/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
В данной статье рассмотрим инструмент Hydra для работы с конфигурационными файлами на Python.

В работе датасайнтиста часто необходимо пробовать разные подходы к решению задачи, в частности различные модели и их параметры. Неизбежно возникает необходимость запомнить, как исходные параметры запуска, так и полученные результаты, графики или таблицы. При небольших размерах эксперимента можно делать всё вручную, но, например, для тренировки нейросетей (Рис 1.) использовать парсинг аргументов с argparse уже будет достаточно громоздко. Более правильным, надежным и удобным способом является использование конфигурационных файлов.
Конфигурационные файлы — файлы, используемые для настройки параметров и начальных настроек некоторых компьютерных программ. Они используются для пользовательских приложений, серверных процессов и настроек операционной системы.
Популярные форматы: .yaml, .ini, .cnf, .cfg
В этой статье мы рассмотрим использование конфигурационных файлов (в формате .yaml) вместе со специальным пакетом Hydra[1],упрощающим работу с ними. Для иллюстрации базовых возможностей библиотеки рассмотрим минимальный пример.
Для установки модуля вызываем:
pip install hydra-core --upgradeВ директории проекта создадим папку conf и в ней конфиг-файл first.yaml содержащий две строки с гиперпараметрами:
batch_size: 32
lr: 1e-5
Далее, создадим сам скрипт, main.py:
import hydra
from omegaconf import DictConfig
# декоратор необходимый для подгрузки конфигурации hydra
@hydra.main(config_path="conf", config_name="first")
def func(cfg: DictConfig):
# адрес временной папки
working_dir = os.getcwd()
print(f"Batch size is {cfg.batch_size}")
print(f"Learning rate is {cfg['lr']}")
if __name__ == "__main__":
func()
Обратим внимание на следующие моменты:
1) По умолчанию, при каждом запуске Hydra создает в директории скрипта отдельную папку по адресу: outputs/ДАТА_ЗАПУСКА/ВРЕМЯ_ЗАПУСКА/, куда складываются лог-файлы, конфигурация запуска и куда также можно сохранить результаты работы своего скрипта. Адрес папки получается так: working_dir = os.getcwd().
2) Для подключения гидры в проект, нужно перед методом, где будут использоваться прописанные в конфиг-файл параметры разместить декоратор: @hydra.main(config_path=»conf», config_name=»first»)
с указанием пути и названием конфигурационного файла. В качестве аргумента функции указывается cfg: DictConfig.
3) Параметры из конфиг-файла доступны по умолчанию в переменной cfg, например cfg.batch_size.
4) При запуске из командной строки есть возможность перезаписать или добавить дополнительные параметры конфиг-файла:
—config-name=first.yaml lr=2 +some_new_arg=1.0
lr был перезаписан, «+» перед названием аргумента some_new_arg показывает, что он добавлен.
Существует возможность сгруппировать конфигурации в отдельные файлы. Например, мы хотим протестировать для нашей модели различные оптимизаторы. Для этого можно создать новую директорию conf/optimizers и поместить в неё несколько конфиг-файлов для каждого из оптимизаторов.
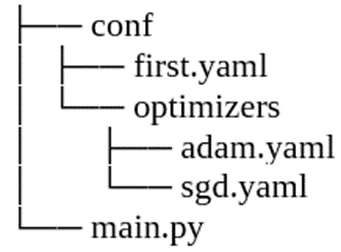
Содержание файла adam.yaml, в нём находятся параметры оптимизатора adam:
beta_1: 0.9
beta_2: 0.99
Теперь если добавить в first.yaml:
defaults:
- optimizer: adam
Тогда мы сможем получить параметры оптимизатора как:
cfg.optimizer.beta_1
cfg.optimizer.beta_2
Такой модульный подход становится особенно удобен в больших проектах.
Ещё одной интересной возможностью библиотеки является перебор нескольких конфигураций за один запуск. Предположим, мы создали ещё две конфигурации для использования различных датасетов: titanic и households.
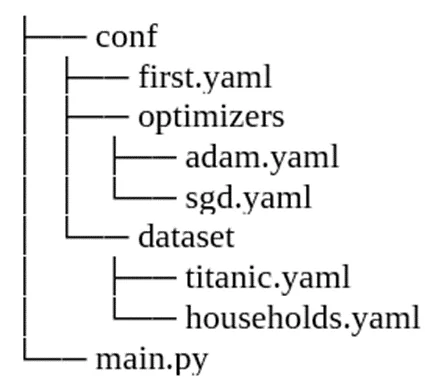
Тогда, чтобы перебрать все 4 доступные комбинации, нужно запустить:
—config-name=first.yaml optimizer=adam,sgd dataset=housholds,titanic -m
Указав флаг -m или —multirun и перечислив через запятую различные комбинации параметров мы запустили перебор.
Для сохранения результатов будет создана отдельная директория /multirun/.
Рассмотренное выше является лишь частью всех возможностей библиотеки Hydra. Ознакомиться с остальными функциями, такими как лаунчеры (позволяют выполнять код параллельно или даже удалённо на серверах AWS), свиперы (оптимизируют определённую метрику перебирая разные конфигурации) и многим другим можно в документации: https://hydra.cc/docs/intro/.
[1] Hydra framework: https://hydra.cc/