/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Добрый день! В посте, на примере задачи поиска логических ошибок робота, я продемонстрирую, как методы тематического моделирования помогут исследователя при работе с большим объемом текстовых данных.
Задача тематического моделирования возникает очень часто, когда существует необходимость в обработке большого количества текстовой информации. Тематическое моделирование – это разбиение коллекции текстовых документов на группы, в которых элементы имеют общую тематику. Стоит понимать, что один документ может иметь разные темы, в таком случае документ определяется распределением тематик, однако для нашей задачи крайне необходимо, чтобы документ однозначно принадлежал определенной группе. Использование метода предполагает то, что никаких дополнительных данных, кроме самого текста не используется.
Способов применения тематического моделирования в реальных задачах множество. Например, вы можете автоматически определять тематику письма в электронной почте, а после ранжировать его. В задаче информационного поиска тематическое моделирование позволяет более качественно отбирать информацию по текстовому запросу. Исследователям, которые работают с текстовой информацией просто необходим инструмент, который может структурировать объемные текстовые массивы. Интересно и то, что предметом исследования может быть не только человеческий язык, но и любые текстоподобные данные: программный код, банковские транзакции, музыкальные произведения.
Для начала четко обозначу задачу – это улучшение процесса дистанционного взыскания.
Необходимо найти все диалоги, в которых робот совершает логическую ошибку следующего вида:
Бот задает вопрос о том, закроет ли клиент долг => клиент отвечает отрицательно или неопределенно => бот считает, что ответ положительный и фиксирует это.
Что я подразумеваю под диалогом скажу чуть позже.
Рассмотрим примерный шаблон, по которому бот ведет беседу с клиентом.
- Приветствие и информирование о том, что разговор будет записан.
- Идентификация клиента.
- Информирование о задолженности.
- Прощание.
Соответственно, в процессе возможны различные варианты развития диалога, например, клиент не прошел идентификацию, занят, лежит в больнице, не может найти работу и так далее. Проблема в том, что возможных исходов и вариаций ответа неимоверное множество и довольно сложно их структурировать.
Фрагмент диалога, в котором клиент не прошел идентификацию.

Фрагмент диалога, в котором клиент не готов к диалогу.

Как уже было сказано, эту задачу я буду решать с помощью методов тематического моделирования.
Обзорный план моего решения:
- Собрать и обработать все ответы клиентов на вопрос о задолженности.
- Разбить ответы клиентов на группы. Этот пункт является скорее подзадачей, которая облегчит разметку. Обзорный осмотр 200 кластеров быстрее, чем просмотр всей коллекции диалогов, которых около 1 000 000.
- Разметить эти кластеры вручную, там, где клиент без сомнений говорит о том, что он заплатит или уже заплатил = 1, во всех остальных случаях = 0 (включая неопределенности: *не знаю*, *когда придет зарплата*, *наверное завтра* и так далее).
- Если у ответа стоит отметка 0 и при этом бот ведет себя также, как и при 1(то есть думает, что клиент ответил утвердительно), то этот случай я буду считать логической ошибкой и направлять аналитику для дальнейшего осмотра.
Сбор и обработка ответов клиентов
Диалог в рамках данной работы – это отсортированная по времени таблица, у которой есть 2 поля и свой собственный id.
speaker – кто произнес цитату (робот или клиент).
sent – цитата.

Всего таких диалогов около 1 000 000.
Для начала рассмотрю только те диалоги, в которых бот дошел до вопроса об оплате и отберу ответы клиентов. В моем понимании ответом клиента будет цитата, которая идет после вопроса робота. Соберу все ответы в одну коллекцию.
#список вопросов об оплате
robot_questions = [
'ВНЕСЕТЕ ПЛАТЕЖ?'
'ОПЛАТА ПОСТУПИТ ЗАВТРА?',
'ВЫ ГОТОВЫ ПРОИЗВЕСТИ ОПЛАТУ ЗАВТРА?',
'ВЫ ГОТОВЫ ОПЛАТИТЬ ЕЁ ЗАВТРА?',
'ВЫ ГОТОВЫ ОПЛАТИТЬ ЭТУ СУММУ?',
'ВО ИЗБЕЖАНИЕ НЕГАТИВНЫХ ПОСЛЕДСТВИЙ, ВЫ ГОТОВЫ ПРОИЗВЕСТИ ОПЛАТУ ЗАВТРА?'
]
#ответы клиентов
client_answers = []
#номера таблиц в которых отсутствует вопрос или их по какой-то причине более 1,
#пока для простоты не будем рассматривать эти случаи.
black_indexes = []
#идем по каждому диалогу и отбираем только те, в которых бот 1 раз задает вопрос из списка,
#далее забираем ответы клиента.
for table_index, table in enumerate(data):
search_robot_questions = table.loc[((table['sent'].isin(robot_questions)) & \
(table['speaker'] == 'robot'))]
if search_robot_questions.shape[0] == 1:
try:
index = search_robot_questions.index[0] + 1
client_answers.append(table.iloc[index]['sent'])
except IndexError:
black_indexes.append(table_index)
else:
black_indexes.append(table_index)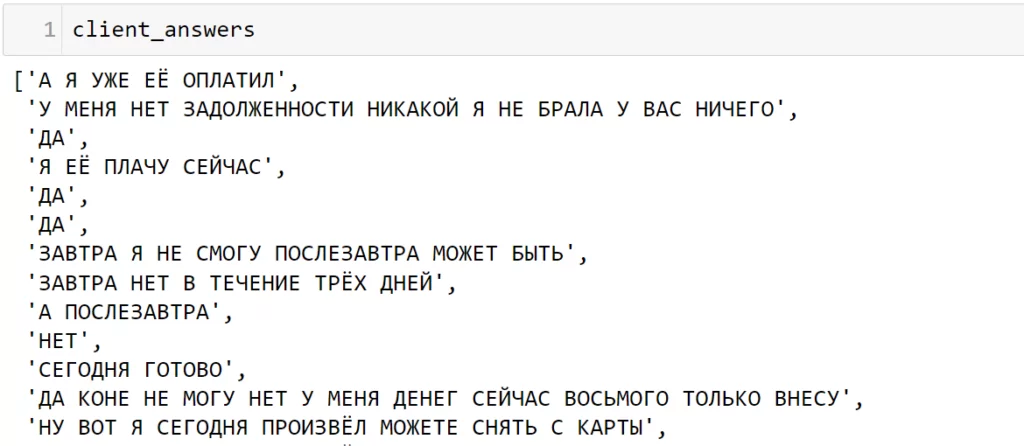
Если смотреть на ответы клиентов, то все они примерно одинаковы, отличия есть в небольших деталях.
Разбивка ответов клиентов на группы
Для начала предварительно напишу обработку текста, разобью предложения на отдельные слова, далее приведу их к нормальной форме.
import pymorphy2
from gensim.utils import tokenize
MORPH_ANALYZER = pymorphy2.MorphAnalyzer()
#простая предобработка текста(токенизация и приведение к нормальной форме)
def simple_preprocessing(sent: str)-> str:
return ' '.join([MORPH_ANALYZER.normal_forms(word)[0] for word in tokenize(sent.lower())])
simple_preprocessing('МОЖНО ПАРУ ДНЕЙ ДАЙТЕ МНЕ ЕЩЁ ПОЖАЛУЙСТА Я ПРОСТО С РЕБЁНКОМ ВЫЕХАТЬ НЕ МОГУ')
>>> 'можно пара день дать я ещё пожалуйста я просто с ребёнок выехать не мочь'Теперь необходимо векторизовать ответы клиентов, с дальнейшей обработки с помощью методов машинного обучения.
Для векторизации я буду использовать меру TF-IDF. Мера TF-IDF эффективна для выделения ключевых слов в тексте, это мне и нужно. Цитаты клиентов достаточно короткие, поэтому можно найти слово или несколько слов, которые могут полностью характеризовать всю цитату.
У TF-IDF есть свои преимущества, если сравнивать ее с другими способами векторизации текста:
- Легкая интерпретация.
- Простота.
- Регулирование параметров.
Подробнее о TF-IDF можно прочитать тут.
#предобработка текста
preproc_data = [simple_preprocessing(item) for item in client_answers]
#векторизация
vectorizer = CountVectorizer()
vectorizer_corpus = vectorizer.fit_transform(preproc_data)
tfidf = tfidf_t()
vectors = tfidf.fit_transform(vectorizer_corpus)Теперь можно использовать алгоритм кластеризации. Я буду использовать DBSCAN. Главное преимущество DBSCAN – это устойчивость к шуму и возможность работы с данными, которые имеют нетипичную форму, однако алгоритм имеет квадратичную сложность, что может привести к долгой работе при больших объемах.
Конфигурация модели
Чтобы подобрать оптимальный параметр eps, вы можете использовать информацию из этого источника, тем самым вы можете улучшить качество ваших кластеров.
Пока для простоты возьму значение eps = (0.1, 0.3, 0.5, 0.7, 1). Чем меньше eps – тем больше объекты в кластере похожи друг на друга.
Для большей интерпретации и понимания, я пожертвую информацией и снижу размерность до двух компонент. Однако, жертвуя информативностью, мы получаем возможность визуализировать полученные двумерные вектора на плоскости. Чтобы понизить размерность и не потерять значительную часть информации, которая находится в ваших векторах, вы можете использовать, например, сингулярные значения и правило локтя, подробнее можно посмотреть тут.
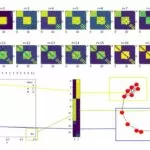
В коде, который представлен ниже, я создаю таблицу с метками кластеров, которые соответствуют определенному параметру eps (0.1, 0.3, 0.5, 0.7, 1).
import seaborn as sns
from sklearn.manifold import TSNE
from sklearn.cluster import DBSCAN
low_vectors_tsne = TSNE(n_components=2).fit_transform(vectors.toarray())
result = pd.DataFrame()
result['txt'] = client_answers
result['e1'] = low_vectors_tsne[:, 0]
result['e2'] = low_vectors_tsne[:, 1]
for eps in [0.1, 0.3, 0.5, 0.7, 1]:
result[f'dbscan_{eps}'] = DBSCAN(eps=eps, min_samples=2).fit(low_vectors_tsne).labels_Результат работы кода:
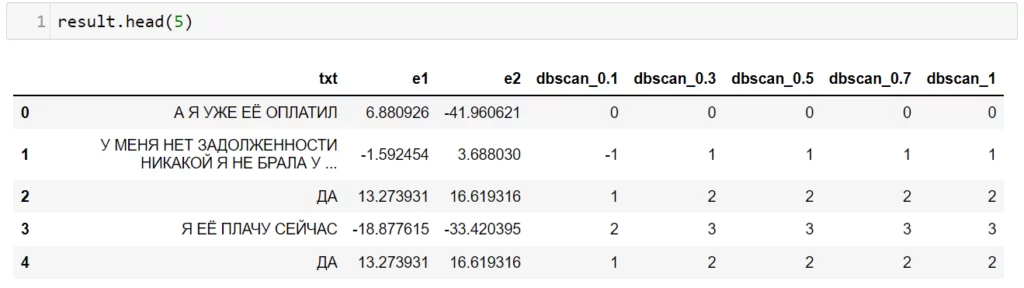
Посмотрю на результаты и сделаю выборку значений, у которых поле ‘dbscan_1’ = 0 (то есть это все цитаты нулевого класса, при eps = 1).
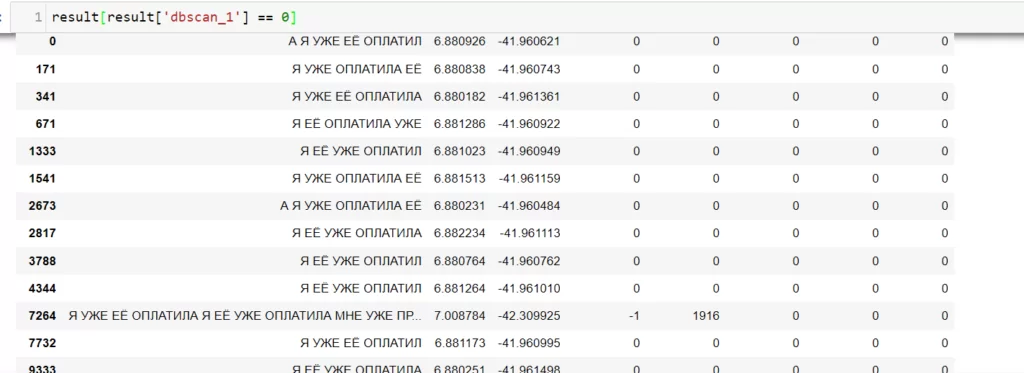
Теперь посмотрю, например, 5 класс.
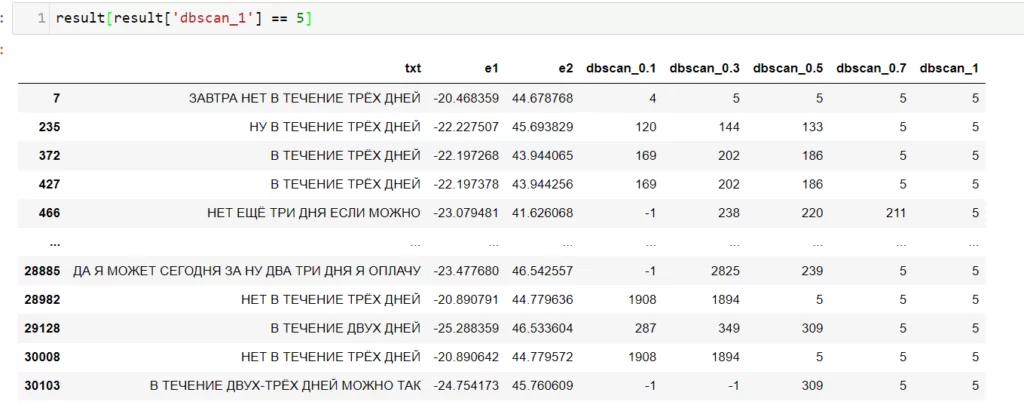
Можно заметить, что цитаты схожи между собой и вполне интерпретируемы, этого я и добивался.
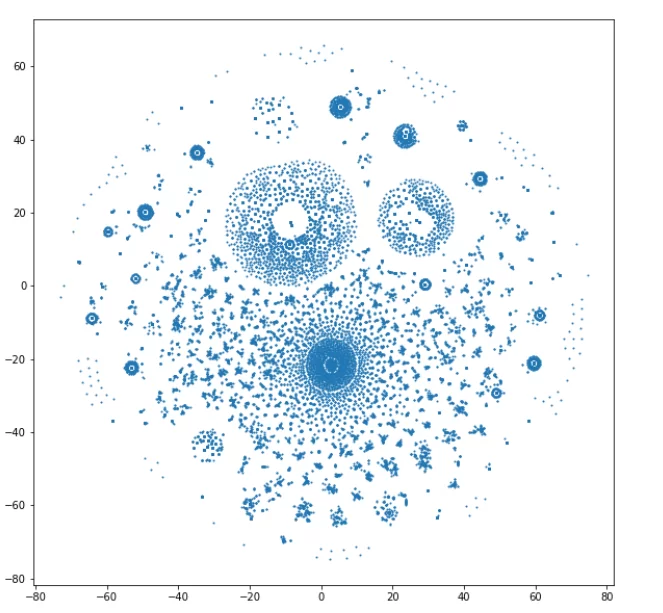
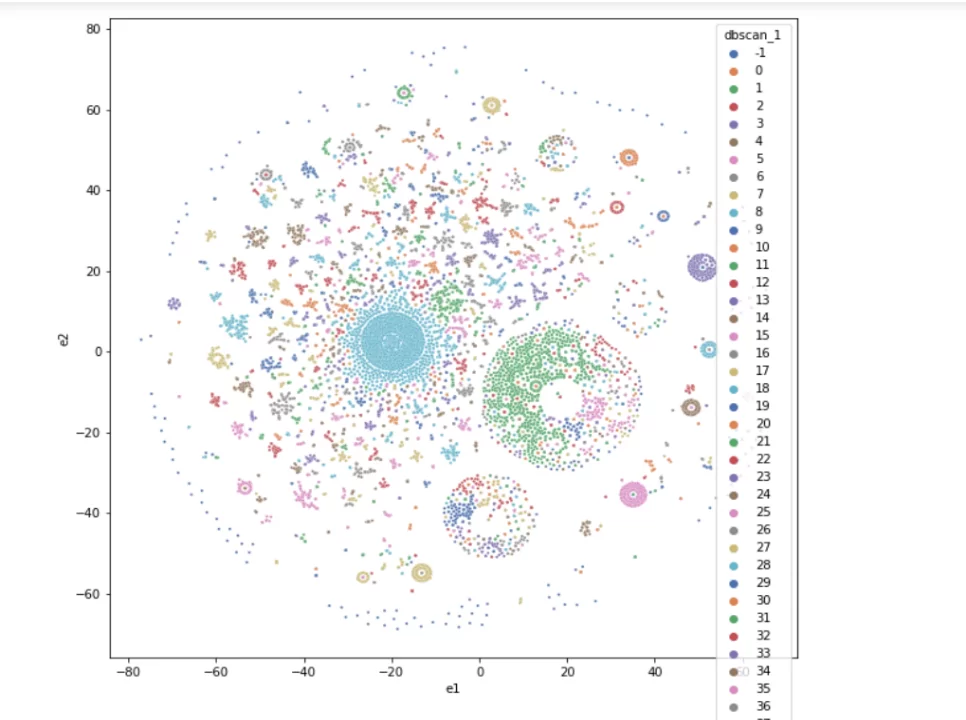
Визуализирую данные (eps=1).
Разметка кластеров и отбор кандидатов на ошибку
Получилось более 200 кластеров, которые уже не так трудно разметить вручную, в отличии от 1 000 000 диалогов. Это и была главная цель структурирования. Размечу полученные классы метками 0 или 1.
После разметки остается лишь задать правило, по которому я буду выявлять ошибки робота. Если стоит метка 0 и при этом робот произносит фразы, характерные метке 1, то этот диалог является кандидатом на ошибку.
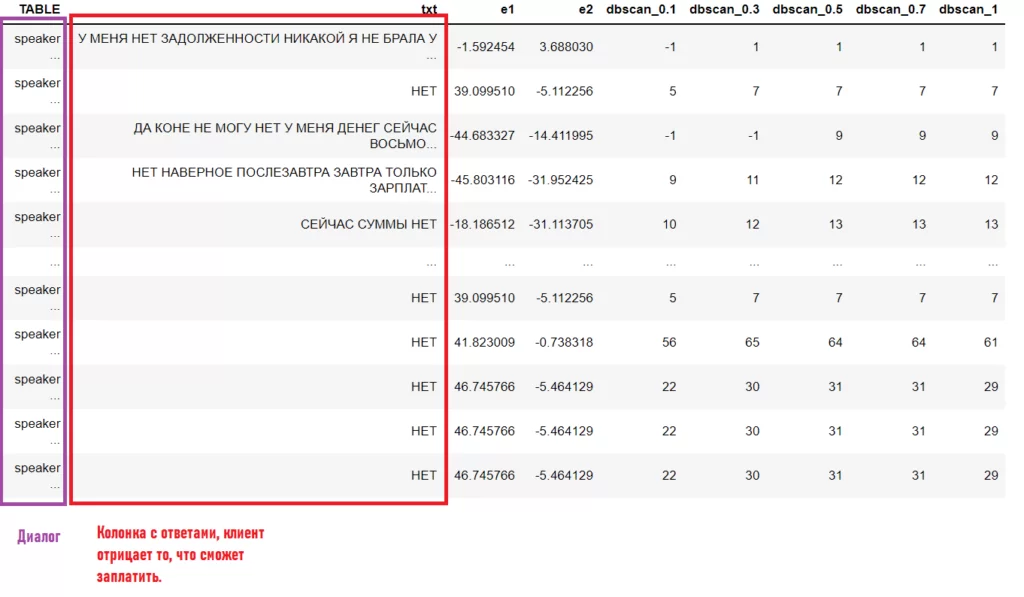
Отберу те строки, у которых в колонке с диалогами робот говорит:
‘ Я ФИКСИРУЮ ВАШЕ ОБЕЩАНИЕ ОБ ОПЛАТЕ’ хотя бы 1 раз.
То есть данная строка содержится в данном диалоге один или более раз.
candidate = []
for dialog in negative_answer['TABLE'].to_list():
if dialog[dialog['sent'] == 'Я ФИКСИРУЮ ВАШЕ ОБЕЩАНИЕ ОБ ОПЛАТЕ'].shape[0] > 0:
candidate.append(dialog)На выборку из 1 000 000 диалогов получилось 419 диалогов – кандидатов на ошибку. Полученных кандидатов я передаю аналитику для более глубокого анализа.
Подведу итоги
В этом материале я разобрал практический пример того, как можно использовать методы тематического моделирования для решения задач обработки больших массивов текстовых данных.
Предложенный метод является далеко не единственным способом решения задачи, вы всегда можете изменять его части, использовать предобученые трансформеры для получения векторов или поменять алгоритм кластеризации, использовать LDA, LSI, иерархическую кластеризацию и так далее.
У этого метода есть и свои недостатки, в векторах отсутствуют семантические знания, то есть модель не видит семантических зависимостей между словами и не сможет ничего сказать о слове, которого нет в датасете. Однако главное его преимущество – это легкое восприятие, относительно не сложная математика и универсальность.
С полным кодом можно ознакомиться по ссылке.