/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Инструменты process mining набрали большую популярность как в среде разработчиков, так и в бизнес-среде. При анализе бизнес-процесса можно воспользоваться готовыми инструментами, такими как Disco, ProM, однако их функционала не всегда хватает для полноценной и разносторонней аналитики, например, для поиска узких мест в процессе. В такой ситуации на помощь аналитикам приходит язык программирования python и библиотека pm4py.
В библиотеке pm4py не предусмотрено инструментов для поиска узких мест в логах, однако она нам понадобится для импортирования логов процесса, который мы хотим проанализировать.
Файлы логов обычно представлены в трех форматах: «.xes», «.csv», «.log». Для повышения универсальности нашего инструмента предусмотрим возможность работы с любым из широко применяемых форматов.
Поиск узких мест в логе будет осуществлять внутри DataFrame – табличного формата данных. Чтобы преобразовывать данные из формата, который не предполагает прямой импорт в DataFrame, сделаем класс-обработчик входных данных:
from pm4py.algo.discovery.dfg import algorithm as dfg_fac
from pm4py.objects.conversion.log import converter as log_converter
from pm4py.objects.log.util import dataframe_utils
import pandas as pd
import numpy as np
class Transformer:
def __init__(self, path_to_file):
self.path = path_to_file
self.log = None
def get_from_xes(self):
self.log = xes_importer.apply(self.path)
self.dataframe = log_converter.apply(self.log, variant=log_converter.Variants.TO_DATA_FRAME)
return self.dataframe
def get_from_csv(self):
self.dataframe = pd.read_csv(self.path)
self.dataframe = dataframe_utils.convert_timestamp_columns_in_df(self.dataframe)
self.log = log_converter.apply(self.dataframe)
return self.dataframe
def get_PD_from_log(self):
df = pd.read_fwf(self.path)
cols = df.columns.tolist()
cols = cols[-1:] + cols[:-1]
self.dataframe = df[cols]
self.log = log_converter.apply(self.log, variant=log_converter.Variants.TO_EVENT_LOG)
return self.dataframe
Теперь мы можем загружать в нашу программу файлы всех известных расширений для файлов логов процессов.
При поиске узких мест в процессах существует несколько подходов. Одним из них является следующий:
1) Выделяем в нашем процессе самые продолжительные экземпляры (кол-во таких процессов выбирается произвольно, обычно это 5-10% от общего числа кейсов).
2) Определяем переходы, средние длительности которых занимают больше всего времени
Для того, чтобы реализовать данный подход, необходимо создать пары id кейса — продолжительность кейса.
t = Transformer('/content/drive/MyDrive/tmp_df.csv')
t.get_from_csv()
cases = np.unique(t.dataframe['case:concept:name'])
avarage_duraion = []
for case in cases:
tmp_df = t.dataframe[t.dataframe['case:concept:name']==case]
avarage_duraion.append((case, max(tmp_df['time:timestamp']-min(tmp_df['time:timestamp']))))
avarage_duraion = sorted(avarage_duraion, key=lambda tup: tup[1], reverse=True)
bottle_cases = avarage_duraion[:round(len(avarage_duraion)/10)]
После того, как мы отфильтровали кейсы по продолжительности, необходимо посчитать медианные длительности для всех переходов в отобранных кейсах. Для этого отфильтруем наш исходный DataFrame.
cases = list(map(lambda x: x[0], bottle_cases))
tmp_df = t.dataframe[t.dataframe['case:concept:name'].isin(cases)]
tmp_df.index = [i for i in range(tmp_df.shape[0])]
Затем создадим словарь, ключами для которого будут переходы, а значениями суммарное время всех экземпляров таких переходов. Потом это время заменится на среднее время перехода:
duration_dict = dict()
for i in range(tmp_df.shape[0]-1):
edge = (tmp_df['concept:name'][i], tmp_df['concept:name'][i+1])
duration = tmp_df['time:timestamp'][i+1] - tmp_df['time:timestamp'][i]
if edge not in duration_dict:
duration_dict[edge] = [duration]
else:
duration_dict[edge].append(duration)
for key in duration_dict.keys():
duration_dict[key] = np.mean(duration_dict[key])
Теперь можем выбрать наиболее продолжительные переходы:
edge_tuple = []
for key in duration_dict.keys():
edge_tuple.append((key, duration_dict[key]))
edge_tuple = sorted(edge_tuple, key=lambda tup: tup[1], reverse=True)
edge_tuple[:round(len(edge_tuple)/10)]
Вот что получилось в итоге:
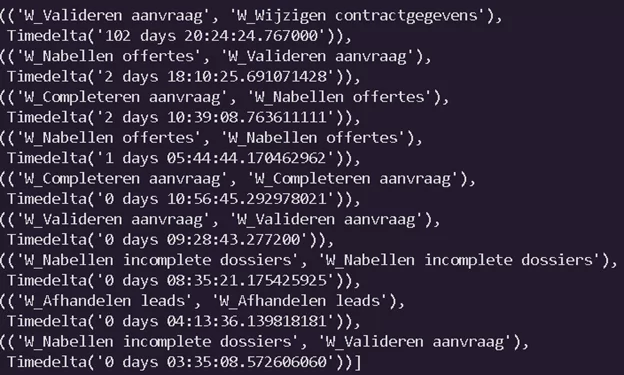
Второй способ заключается в оценке медианного времени, которое занимают переходы с учетом их количества, совершенных по данной ветке. Для реализации этого подхода создадим словарь, где ключ — это переход, а значением является массив времени переходов.
duration_dict = dict()
for i in range(t.dataframe.shape[0]-1):
edge = (t.dataframe['concept:name'][i], t.dataframe['concept:name'][i+1])
duration = t.dataframe['time:timestamp'][i+1] - t.dataframe['time:timestamp'][i]
if edge not in duration_dict:
duration_dict[edge] = [duration]
else:
duration_dict[edge].append(duration)
for key in duration_dict.keys():
duration_dict[key] = (np.mean(duration_dict[key]).days*24*3600+np.mean(duration_dict[key]).seconds)*len(duration_dict[key])
edge_tuple = []
for key in duration_dict.keys():
edge_tuple.append((key, duration_dict[key]))
edge_tuple = sorted(edge_tuple, key=lambda tup: tup[1], reverse=True)
edge_tuple[:round(len(edge_tuple)/10)]
В результате получим вот такой список

Он отличается от списка, который получился в первом случае, но тем не менее есть пересечения, на основе которых можно сделать выводы.
В итоге мы получили два различных инструмента для поиска узких мест в процессах. Инструменты являются гибкими и настраиваемыми, что позволяет применять их с различными логами процессов.
Еще больше информации о Process Mining можно найти и обсудить в канале #process_mining сообщества ODS.AI в slack