/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)
Время прочтения: 4 мин.
Бывает так, что очень большая модель не помещается на видеоадаптере и требуется 250 ГБ оперативной памяти. В этой связи надо находить баланс, можно уменьшить размер модели в сто раз и, при этом, уменьшить точность всего на половину процентного пункта. Например, Bert можно сжать с 560 Мб до 2 Мб, почти без потери качества.
Рассмотрю три наиболее часто встречающихся метода оптимизации размера сети такие как дистилляция, квантизация и прунинг.
Дистилляция
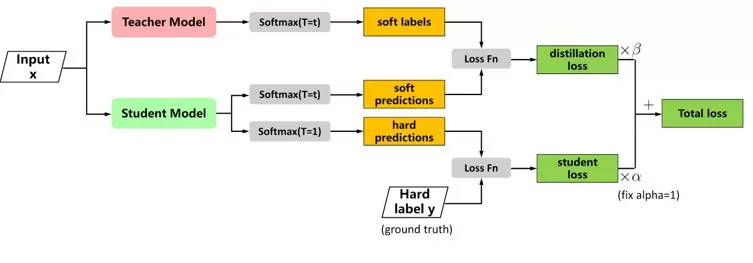
Основная идея дистилляции — это обучение маленькой модели (модели студента) с помощью предобученной большой модели (модели учителя). У меня есть предобученная модель «учитель», она выдаёт логиты, это последний слой до Softmax. И есть модель студента, только необученная, которая выдает логиты, такой же размерности. Далее логиты учителя и логиты студента, прогоняются через Softmax с температурой. Температура нужна для сглаживания распределения.
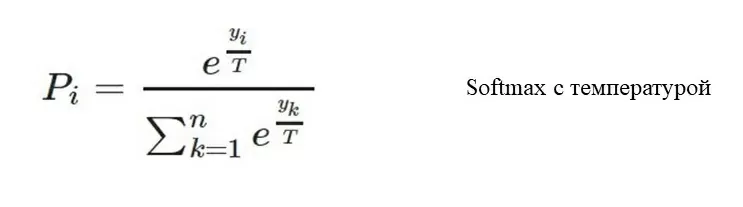
Логиты модели-студента отправляются на Softmax как с температурой, так и без температуры.
При Softmax без температуры получаю классическую модель-студент обучения и обычную функцию потерь. Эту функцию возьму с коэффициентом альфа.
При Softmax с температурой сравнивается модель учителя и модель студента дивергенцией Кульбака – Лейблера и этот loss берется с коэффициентом бетта. Потом складывается два loss как на схеме выше и от него берется backward (обратное распределение потерь). Пример кода представлен ниже.
def loss_fn_kd(outputs, labels, teacher_outputs, params): #дивергенция Кульбака – Лейблера
alpha , betta = params.alpha , params.betta
T = params.temperature
KD_loss = nn.KLDivLoss()(F.log_softmax(outputs/T, dim=1),
F.softmax(teacher_outputs/T, dim=1)) * (alpha * T * T) + \
F.cross_entropy(outputs, labels) * (betta)
return KD_loss
with torch.no_grad():
output_teacher_batch = teacher_model(train_batch)
if params.cuda:
output_teacher_batch = output_teacher_batch.cuda(async=True)
loss = loss_fn_kd(output_batch, labels_batch, output_teacher_batch, params)
optimizer.zero_grad()
loss.backward()
Иначе говоря, вместо классической функции потерь, для обучения модели-студента, применяется средневзвешенная функция потерь с реальными данными и с теми что выдает модель учитель.
Квантизация
Идея квантизации предельно проста — все операции проводятся в целочисленных значениях. Чаще всего это накладывается на слой или на какую-то часть сети. Ряд слоёв работает в int8, благодаря чему он потребляет очень мало вычислений и памяти, последний слой, float32. Самый простой способ — это округление весов к определённым значениям.
Квантизовать можно до, после и во время обучения. Приведу пример простой квантизации для однослойной модели и четырех нейронов с четырьмя признаками
import torch
# определяем модель
class M(torch.nn.Module):
def __init__(self):
super(M, self).__init__()
self.fc = torch.nn.Linear(4, 4)
def forward(self, x):
x = self.fc(x)
return x
# создаём модель
model_fp32 = M()
# создаём квантизованную модель с динамической квантизацией
model_int8 = torch.quantization.quantize_dynamic(
model_fp32, # оригинальная модель
{torch.nn.Linear}, # количество слоев для квантизации
dtype=torch.qint8) # количество бит
# Запуск модели
input_fp32 = torch.randn(4, 4, 4, 4)
res = model_int8(input_fp32)Кроме того, можно квантизовать уже дистиллированную модель, что ещё больше сэкономит время и вычислительные ресурсы, практически без серьёзной потери качества.
Прунинг
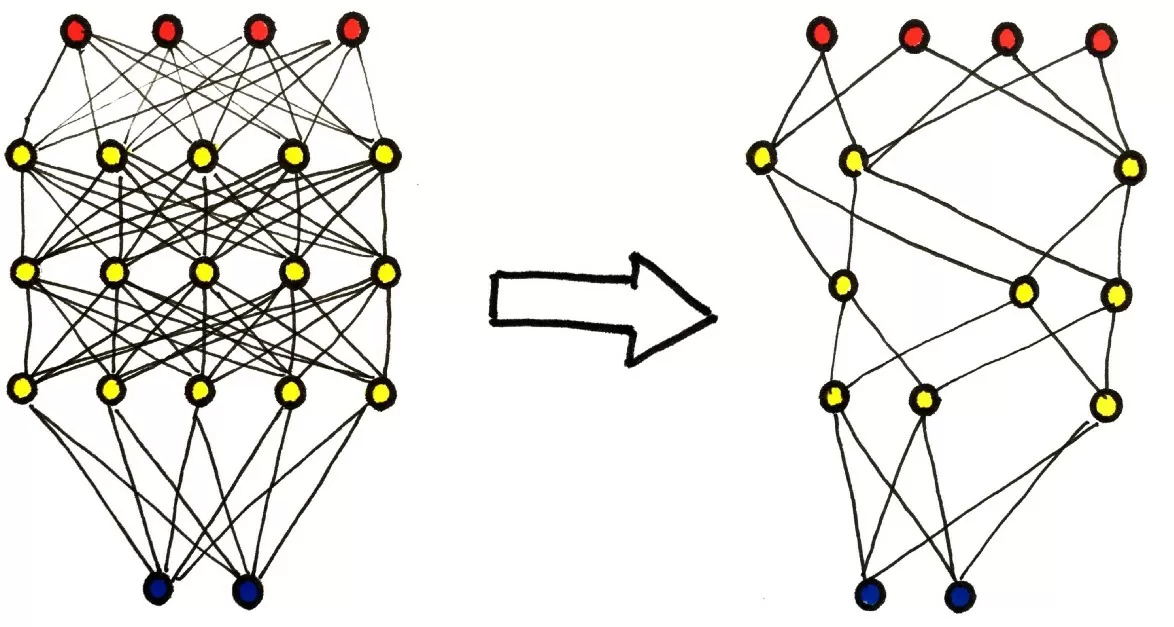
Прунинг нейронной сети это метод сжатия модели, путем удаления части параметров.
Прунинг, как и квантизация, может быть использован до, после и во время обучения на основе:
- Амплитуды весов, активаций, градиентов, гессианов
- Заданных правил, Байесовских подходов
- Реинициализации, дообучения
Самый простой способ прунинга нейронной сети есть под капотом PyTorch, и он реализуется всего одной строчкой кода.
import torch
from torch.nn.utils import prune
prune.random_unstructed(module , name = ‘weight’ , amount = 0.3)
В заключении хотелось бы сказать, что все три способа оптимизации можно комбинировать, тем самым получать результаты сопоставимые по качеству с огромными моделями, при этом затрачивая гораздо меньше ресурсов как временных, так и информационных.