/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
В данной задаче мне потребовалось получить информацию как с сайта наш.дом.рф, так и с PDF файлов проектных деклараций, загруженных на этом сайте. Оба шага сопровождались поиском эффективного решения.
Получение информации с сайта
Данные, получаемые в рамках задачи брались как непосредственно с сайта, так и из проектных деклараций, доступных для скачивания, и в первой части поста я расскажу про работу с сайтом.
При первом взгляде на проблему часто возникает желание прибегнуть к стандартным способам получения данных, например, Selenium или BeautifulSoup. Получая данные о содержимом страницы можно выгрузить всю требуемую информацию, даже если для её загрузки требуется ожидать выполнение скриптов, подгружающих туда данные. Однако, в таком случае потребуется ожидать подгрузки каждой страницы целиком, что может быть очень затратно по времени, так как загружается много дополнительно ненужной информации.
Вместо этого можно обратить внимание на то, как информация передаётся на страницу. Зачастую для этого используются пакеты данных в формате json, возвращаемые по запросу с ключевыми параметрами. Именно такую схему видим на сайте наш.дом.рф:
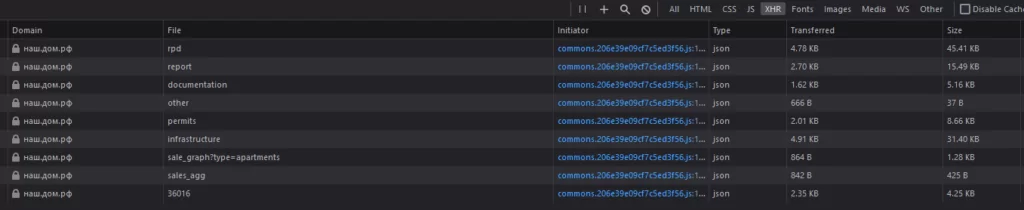
Можно установить, какой из пакетов содержит необходимую информацию, и каким запросом формируется, посмотрев содержимое:
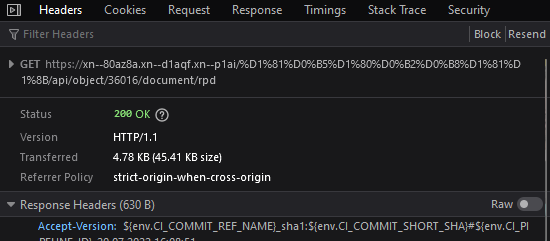
Для получения результатов запроса используется библиотека Response:
def getDocumentList(building_id):
documents = []
url_doc_list = 'https://наш.дом.рф/сервисы/api/object/'+building_id +'/document/rpd'
url_doc_list = 'https://наш.дом.рф/сервисы/api/object/'+building_id +'/document/rpd'
try:
response = requests.get(url_doc_list)
documents = response.json()
documents = documents['data']
except Exception as e:
print(e)
return [{'Error':'Сбой загрузки'}]
Также с её помощью можно передавать в запрос параметры, если они там присутствуют:
def getBuildingList(inn = ''):
data = []
problem_reasons = []
url_house_list = 'https://наш.дом.рф/сервисы/api/kn/object'
params = (
('offset', 0),
('limit', 200),
('searchValue', inn),
('search', inn)
)
df_buildings = pd.DataFrame()
response = requests.get(url_house_list, params=params)
reestr = response.json()
Использование такого подхода позволяет резко сократить объём загружаемой информации: например, загрузка страницы с информацией о списке объектов строительства у застройщика занимает 770 кб, а json-объект этой же страницы всего 6 кб. Подобные подходы полезно применять при анализе способов загрузки данных с любых сайтов.
Обработка pdf-документов.
Дополнительно в рамках задачи было необходимо провести выгрузку данных из pdf-документов, для чего требовалось определить самый удобный способ их обработки. Данные в документах представлены в табличном виде и, на первый взгляд, наиболее оптимальным способом было использование библиотеки Tabula, предназначенной для распознавания табличных данных.
tables = tabula.read_pdf('temp.pdf', pages='all', pandas_options={'header': None})Однако, при попытке её использования пришлось столкнуться с рядом проблем. Во-первых, в форматировании таблиц допускались вариации, которые приводили к некорректному распознаванию данных на странице и не позволяли подкорректировать работу библиотеки под нужный формат, а во-вторых, сам процесс обработки файла занимал значительное время, превышая время загрузки в 3-5 раз. Распознавание большого количества документов приводило к увеличению продолжительности времени обработки.

Был рассмотрен альтернативный способ обработки pdf: с использованием модуля fitz библиотеки PyMyPdf. Данный модуль поддерживает несколько разных способов распознавания данных, а также куда быстрее считывает текст с файла, так как не формирует на выходе таблицу, готовую к использованию.
with fitz.open('pdf\\' +filepath) as doc:
text = []
for page in doc:
text += page.get_text('blocks')
Данный код служит для «блочной» выгрузки текста, где блоки соответствуют ячейкам таблицы и результат записывается в словарь. Подобный подход позволил на порядок сократить время обработки одного файла, с 4-6 секунд на файл размером ~300 кб до десятых долей секунды, не теряя при этом полезную информацию.
Таким образом, правильный выбор способов загрузки и обработки данных позволил значительно сократить время, затраченное на получение требуемой информации с сайта. Использование кажущихся очевидными и стандартными решения не всегда являются эффективными, и при разработке следует анализировать возможности использования других решений, для повышения эффективности и правильности работы программ.