/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 6 мин.
Process mining – это технология изучения, мониторинга и оптимизации процессов путём применения специальных алгоритмов к журналам событий.
Анализируя модели бизнес-процессов, можно:
- находить основные клиентские пути
- обнаружить лишние действия, избыточные согласования, отмену ранее совершенных действий, задержи выполнения функций, неэффективных исполнителей
Для решения подобного рода задач, в декабре 2020 года Сбером была опубликована Python библиотека SberPM. Подробнее о ней можно почитать на Хабре.
Так, например, выглядит результат применения самых используемых алгоритмов SimpleMiner и CasualMiner на демонстрационном датасете SberPM:
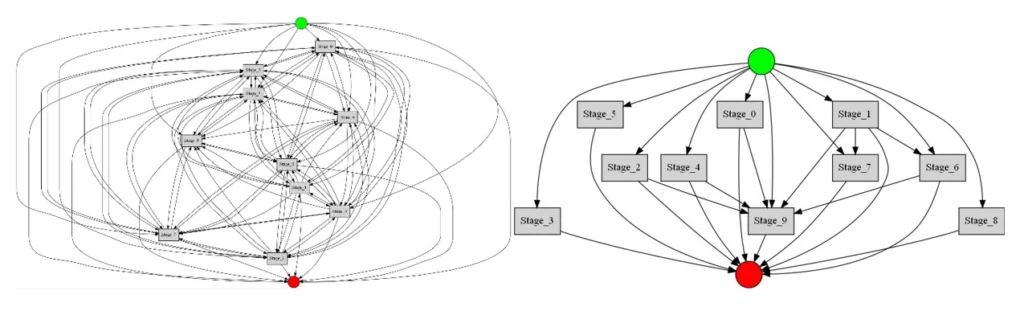
SimpleMiner – визуализирует все найденные ребра, толщина линии зависит от проходимости ребра. CasualMiner – визуализирует только однонаправленные связи
Значительная задача, с которой сталкивается программист-исследователь, постоянно работающий с задачами в области Process mining и занимающиеся проверкой большого числа гипотез – это передача параметров модели/датасета, логирование запусков и сохранение параметров, при которых получился тот или иной результат.
И если в случае двух-трёх параметров и десятка запусков такую информацию можно сохранять вручную, то при их большем числе потребуется отдельная система для управления передаваемыми параметрами, конфигурациями и логированием запусков.
К счастью, разрабатывать такую систему не придётся, ведь уже существует Hydra — фреймворк на Python с открытым исходным кодом. Он предназначен специально для проектов машинного обучения и позволяет гибко работать с конфигурациями моделей, датасетами и другими входными данными.
На сайте Hydra перечислены основные функции фреймворка:
- Иерархическая конфигурация по нескольким источникам
- Конфигурация может быть определена или переопределена из командной строки
- Автозаполнение командной строки
- Локальный или удалённый запуск приложения
- Запуск обучения моделей с разными конфигурациями одной командой
Установка Hydra не представляет никакой сложности – исчерпывающая инструкция доступна по этой ссылке. Отметим лишь особенности, которые нам пригодятся:
- Hydra меняет текущий рабочий каталог. Например, main.py лежит в src/main.py, но вывод покажет, что текущий рабочий каталог — src/outputs/2022-02-28/11-32-19
- Фреймворк будет вести журнал запуска именно в этом каталоге, там же будут и сохраняться все созданные файлы.
- Все вызовы функций логирования и переданные параметры, включая конфигурационные файлы будут сохранены в журнале запуска.
Использование фреймворка с SberPM
Теперь, когда вы знаете основные принципы работы фреймворка, можно сосредоточиться на его использовании над задачами в области Process mining.
Для примера напишем простую программу, использующую несколько демонстрационных датасетов и моделей.
Все исходные файлы, код, и получившиеся файлы находятся в публичном репозитарии по ссылке.
Датасет
Для демонстрации работы фреймворка будем использовать два датасета (журнала событий):
- example.csv — демонстрационная выборка из библиотеки SberPM
- BPI2016_Complaints.csv — выборка из соревнования BPI Challenge 2016 Complaints.
Конфигурации для них содержатся в папке conf/dataset/, в файлах example.yaml и complains.yaml
Модель
Работа с моделями осуществляется аналогично датасету. Для демонстрации работы фреймворка будем использовать пять моделей:
- SimpleMiner – рисует все найденные ребра, толщина линии зависит от проходимости ребра
- CasualMiner – рисует только однонаправленные связи
- HeuMiner – рисует только те связи, которые больше определенного порога (threshold) – чем он больше, тем меньше рёбер
- AlphaMiner – рисует граф в виде сети Петри с учётом прямых, параллельных и независимых связей между активностями
- AutoInsights – модуль автоматического поиска инсайтов, позволяющий выявлять узкие места процесса и визуализировать из на графе
Конфигурационный файл каждой модели будет содержать только имя модели (например, name: simple), за исключением HeuMiner поскольку он содержит дополнительный параметр threshold = 0.8.
Основной код
На примере написанной программы разберем, как Hydra работает с другой библиотекой (в нашем случае SberPM).
Начало главной функции, в которую будут передаваться параметры запуска:
# Использование шаблона "декоратор" над главной функцией my_app
# Обязательная часть при использовании sberpm
@hydra.main(config_path='conf', config_name='config')
def my_app(cfg : DictConfig) -> None:
Внутри неё объявлены две функции.
create_dataset() загружает датасет
def create_dataset():
full_path = hydra.utils.get_original_cwd() + '\\' + cfg.dataset.filename
df = pd.read_csv(full_path, cfg.dataset.separator, encoding='latin-1')
# Переменная для хранения датасета
data_holder = DataHolder(data = df,
id_column = cfg.dataset.id_col,
activity_column = cfg.dataset.act_col,
start_timestamp_column = cfg.dataset.time_col,
time_format = cfg.dataset.date_format)
return data_holder
mine() использует майнер из SberPM. Поскольку майнеров используется много, то и код будет большой:
# функция модели - содержит логику выбора майнера по ключу из конфига и реализует каждый вид майнера
def mine(dh):
model_name = cfg.model.name
def make_image(miner):
miner.apply()
graph = miner.graph
painter = GraphvizPainter()
painter.apply(graph)
painter.write_graph(model_name + '.' + cfg.out_format, format=cfg.out_format)
if model_name == 'simple':
from sberpm.miners import SimpleMiner
make_image( SimpleMiner(dh) )
elif model_name == 'casual':
from sberpm.miners import CausalMiner
make_image( CausalMiner(dh) )
elif model_name == 'heu':
from sberpm.miners import HeuMiner
make_image( HeuMiner(data_holder, threshold=cfg.model.threshold) )
elif model_name == 'alpha':
from sberpm.miners import AlphaMiner
make_image( AlphaMiner(dh) )
elif model_name == 'insight':
from sberpm.miners import SimpleMiner
from sberpm.autoinsights import AutoInsights
auto_i = AutoInsights(dh, time_unit='day')
simple_miner = SimpleMiner(dh)
# Transition duration
auto_i.apply(miner=simple_miner, mode=cfg.mode)
graph = auto_i.get_graph()
painter = GraphvizPainter()
painter.apply_insights(graph)
painter.write_graph(model_name + '.' + cfg.out_format, format=cfg.out_format)
В конце нужно только объединить функции
# загрузка датасета и использование майнера
data_holder = create_dataset()
mine(data_holder)
Содержимое используемого программой конфига такое:
### src/conf/config.yaml
defaults:
- _self_
- dataset: example
- model: simple
out_format: jpg
mode: time
Запуск
Для запуска с параметрами установленными в config.yaml: python main.py
Запуск датасета по умолчанию, модели casual: python main.py model=casual
Множественный запуск датасета complains, модели insight во всех трёх режимах: python main.py dataset=complains model=insight mode=time,cycles,overall -m
Запуск всех комбинаций датасетов example, complains и моделей simple, casual, heu, insight: python main.py dataset=complains model=simple,casual,heu,insight -m
Полезные трюки
Показать конфигурационный файл
Напечатать конфиг без запуска программы. Использование: —cfg [выбор]. Выбор может быть:
- job – пользовательский конфиг
- hydra – конфиг фреймворка
- all – оба
Многократный запуск (в т.ч. комбинации параметров)
Основная идея – множественный запуск модели с разными параметрами с помощью одной команды. Запуск всех комбинаций датасетов example, complains и моделей simple, casual, heu, insight:
❯ python main.py dataset=complains model=simple,casual,heu,insight -m
[2022-03-29 16:42:50,289][HYDRA] Launching 4 jobs locally
[2022-03-29 16:42:50,289][HYDRA] #0 : dataset=complains model=simple
[2022-03-29 16:42:50,730][HYDRA] #1 : dataset=complains model=casual
[2022-03-29 16:42:51,041][HYDRA] #2 : dataset=complains model=heu
[2022-03-29 16:42:51,523][HYDRA] #3 : dataset=complains model=insight
Фреймворк запустит программу со всеми возможными комбинациями dataset и model. Результат будет сохранён в каталог multirun (вместо outputs). Структура папки после запуска:
multirun
└── 2022-03-29
└── 16-42-49
├── 0
│ ├── .hydra
│ └── main.log
│ └── simple.jpg
├── 1
│ ├── .hydra
│ └── main.log
│ └── casual.jpg
├── 2
│ ├── .hydra
│ └── main.log
│ └── heu.jpg
├── 3
│ ├── .hydra
│ └── main.log
│ └── insight.jpg
└── multirun.yaml
Получилось то же самое, как и при обычном запуске, кроме того, что появилось 4 подпапки. В документации описаны различные режимы работы этой функции.
Весь исходный код, файлы примеров и получившиеся картинки находятся в репозитарии SberPM-parameter-management-with-Hydra
Использование Hydra вместе с SberPM сокращает время исследования журналов событий, особенно, при большом количестве параметров т.к. получившиеся система берёт на себя большую часть рутины по передаче и сохранению параметров.
Библиотека Hydra будет чрезвычайно полезной, если вы периодически меняете параметры модели, константы, датасеты, и, если вам важна воспроизводимость. Также стоит отметить, что библиотека поддерживается и постоянно развивается. Из недостатков: работает только из консоли, в Jupyter notebook запустить проблематично ссылка.