/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Архитектура Transformer улучшила производительность моделей глубокого обучения в таких областях, как компьютерное зрение и обработка естественного языка. Вместе с лучшей производительностью приходят и большие размеры моделей. Это создает проблемы производительности аппаратного обеспечения. Не разумно тренировать большие модели, такие как Vision Transformer, BERT, GPT, на одном графическом процессоре или одной машине. Существует острая потребность в обучении моделей в распределенной среде. Однако распределенное обучение, особенно параллелизм моделей, часто требует знаний в области компьютерных систем и архитектуры. Для исследователей ИИ остается сложной задачей внедрение сложных распределенных обучающих решений для своих моделей. В этой статье рассмотрим систему Colossal-AI, которая представляет собой единую параллельную обучающую систему, предназначенную для плавной интеграции различных парадигм методов распараллеливания. Она позволяет исследователям данных сосредоточиться на разработке архитектуры модели и отделяет проблемы распределенного обучения от процесса разработки.
Вступление
Глубокое обучение продемонстрировало свою впечатляющую производительность во многих приложениях. При большом объеме данных нейронные сети, такие как BERT, Vision Transformer, способны изучать многомерные признаки и делать прогнозы на уровне, которого не могут достичь даже люди. По мере того, как становится доступно больше вычислительных ресурсов и ресурсов памяти, нейронные сети становятся более разнообразными с точки зрения архитектуры и растут с точки зрения количества параметров. Чёткая тенденция в области искусственного интеллекта заключается в том, что модели становятся значительно больше. Например, потребовалось всего 3 месяца, чтобы сместить звание самой большой модели с BERT-Large к GPT-2 в 2020 году, в то время как количество параметров GPT-2 примерно в 5 раз больше, чем у BERT-Large, а в следующей GPT-3 уже 175 миллиардов параметров. В 2021 году рекорд снова побит – это GLM с 1,75 трлн параметров. Ожидается, что такая тенденция в ближайшее время сохранится. Один графический процессор больше не может вместить всю модель целиком, и это делает распределенное обучение обязательным.
Для параллельных вычислений DeepSpeed предоставил эффективный способ устранения избыточности памяти при параллельном обучении данных и может быть интегрирован с тензорным параллелизмом, введенным Megatron-LM. Сам Megatron-LM предоставил открытый исходный код для разделения тензоров в одном измерении. Это позволяет модели охватывать несколько графических процессоров и масштабироваться до миллиардов параметров. Однако, одной из ключевых проблем Megatron-LM является то, что он вносит дополнительную сложность в процесс обучения, поскольку разработчик должен учитывать такие факторы, как коммуникация, согласованность и эффективность масштабирования. Его распределенные операции трудно понять исследователям и разработчикам, которые не имеют системного опыта. Между тем, есть и другие аспекты, на которые необходимо обратить внимание, такие как настройка среды и случайность.
Чтобы решить эти проблемы, была разработана система Colossal-AI, В этой статье мы лишь хотим осветить данный инструмент, который упрощает инженерные задачи обучения нейронных сетей на распределённых системах для исследователей данных, не очень погружённых в архитектуру компьютерных сетей, то есть таких же, как мы сами).
Colossal-AI представляет собой систему с открытым исходным кодом на основе PyTorch для демократизации сложного распределенного обучения в сообществе ИИ. В системе отделяется распределенная реализация от процесса построения модели и поддерживаются инструменты 2D, 2.5D и 3D (общие положения по алгоритмам можно посмотреть в wiki https://ru.wikipedia.org/wiki/Алгоритм_умножения_матриц) тензорный параллелизм, параллелизм последовательностей и контрольные точки активации.
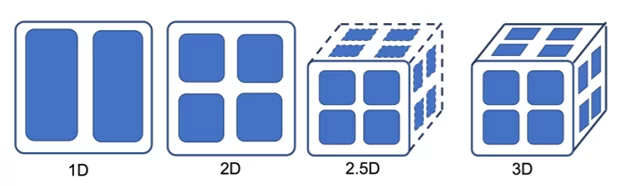
Среди методов 1D-параллелизм относится к методу, введенному Megatron-LM, который разделяет веса модели, особенно линейный слой. Однако этот метод имеет избыточность памяти, поскольку выходные данные слоя сохраняются полностью, а не разделяются, как веса модели. Для решения этой проблемы был предложен 2D, 2.5D и 3D тензорный параллелизм, чтобы полностью устранить избыточность памяти.
2D-тензорный параллелизм
Этот метод основан на алгоритме умножения матриц SUMMA и разделяет входные данные, веса модели и выходные данные слоя по двум разным измерениям. Тензорные блоки распределяются по 2D-сетке из N2 устройств, где N — количество тензорных блоков в одном измерении.
2.5D Тензорный параллелизм
Вдохновлен 2.5D алгоритмом умножения матриц. Количество процессоров P, где P = Q2 ∗ D расположены в D слоях, и каждый слой выполняет операции умножения матриц независимо с размерностью Q.
3D-тензорный параллелизм
В системе также реализуется 3D-тензорный параллелизм, который распараллеливает нейронные сети на кубе 3D-процессора. Этот метод позволяет достичь оптимальных O(P1/3) накладных расходов на связь на P-процессорах, в то же время как вычисления, так и использование памяти равномерно распределяются благодаря оптимизированной балансировке нагрузки параметров, а также активаций.
Параллелизм последовательностей
При моделировании языка/речи с длинными последовательностями-предложениями, например, понимание текста на уровне документа, большой размер измерения последовательности делает его неэффективным, поскольку память, потребляемая активацией слоя, становится большой. Параллелизм последовательностей разбивает длинную последовательность на подпоследовательности и распределяет подпоследовательности по множеству устройств. В результате модель может быть обучена на более длинной последовательности, которую не может вместить один графический процессор.
Чтобы cмаксимизировать надежность и универсальность Colossal-AI, в неё включены существующие методы, такие как оптимизатор с нулевой избыточностью и разгрузка с помощью DeepSpeed и 1D тензорным параллелизмом с помощью Megatron-LM.
В этой системе пользователь может предоставить конфигурационный файл, который определяет параметры для комбинации распараллеливания, обучающих компонентов (например, набора данных и оптимизатора), обучения со смешанной точностью и использования оптимизатора с нулевым резервированием и разгрузки.
В Colossal-AI Py Torch-подобный API, позволяющий пользователю создавать свою модель с минимальными изменениями в своих привычках кодирования. Так слой многослойного персептрона с большим скрытым размером может быть построен в так же, как обычно создается модуль Python. Он будет потреблять много памяти графического процессора в таких моделях, как Transformer, и потенциально вызывать проблему нехватки памяти. Вместо этого модуль из примера, построенный с 2D-параллельными слоями, будет выполняться в 2D-параллельном режиме и уменьшать нагрузку на память графических процессоров, что позволит обучать крупномасштабную модель.
Пример модуля.
from colossalai.nn import Linear2D, LayerNorm2D
import torch.nn as nn
class MLP_2D(nn.Module):
def __init__(self):
super().__init__()
self.linear_1 = Linear2D( in_features=1024, out_features=8192)
self.norm = LayerNorm2D( normalized_shape=8192)
self.linear_2 = Linear2D( in_features=8192, out_features=1024)
def forward(self, x):
x = self.linear_1(x)
x = self.norm(x)
x = self.linear_2(x)
return x
Пример с GPT-3
В Colossal-AI существует несколько способов распределенного запуска GPT. В train_gpt.py сценарий запускает обучение с использованием конкретных сценариев конфигурации в gpt3_configs/ для различных параллелизмов GPT-3. Вы можете изменить их, чтобы адаптировать к своему собственному использованию.
В примере используется общедоступная открытая OpenWebText для загрузки URL-адресов к различным веб-страницам. Затем данные фильтруются, очищаются и дедуплицируются.
Установка необходимых пакетов
(для LSH требуется версия GCC. 9.3.0.)
pip install ftfy langdetect numpy torch pandas nltk sentencepiece boto3 tqdm regex bs4 newspaper3k htmlmin tldextract cached-path
git clone https://github.com/mattilyra/LSH.git
cd LSH
python setup.py install
Если вам не удалось установить его успешно, вы можете попытаться заменить cMinhash.cpp в LSH/lsh с на tools/lsh/cMinhash.cpp.
Загрузка Данных
В Megatron-LM были авторами библиотеки исправлены некоторые ошибки, авторы Colossal-AI разместили необходимые файлы в tools/Megatron.
cd path/to/tools
python Megatron/blacklist_urls.py <path/to/URLs> <path/to/clean_urls.txt>
Далее загружается содержимое с чистых URL-адресов и объединяется в один свободный файл json с 1 json на 1 новую строку:
{'text': text, 'url': unique_url}
python download/download.py <path/to/clean_urls.txt> --n_procs 50 --output <path/to/raw.json>
Подготовка данных для обучения GPT
Выполните
python Megatron/cleanup_dataset.py <path/to/raw.json> <path/to/clean.json>Дополнительная очистка может быть выполнена с помощью cleanup_fix_dataset.py . Более подробную информацию можно найти, запустив python cleanup_fix_dataset.py --help.
Используя LSH, находятся возможные дубликаты и сохраняются в файл для последующей обработки. Более подробную информацию можно найти по адресу python find_duplicate.py --help
python Megatron/find_duplicates.py --inputs <path/to/clean.json> url --output <path/to/process_stage_one.json>Для каждой группы сохраняем только один URL-адрес, а остальные удаляем.
python Megatron/group_duplicate_url.py <path/to/process_stage_one.json> <path/to/process_stage_two.json>Удаление дубликатов
python Megatron/remove_group_duplicates.py <path/to/process_stage_two.json> <path/to/clean.json> <path/to/dedup.json>Перемешивание набора данных
shuf <path/to/dedup.json> -o <path/to/train_data.json>Использование
#!/usr/bin/env sh
export DATA=/path/to/train_data.json
colossalai run --nproc_per_node=<num_gpus> train_gpt.py --config=gpt3_configs/<config_file>
Следует изменить DATA, num_gpus и config_file, указав путь к вашему набору данных, количество графических процессоров и путь к файлу конфигурации соответственно. Если будете работать с GPT-2, то следует выбирать gpt2_configs.
Существуют некоторые общие правила при изменении конфигурационных файлов.
TP означает Tensor Parallel
PP означает Pipeline Parallel
DP означает Data Parallel
GPUS = TP * PP * DP
Где DP устанавливается автоматически
Вы можете установить размер пакета и номер эпохи, изменив количество BATCH_SIZE и NUM_EPOCHS соответственно.
Если вы используется более 1 графического процессора и TP * PP < количества графических процессоров, то Colossal-AI автоматически установит DP.
Вывод
Огромные модели, обученные на колоссальных объёмах данных, будут востребованы и в будущем. Крайне важно демократизировать обучение крупномасштабных моделей, используя параллельные вычисления. Colossal-AI стремится предоставить исследователям и разработчикам удобную систему, позволяющую легко масштабировать свое обучение на кластерах и обучаться с более короткими временными рамками и меньшим количеством вычислительных ресурсов.