = int(input('Введите ID пользователя VK для сканирования его аудиозаписей : '))
break
except:
pass
REQUEST_STATUS_CODE = 200
login = input('Введите логин для vk.com: ')
passw = input('Введите пароль для vk.com: ')
После авторизации, запускаем сканирование аудиозаписей одним из способов. Сканирование аудиозаписей в среднем занимает около 5 минут.
Первый способ — сканирование по частям:
vk_session = vk_api.VkApi(login=login, password=passw)
vk_session.auth()
vk = vk_session.get_api()
vk_audio = audio.VkAudio(vk_session)
print('AUTHORISATION COMPLETED')
a = 0
time_start = time()
artist_list = []
track_list_object = vk_audio.get_iter(owner_id=id)
print('READY!')
for i in track_list_object:
try:
a += 1
artist_list.append(i["artist"])
# print(i["artist"])
except :
print(f'artist {i} was passed')
time_finish = time()
print('artist_list_len = ', len(artist_list))
print("Parsing time:", time_finish - time_start)
Второй способ сканирования аудио в один заход:
# vk_session = vk_api.VkApi(login=login, password=passw)
# vk_session.auth()
# vk = vk_session.get_api()
# vk_audio = audio.VkAudio(vk_session)
# print('AUTHORISATION COMPLETED')
# a = 0
# time_start = time()
# artist_list = []
# track_list_object = vk_audio.get(owner_id=id)
# print('READY!')
# for i in track_list_object:
# try:
# a += 1
# artist_list.append(i["artist"])
# except OSError:
# print(f'artist {i} was passed')
# time_finish = time()
# print('artist_list_len = ', len(artist_list))
# print("Parsing time:", time_finish - time_start)
from collections import Counter
cc = Counter(artist_list)
После сканирования формируется список наименований музыкальных треков пользователя. Упорядочим этот список от наиболее часто встречающихся исполнителей к менее. Для этого создадим словарь, упорядоченный по количеству повторений исполнителя в плейлисте подходящего нам кандидата.
artist_list_ordered = dict(sorted(cc.items(), key=lambda item: item[1],reverse = True))
artist_list_ordered
Результат будет представлен в следующем виде. Удобно, неправда ли. Сразу видны музыкальные предпочтения пользователя.
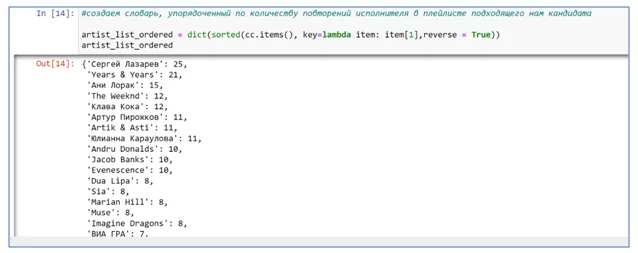
А это классический вариант изучения музыкальных вкусов
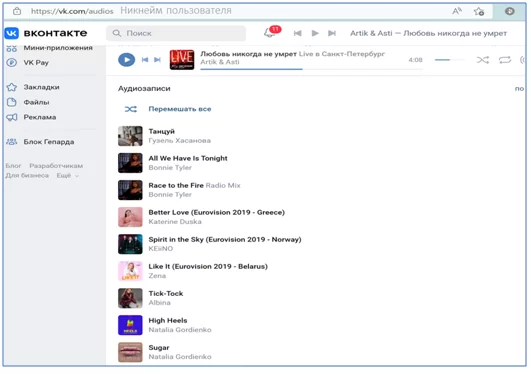
Исходя из полученных результатов можно понять подходит ли вам этот человек по музыкальным предпочтениям или нет. Удачных поисков, и пусть современные технологии сохранят ваше личное время и помогут расширить круг друзей.