/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 7 мин.
Ранее были рассмотрены простые методы работы с Dataframe на C# и теперь знаем, как создать Dataframe и сохранить его в файл, как получить значения из строк и столбцов, как добавить и удалить столбец в таблице. В данном материале разберемся с тем, как:
- выполнить индексацию строк и столбцов;
- отсортировать строки и столбцы;
- выбрать строки по условию;
- объединить таблицы.
Индексация строк и столбцов
Предположим, вы считали данные из файла, в котором колонки не проиндексированы. Чтобы это исправить можно использовать метод IndexColumnsWith. Результат выполнения данного метода нужно обязательно присвоить в Dataframe. Аналогичным же образом можно проиндексировать строки Dataframe или изменить индексы строк. В данном примере мы создаем массив индексов, начиная с 4, на 10 элементов и используем его для переиндексации строк.
// индексация столбцов
df = df.IndexColumnsWith(new[] { "Product name", "Water", "Proteins", "Fats", "Carbohydrates", "Kkal"});
// индексация строк
var index_mas = Enumerable.Range(4, 10).ToArray();
df = df.IndexRowsWith(index_mas);
Если нужно проиндексировать строки, начиная с нуля, то можно использовать метод IndexRowsOrdinally, здесь не нужно указывать массив индексов.
// индексация строк с 0
df = df.IndexRowsOrdinally();
При необходимости проиндексировать строки таблицы значениями из столбца, нужно использовать метод IndexRows. Нужно учитывать, что значения выбранного столбца не должны повторяться, а самого столбца в дальнейшем уже не будет в таблице.
// индексация строк значениями из столбца Kkal
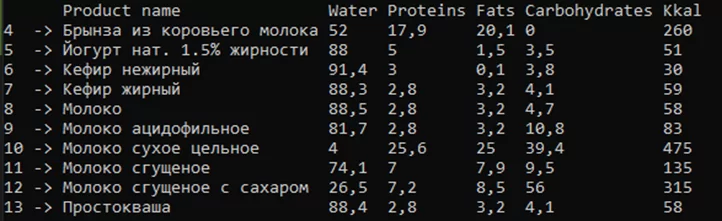
df = df.IndexRows<int>("Kkal");
Сортировка столбцов и строк
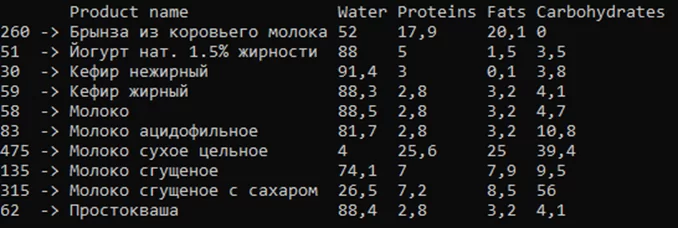
Если нужно выполнить сортировку столбцов, то необходимо использовать метод SortColumnsByKey. Если индексация была не числовая, то столбцы выстроятся в алфавитном порядке. Исходный Dataframe представлен на рисунке 1, результат сортировки на рисунке 3.
// сортировка столбцов
df = df.SortColumnsByKey();
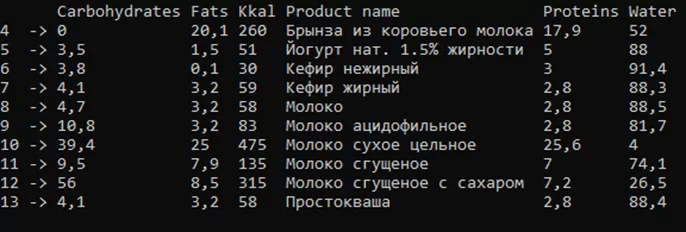
Для сортировки строк по индексам используется метод SortRowsByKey. Результат сортировки строк представлен на рисунке 4.
// исходные индексы строк
int[] index_mas = new int[10] { 15, 10, 32, 89, 2, 7, 6, 22, 31, 50 };
df = df.IndexRowsWith(index_mas);
// сортировка строк по индексам
df = df.SortRowsByKey();
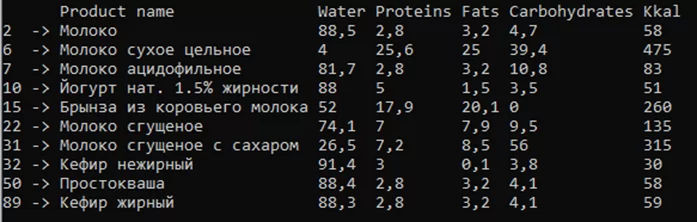
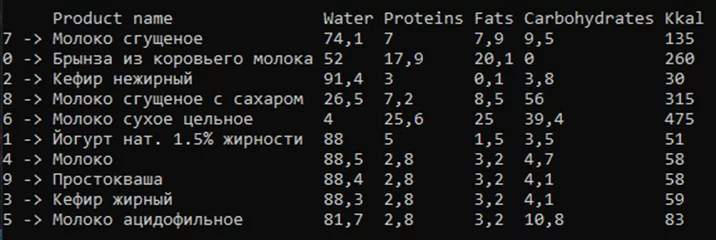
Метод SortRows позволяет отсортировать строки по указанному столбцу. При использовании данного метода сортировка данных выполняется по первому символу в столбце, результат представлен на рисунке 5.
// сортировка столбца Kkal
df = df.SortRows("Kkal");
Выбор строк по условию
Одной из популярных задач при работе с Dataframe является выбор строк по условию. Это можно сделать с помощью Where. Данный метод возвращает новый Dataframe со строками, которые были выбраны по условию. В примере ниже, r – строка Dataframe, у которой получаем значения (Value) и выбираем ячейку (указываем колонку и тип данных), в которой нужно проверить значение. Условие для выбора может быть и сложным, части условия соединяются через && или ||.
// выбор строк, которые в столбце «Product name» содержат слово молоко
var df1 = df.Where(r => r.Value.TryGetAs<string>("Product name").ValueOrDefault.ToString().ToLower().Contains("молоко"));
// выбор строк, значения которых в столбце «Proteins» больше 7
// или в столбце «Kkal» меньше 50,5
var df2 = df.Where(r => (r.Value.TryGetAs<double>("Proteins").ValueOrDefault > 7) || (r.Value.TryGetAs<double>("Kkal").ValueOrDefault < 50.5) );
в столбце «Product name»
Выбирать строки можно также обратившись к индексу строки. Выберем строки, индекс которых больше 5, результат представлен на рисунке 7.
// выбор строк, индекс которых больше 5
var df2 = df.Where(r => r.Key > 5);

Объединение таблиц
Если есть несколько таблиц, содержащих одинаковое количество столбцов, которые называются одинаково, и стоит задача объединить эти таблицы, то можно использовать Merge. Особенность использования этого метода заключается в том, что строки всех таблиц должны иметь разные индексы до объединения, то есть автоматическая переиндексация строк при объединении не происходит. Но при этом столбцы во всех таблицах могут быть в разном порядке.
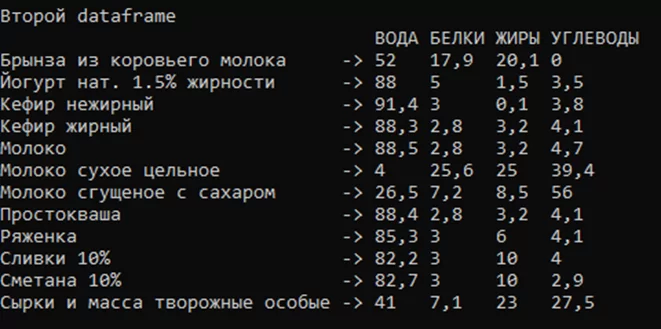
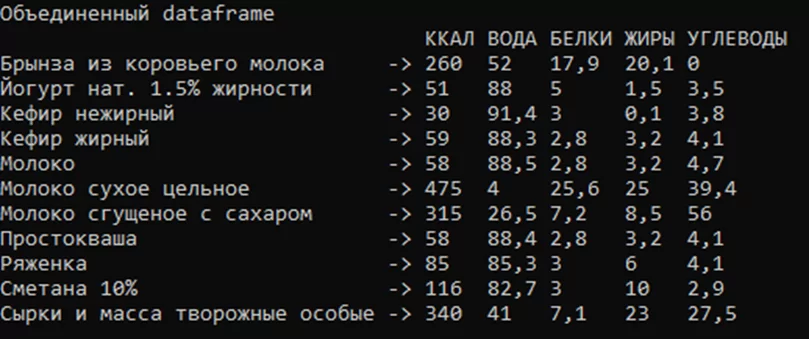
Пример объединения трех таблиц.
Создание Dataframe посредством считывания данных из csv-файла было рассмотрено в предыдущей статье. По умолчанию все строки Dataframe проиндексированы с нуля. Для корректного объединения выполняется переиндексация строк. Для этого находится количество строк в каждом Dataframe, создается два массива с индексами и выполняется переиндексация с помощью метода IndexRowsWith.
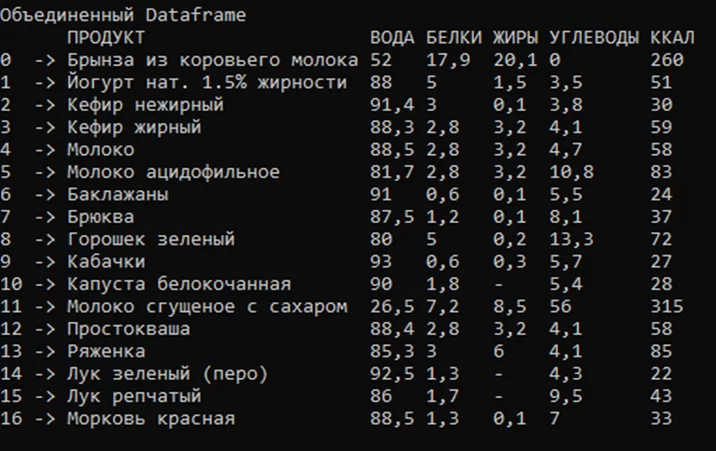
Для объединения таблиц необходимо вызвать метод Merge, в скобках указывается Dataframe через запятую. На рисунке 8 представлены три проиндексированных Dataframe, а на рисунке 9 – объединенный Dataframe.
// путь к файлам
string path_file = @"C:\Users\Admin\Files\K_1.csv";
string path_file_1 = @"C:\Users\Admin\Files\K_2.csv";
string path_file_2 = @"C:\Users\Admin\Files\K_3.csv";
// считывание таблицы в dataframe
Frame<int, string> df = Frame.ReadCsv(location: path_file, hasHeaders:true, inferTypes: false, separators: ";");
Frame<int, string> df_1 = Frame.ReadCsv(location: path_file_1, hasHeaders: true, inferTypes: false, separators: ";");
Frame<int, string> df_2 = Frame.ReadCsv(location: path_file_2, hasHeaders: true, inferTypes: false, separators: ";");
// подсчет количества строк в каждом dataframe
int count_rows_df = df.RowCount;
int count_rows_df_1 = df_1.RowCount;
int count_rows_df_2 = df_2.RowCount;
// выполнение переиндексации строк во второй и третьей таблицах
var index_mas = Enumerable.Range(count_rows_df, count_rows_df_1).ToArray();
df_1 = df_1.IndexRowsWith(index_mas);
var index_mas_1 = Enumerable.Range(count_rows_df + count_rows_df_1, count_rows_df_2);
df_2 = df_2.IndexRowsWith(index_mas_1);
// соединение трех таблиц в одну
df = df.Merge(df_1, df_2);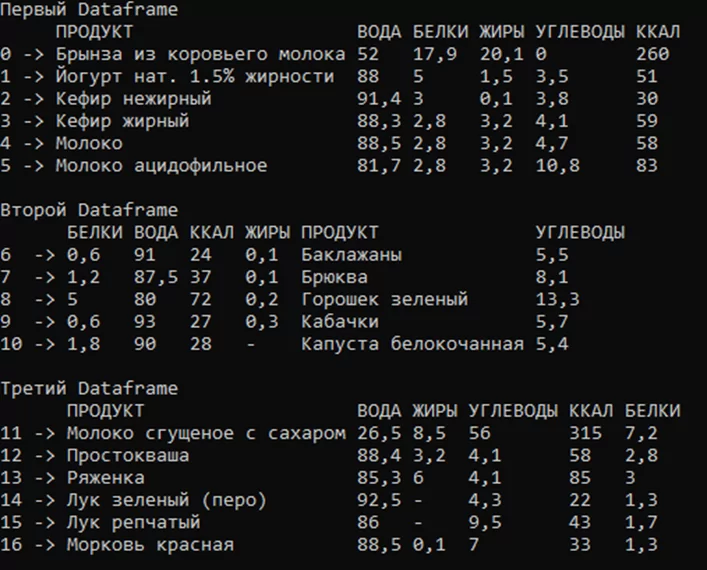
Соединение двух таблиц по индексам возможно с помощью метода Join. Названия столбцов в разных таблицах, в этом случае, не должны повторяться. Если же есть желание объединить таблицы по конкретному столбцу, то необходимо этот столбец сделать индексом (значения в столбце не должны повторяться). Рассмотрим, как это можно сделать.
Создается Dataframe посредством считывая данных из csv-файла, в данном случае индексами строк будут целые числа, начиная с 0, изменить тип индекса при чтении данных нельзя. Но тип индекса можно изменить, выполнив переиндексацию строк с помощью метода IndexRowsByString и создав новый Dataframe. В методе указывается название столбца, который станет новым индексом, и исходный Dataframe. Далее можно объединить две таблицы с помощью Join, выбрав способ соединения: Left, Right, Inner, Outer. На рисунках 10 и 11 представлены два Dataframe после того, как была выполнена переиндексация. На рисунке 12 итоговый объединенный Dataframe.
// путь к файлу
string path_file = @"C:\Users\Admin\Files\Merge1.csv";
string path_file_1 = @"C:\Users\Admin\Files\Merge2.csv";
// считывание таблицу в dataframe
Frame<int, string> df = Frame.ReadCsv(location: path_file, hasHeaders:true, inferTypes: false, separators: ";");
Frame<int, string> df_1 = Frame.ReadCsv(location: path_file_1, hasHeaders: true, inferTypes: false, separators: ";");
// переиндексация dataframe
Frame<string, string> df1 = FrameModule.IndexRowsByString("ПРОДУКТ", df);
Frame<string, string> df2 = FrameModule.IndexRowsByString("ПРОДУКТ", df_1);
// объединение двух dataframe
df1 = df1.Join(df2, JoinKind.Inner);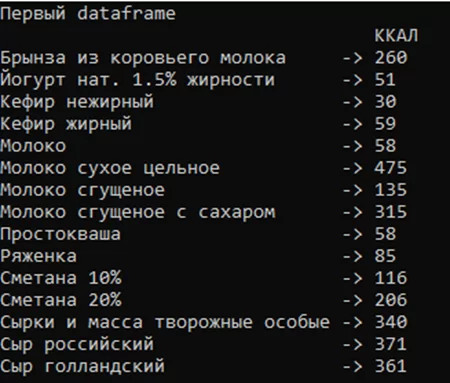
В данной статье рассмотрены способы индексации и сортировки строк и столбцов, выбор строк из Dataframe по условию, также представлен способ составления сложного условия для выбора данных и объединения Dataframe с помощью методов Join и Merge.