/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
В своей работе Data Scientist используют различные модели для улучшения качества метрик. Чтобы применить модель, предварительно необходимо затратить существенные ресурсы на обработку всего массива необработанных данных. Мы расскажем об инструменте, которым пользуемся для оптимизации этого процесса. Инструмент Pipeline позволяет объединить несколько операций обработки данных в единую модель библиотеки Python «Scikit-learn».
Рассмотрим его применение более подробно.
Класс Pipeline предусматривает методы fit, predict и score, имеющие свойства, аналогичные свойствам модели в библиотеке «Sckit-learn». В Машинном обучении чаще всего класс Pipeline используется для объединения операций предварительной обработки (например, масштабирования данных или one-hot-encoding) с моделью машинного обучения типа классификаторов. Его использование позволяет избежать ошибок и сокращает временные издержки.
Вот как это выглядит схематически.
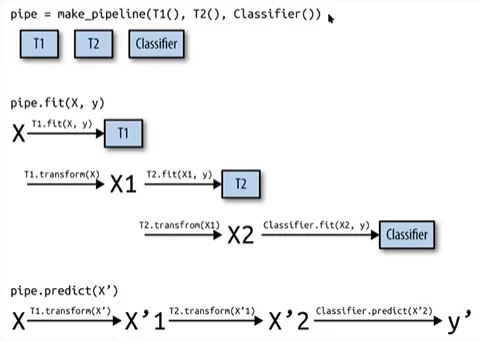
Другими словами, применяется определённая последовательность действий к необработанным данным (в первую очередь осуществляется трансформирование данных, а уже после: масштабирование числовых переменных, one-hot-encoding и так далее). В принципе в T1(), T2() …Tn() может быть любой код по предобработке данных.
Основное преимущество Pipeline:
- на входе можем подать абсолютно «сырые» данные, которые будут обработаны внутри pipeline, в результате чего на выходе будет получен необходимый нам результат (predict);
- обработка данных происходит сразу как для обучающей выборки, так и для тестовой, что избавляет нас от дублирования кода и, соответственно, уменьшает вероятность совершения ошибок в коде.
Рассмотрим абстрактный датасет, в котором содержатся численные и категориальные значения для последующей обработки (для того чтобы можно было применить различные модели).
Такой код, чаще всего можно увидеть на различных соревновательных платформах:
# Объявляем scaler и OneHotEncoder() для числовых и категориальных переменных
scaler = StandardScaler()
ohe = OneHotEncoder(sparse=False, handle_unknown='ignore')
# Масштабируем числовую часть тренировочной выборки
data_train_scaled = scaler.fit_transform(data_train[numerical])
# Масштабируем категориальную часть тренировочной выборки
data_train_ohe = ohe.fit_transform(data_train[to_dummies])
# Склеиваем наш тренировочный датасет
data_train_tramsformed = pd.concat([pd.DataFrame(data_train_scaled, columns=numerical),
pd.DataFrame(data_train_ohe, columns=ohe.get_feature_names()), axis=1)
# Тренируем нашу модель, например, используя модель логистической регрессии
model = LogisticRegression()
model.fit(data_train_tramsformed, data_train[target])
# Масштабируем числовую часть тестовой выборки
data_test_scaled = scaler.transform(data_test[numerical])
# Масштабируем категориальную часть тестовой выборки
data_test_ohe = ohe.transform(data_test[to_dummies])
# Склеиваем наш тренировочный датасет
data_test_tramsformed = pd.concat([pd.DataFrame(data_test_scaled, columns=numerical),
pd.DataFrame(data_test_ohe, columns=ohe.get_feature_names()), axis=1)
# Делаем predict на тестовой выборке
preds = model.predict(data_test_tramsformed)
На данном примере видно, что код дублируется. Для исключения дублирования кода, можно написать функцию, которая будет проделывать вышеперечисленные операции. Но нужно помнить, что масштабировать данные нужно только на обучающей выборке, а применять масштабирование как на обучающей, так и на тестовой выборке, что будет способствовать наличию дополнительных условий.
Теперь рассмотрим инструмент Pipeline с дополнительным набором функций:
- — FunctionTransformer: преобразует функцию в трансформер (т.е., появляются методы fit/transfrom);
- — FeatureUnion: объединяет результаты нескольких трансформеров в один датасет;
Таким образом код с использованием Pipeline будет выглядеть следующим образом:
# Объявляем scaler и OneHotEncoder() для числовых и категориальных переменных соответственно
scaler = StandardScaler()
ohe = OneHotEncoder(sparse=False, handle_unknown='ignore')
# Делаем pipeline для числовых переменных датасета
numerical_selector = FunctionTransformer(lambda data: data[numerical], validate=False)
numerical_preprocessor = Pipeline([("numerical_selector", numerical_selector), ("scaling", scaler)])
# Делаем pipeline для категориальных переменных датасета
dummy_selector = FunctionTransformer(lambda data: data[to_dummies], validate=False)
dummy_preprocessor = Pipeline([("dummy_selector", dummy_selector), ("ohe", ohe)])
# Объединяем созданные выше pipeline в один с помощью функции FeatureUnion и затем записываем итоговый pipeline на примере логистической регрессии
feature_union = FeatureUnion([("numerical_preprocessor", numerical_preprocessor),
("dummy_preprocessor", dummy_preprocessor)])
pipeline = Pipeline([("preprocessing", feature_union), ("modelling", log_reg)])
# Теперь можно обучить модель
pipeline.fit(data_train.drop(target, axis=1), data_train[target])
# И наконец predict
Preds = pipeline.predict(data_test.drop(target, axis=1))
Отметим, что Pipline можно вкладывать в другие pipeline, что позволяет осуществлять сложную обработку данных с помощью одной абстракции.
Вот так, применение инструментов Pipeline позволяет оптимизировать работу Data Scientist, что способствует повышению качества и скорости работы в целом.