/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Задача сбора данных из открытых источников возникает довольно часто, а основным фактором, влияющим на скорость её решения, выступает объём данных, порождающий большее количество обращений к источнику по сети, причём основное количество времени, затрачиваемого на работу с сетью, занимает ожидание ответа от источника.
Уменьшить время ожидания ответа при работе с сетью можно используя подходящие программные модели. Например, в случае многопоточного выполнения, подзадачи программы могут быть распределены между потоками.
Для примера, соберу достаточно большое количество стихов поэтов-классиков из открытого источника, оценю затраченное время и ускорю процесс сбора. Использовать буду Python, модули: bs4, json, os, queue, requests, time и threading.
Итак, перехожу по первой ссылке из поисковика:
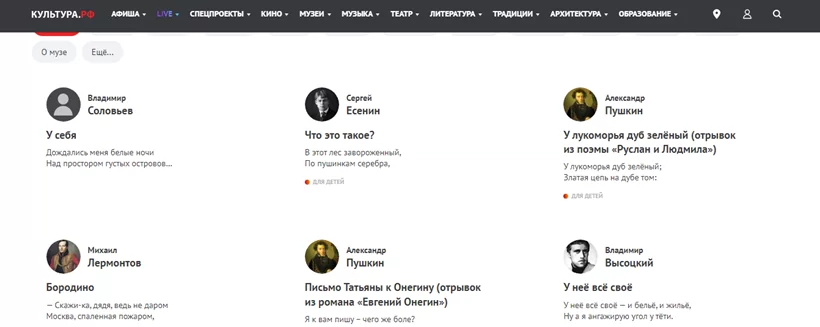
После изучения внешнего вида страницы, можно сделать вывод о том, что сортировки по авторам нет и произведения одного автора могут встретиться как на первой, так и на последней страницах, учту это.
Открываю инструменты разработчика, иду на вкладку «сеть», открываю страницу любого автора:
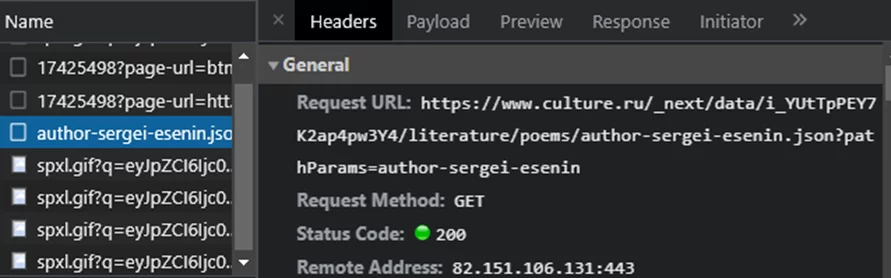
Нашёлся адрес, при отправке запроса, на который, вернётся json с произведениями определённого параметрами запроса автора.
Импорты:
from bs4 import BeautifulSoup
import json
import os
import requests
import time
В рамках функции, выгружающей произведения по одному автору, перейду по нескольким ссылкам, чтобы набрать cookie, изменю стандартные для модуля requests заголовки, буду циклично отправлять запросы и разбирать json-ответы, сохраняя их в файл:
def getForAuthor(sess, author):
urls = ["https://www.google.ru/", "https://www.youtube.com/"]
for i in urls:
sess.get(url=i)
headers = {
"accept": "*/*",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
result = {}
page = 1
while True:
url = f"https://www.culture.ru/_next/data/i_YUtTpPEY7K2ap4pw3Y4/literature/poems/{author}.json?pathParams=author-sergei-esenin"
params = {
"pathParams": author,
"page": page
}
while True:
try:
res = sess.get(
url=url,
params=params,
headers=headers
)
break
except Exception as ex:
print(ex)
js = res.json()
maxPage = js["pageProps"]["pagination"]["total"]
for item in js["pageProps"]["poems"]:
result[item["_id"]] = {
"id": item["_id"],
"title": item["title"],
"text": item["text"]
}
if page == maxPage:
break
page += 1
with open(f"./data/{author}.json", "w", encoding="utf-8") as file:
file.write(json.dumps(result, ensure_ascii=False, indent=4))
Запуск:
if __name__ == "__main__":
start = 1
stop = 2
sess = requests.Session()
authors = []
maxPage = int(getMaxPage(sess=sess))
print(maxPage)
start = time.time(
for page in range(start, stop)):
print(page)
url = f"https://www.culture.ru/literature/poems?page={page}"
while True:
try:
res = sess.get(url=url)
break
except Exception as ex:
print(ex)
soup = BeautifulSoup(res.text, "html.parser")
athrs = soup.find_all(attrs={"class": "_6unAn"})
for author in athrs:
author = author.get("href").replace("/literature/poems/", "")
os.system("cls")
if author not in authors:
authors.append(author)
print(len(authors))
for a in authors:
os.system("cls")
print(a)
getForAuthor(sess = sess, author = a)
print("Done for", time.time() - start, "seconds", len(authors))
Результаты сохранились:
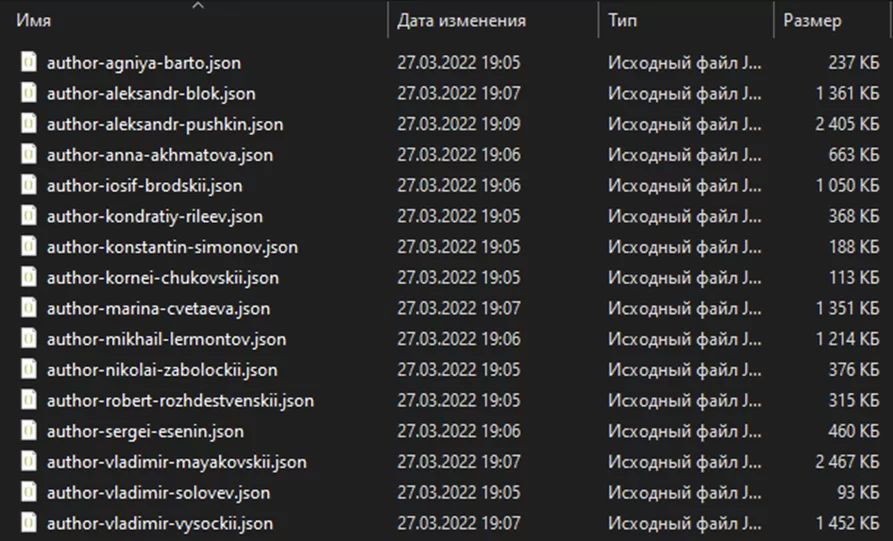
Загляну в один из файлов, чтобы убедиться, что всё записано так, как ожидалось:
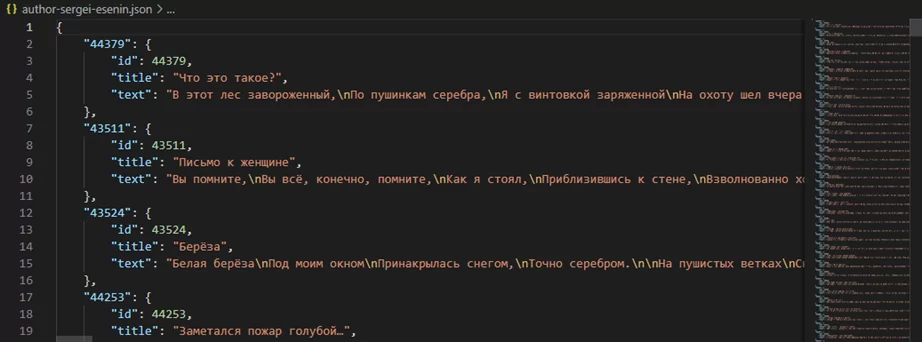
Как можно было заметить ранее, результат выгружен только по шестнадцати авторам с первой страницы сайта, и это заняло около семи минут.

Почему так долго? И что происходит при отправке запроса дольше всего? Ожидание.
Для того, чтобы повысить производительность необходимо воспользоваться модулем threading: с его помощью запущу потоки, выгружающие произведения по одному автору в одном процессе. При переходе одного потока в состояние ожидания, будет выполняться другой, таким образом время ожидания уменьшится. Для обмена данными с потоком будет использоваться очередь из модуля queue.
Частично перепишу предыдущий скрипт.
Импорты:
from bs4 import BeautifulSoup
import json
import os
from queue import Queue
import requests
import time
import threading
Функция, которая будет работать в потоке:
def getForAuthor(task):
sess = requests.Session()
urls = ["https://www.google.ru/", "https://www.youtube.com/"]
for i in urls:
sess.get(url=i)
headers = {
"accept": "*/*",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.84 Safari/537.36"
}
result = {}
page = 1
if not task.empty():
author = task.get()
page = 1
while True:
url = f"https://www.culture.ru/_next/data/i_YUtTpPEY7K2ap4pw3Y4/literature/poems/{author}.json?pathParams=author-sergei-esenin"
params = {
"pathParams": author,
"page": page
}
while True:
try:
res = sess.get(
url=url,
params=params,
headers=headers
)
break
except Exception as ex:
print(ex)
js = res.json()
maxPage = js["pageProps"]["pagination"]["total"]
for item in js["pageProps"]["poems"]:
result[item["_id"]] = {
"id": item["_id"],
"title": item["title"],
"text": item["text"]
}
if page == maxPage:
break
page += 1
with open(f"./data/{author}.json", "w", encoding="utf-8") as file:
file.write(json.dumps(result, ensure_ascii=False, indent=4))
Запуск:
if __name__ == "__main__":
start = 1
stop = 2
sess = requests.Session()
authors = []
# создание экземпляра класса очереди
task = Queue()
start = time.time()
for page in range(start, stop):
print(page)
url = f"https://www.culture.ru/literature/poems?page={page}"
while True:
try:
res = sess.get(url=url)
break
except Exception as ex:
print(ex)
soup = BeautifulSoup(res.text, "html.parser")
athrs = soup.find_all(attrs={"class": "_6unAn"})
for author in athrs:
author = author.get("href").replace("/literature/poems/", "")
os.system("cls")
if author not in authors:
authors.append(author)
# заполнение очереди
for a in authors:
task.put(a)
# запуск потоков
for _ in range(len(authors)):
threading.Thread(target=getForAuthor, args=(task,)).start()
# цикл с условием останова для родительского потока
while True:
if threading.active_count() == 1:
break
print("Threading done for", time.time() - start, "seconds", len(authors))
Вывод по окончанию работы, одна страница, те же шестнадцать авторов:

По полученным результатам можно сделать вывод, что достались те же самые данные, но, при этом, сократилось время исполнения почти в два раза. А можно ещё быстрее? Можно, если более детально продумать процессы сбора и обработки данных из очереди.
С помощью модуля threading можно повысить производительность не только при работе с сетью, но и в любых задачах, связанных с вводом-выводом.