/img/star (2).png.webp)




/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Бывают такие случаи в анализе процессов, когда данных не очень много, а действия в процессах хаотичны. И что делать? Конечно, анализировать. Для этого будем использовать привычные инструменты: python и excel. И иногда гугл.
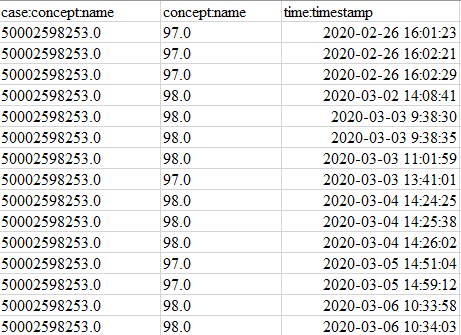
Прежде чем браться за ноутбук, необходимо всегда смотреть на данные глазами. Что имеем: исходный набор состоит из 1 000 000+ строк и 19 столбцов. Внушительно. Чистим и извлекаем нужные данные. После применения некоторых фильтров осталось около 36 000 строк, которые нам необходимы. Разница огромна! Из оставшегося набора выделяем столбцы ‘case_id’, ‘activity’, ‘timestamp’.
Проведем статистический анализ процессов. Результат показал почти 80% уникальных процессов и среднее количество шагов в трассе чуть больше 1. Катастрофа. Думаем, почему так может быть, и параллельно копаем глубже. После взгляда на метаданные возникло еще больше вопросов: получилось так, что большая часть трасс начинается с действия, которое должно их заканчивать. Еще интереснее.
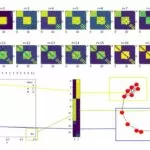
Нужен более тщательный анализ. Посмотрим на граф, построенный с помощью Inductive miner (pm4py):
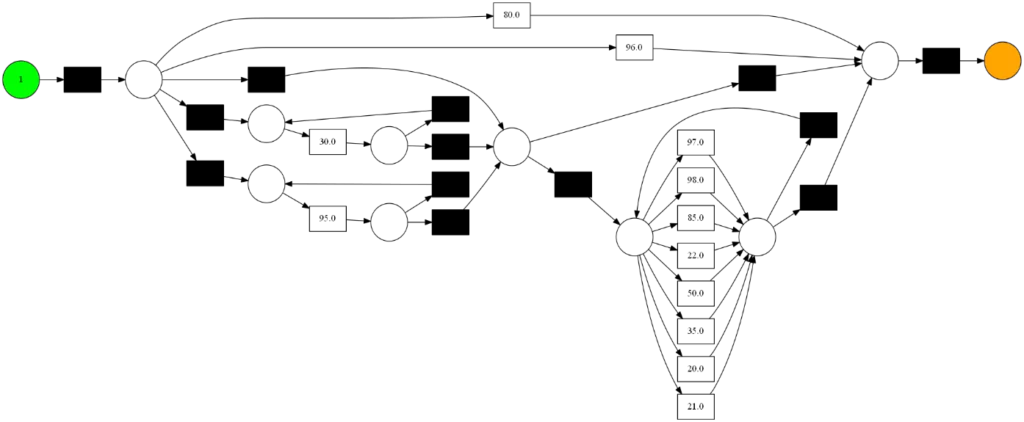
Выглядит неплохо. Так и не скажешь, что 80% цепочек состоят из 1 действия.
Прежде чем грешить на ИС или исполнителей, проверим, как распределяются процессы. Это может дать некоторое понимание того, что именно повлияло на данные. Проведем кластерный анализ.
Подготовим данные, составив таблицу частотности для активностей в каждом процессе и обогатим ее статистическими характеристиками.
unique_actions = df.pivot_table(index='case:concept:name', columns='concept:name', aggfunc='size', fill_value=0)
actions_sum = unique_actions.sum(axis=1)
unique_actions['sum'] = actions_sum
unique_actions.sort_values(by='sum', ascending=False)
Считаем медиану, среднюю длину трассы, среднее время выполнения и добавляем столбцы.
median = unique_actions.median(axis=1)
mean = unique_actions.mean(axis=1)
unique_actions['mean'] = mean
unique_actions['median'] = median
case_durations = case_statistics.get_all_casedurations(event_log,
parameters={case_statistics.Parameters.TIMESTAMP_KEY: 'time:timestamp'})
durations = pd.DataFrame(case_durations)
Для кластеризации используем 3 различных алгоритма: PCA, tSNE, DBSCAN. Сравним разные модели и то, как они помогают понять проблему.
PCA
В нашей сводной таблице получилось довольно много признаков, которые могут сильно влиять на точность работы алгоритмов. Чтобы не снижалось качество кластеризации, можно снизить размерность данных (без потери важной информации), для чего и существует метод главных компонент.
Это линейный метод, поэтому он может не работать на данных, в которых присутствуют нелинейные отношения.
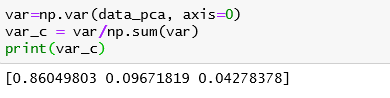
Перед применением алгоритма узнаем, какое оптимальное количество компонент нужно оставить: измерим коэффициент дисперсии и узнаем, сколько признаков составляет 90%.
Далее масштабируем данные с помощью StandardScaler и передаем алгоритму.
Визуализация:
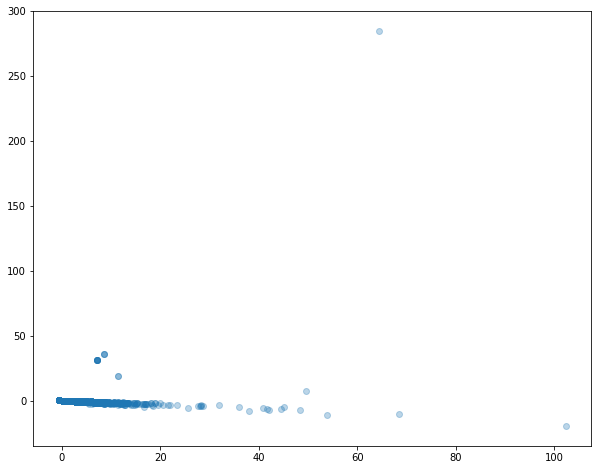
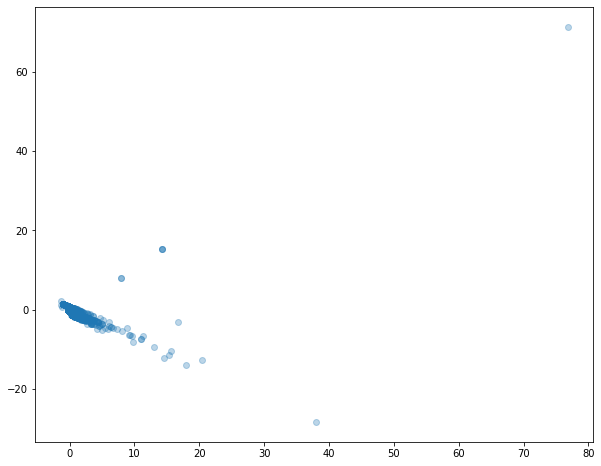
Разница есть, но очевидных выводов по графику нет. Все собрано в одну группу. PCA не справился с нашими данными. Есть и другие инструменты для уменьшения размерности. Например, tSNE.tSNE
Этот алгоритм работает на основе данных с нелинейными отношениями. Он использует более сложную математическую модель, поэтому в некоторых случаях он может справиться с задачей лучше, чем PCA.
Сравним визуализацию:

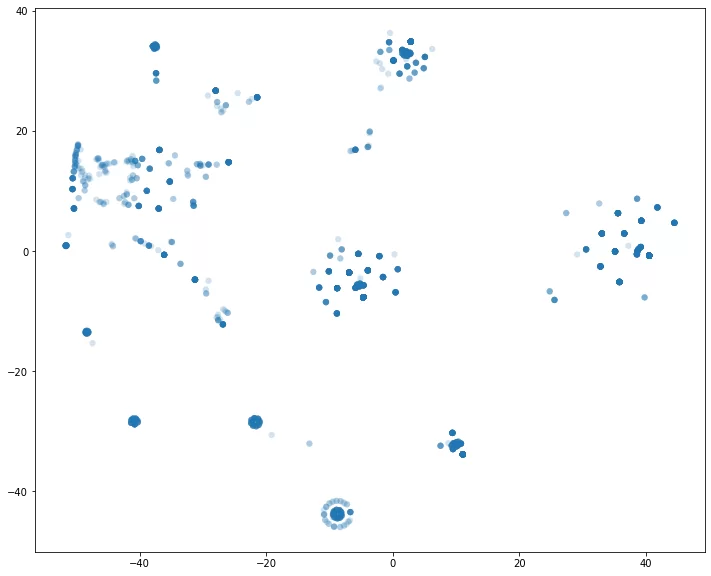
Разница с PCA очевидна.
Первый график показывает группы, составленные на исходных данных – с аномально короткими трассами (напомню, их 80%). Как и ожидалось, они собрались в одну большую группу, а вот остальные собрались в одну невыпуклую область или одиноко «размазались» по плоскости.
На втором графике изображены группы, составленные на данных без аномалий. Распределение кардинально изменилось. Видим области с разной плотностью и невыпуклый кластер. Самые плотные собрали процессы примерно одинаковой длины и средним временем выполнения действия. Возможно, в них собраны короткие трассы в 2, максимум в 3 действия (при малом количестве действий вероятность появления значительных различий трасс сильно снижается).
DBSCAN
Это алгоритм, работа которого основана на расстоянии между ближайшими точками. Он не чувствителен к шумам и выбросам.
С помощью нескольких строк кода мы получаем распределение количества процессов в кластере. На гистограмме можно увидеть, как сильно выделяется одна группа, в которой чуть меньше 25 000 случаев. Как и tSNE, DBSCAN выделил короткие трассы из 1 действия в один кластер. А ещё есть больше 2000 выбросов (то, что алгоритм пометил как «-1»). Остальные выделяются не так сильно.
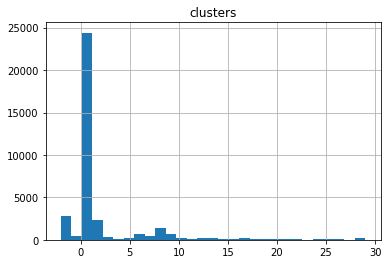
А вот так выглядит распределение без аномально коротких трасс и отмеченных алгоритмом выбросов:
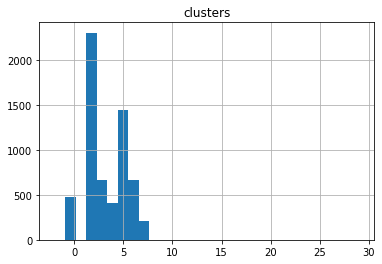
Итак, мы испытали 3 алгоритма, чтобы выполнить кластеризацию. На разбиение сильнее всего повлияла средняя длина трассы, что можно увидеть на графиках. При снижении размерности этот признак оставался как базис. Значит, нужно выяснить, как же получилось, что такое огромное количество процессов записано или выполнено неверно.
На этом этапе можно предположить, что:
— ИС собирает данные не всегда корректно
— ИС может зависать: исполнитель нажимает кнопку несколько раз, регистрируется несколько действий подряд (об этом говорят 1-5-секундные интервалы между некоторыми действиями).

Мы выстроили предположения относительно технических вопросов. Но действия выполняются людьми, и выполняются не всегда корректно. Одно дело указывать на ошибки автоматизированной системы, совершенно другое – на неверные шаги людей. Чтобы дать рекомендации относительно их исправления, необходимо найти конкретную причину в поведении. Люди могут ошибаться вечером, когда они устали. Или в предпраздничный период, когда мысли о работе где-то далеко. А может, это новый сотрудник, который не разобрался в системе? PCA и tSNE – прекрасные инструменты, которые помогут извлечь нужные признаки: не нужно будет выстраивать море статистик, чтобы понять, какие векторы составляют базис. Все уже есть «под капотом». Для проверки влияния различных факторов можно (и даже нужно) использовать описанные алгоритмы и получать долгожданные инсайты.