/img/star (2).png.webp)



/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 8 мин.
Sweetviz — это библиотека Python с открытым исходным кодом, которая генерирует отчеты с удобной визуализацией для выполнения EDA с помощью всего двух строк кода. Библиотека позволяет быстро создать подробный отчет по всем характеристикам набора данных без особых усилий. В возможности Sweetviz также входит целевой анализ, сравнение двух датасетов, сравнение двух частей датасета, выделенных по определенному признаку, выявление корреляций и ассоциаций, также sweetviz создает позволяет создавать и сохранять отчет как HTML файл.
Использование библиотеки
Установить библиотеку можно с помощью менеджера пакетов pip следующей командой:
pip install sweetvizПосле установки модуля подключаем его к проекту, добавив в код программы соответствующую команду:
import sweetviz as svТеперь мы можем воспользоваться всеми функциями данной библиотеки.
Sweetviz создает отчет из объекта DataFrame. Поэтому кроме нее нам необходимо подключить библиотеку pandas:
import pandas as pdДля того, чтобы создать отчет, необходимо в одну из функций analyze(), compare()или compare_intra() подать объект DataFrame. Для этого создадим DataFrame, загрузив данные из csv файла с помощью функции pd.read_csv():
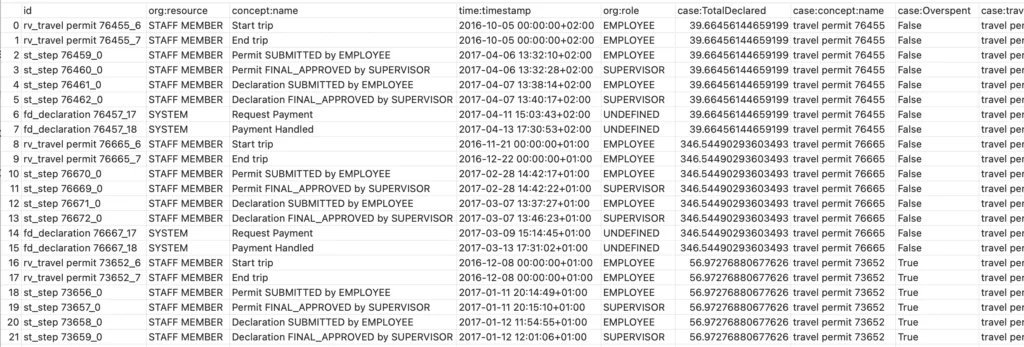
df = pd.read_csv('PermitLog.csv')В нашем случае набор данных содержит события, относящиеся к заявкам на командировочные расходы, собранные в университете за 2 года. Этот датасет содержит большое число строк и столбцов, поэтому автоматизация создания наглядного отчета может в значительной мере упростить процесс EDA.
Функция analyze() служит для формирования отчета по одному датасету. Применим ее к полученному объекту DataFrame (в качестве параметра в функцию можно подать либо только датафрейм, либо список из датафрейма и строки – названия датасета для большей информативности отчета; в нашем случае назовем его как «Permit Logs»):
report = sv.analyze([df, " Permit Logs"])Функция analyze() возвращает объект DataframeReport, который мы поместили в переменную report.
Для сохранения отчета в HTML файл необходимо применить к переменной report функцию show_html(). В качестве аргумента подаем название файла, под которым хотим сохранить отчет:
report.show_html('common analysis.html')Сформированный отчет выглядит следующим образом:
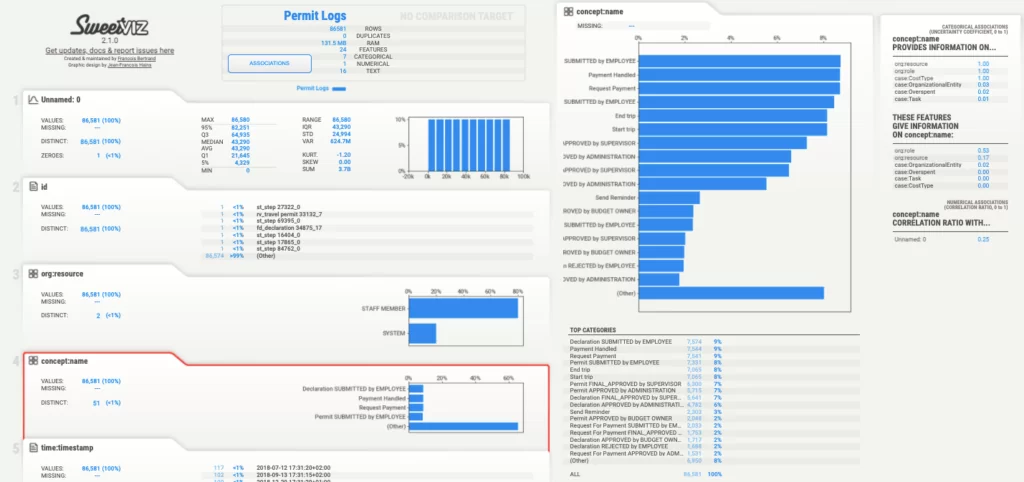
На рисунке выше видно, что отчет включает в себя информацию по каждому столбцу датасета. При нажатии на конкретный столбец из левой части страницы можно получить по нему более детальную информацию.
Как видно на представленном рисунке, был выбран столбец «concept:name». Данный столбец содержит названия событий, такие как «Start trip», «End trip», «Permit SUBMITTED by EMPLOYEE» и т.д. На графике справа наглядно представлено, какую часть от общего количества составляет конкретный тип события. Под графиком видим таблицу с наиболее часто встречающимися значениями столбца, а справа от графика – значения коэффициентов неопределенности и корреляции. Таким образом, с помощью подобного отчета легко представить общую картину всего набора данных.
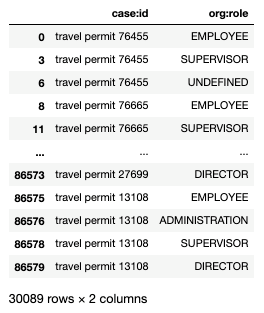
Теперь рассмотрим, как с помощью Sweetviz можно проанализировать определенные столбцы датасета. Допустим, мы хотим узнать, кто и в какой степени принимает участие в согласовании заявок на командировочные расходы. Для этого создадим датафрейм со столбцами «case:id» и «org:role», в которых хранятся значения уникальных id каждого события и роли сотрудников, создавших событие, соответственно. Таким образом, новый датафрейм будет хранить уникальные пары «case:id» и «org:role».
Для этого скопируем эти два столбца в новый датафрейм и удалим из него все повторяющиеся строки:
df_unique_ids_roles = df[['case:id', 'org:role']].copy()
df_unique_ids_roles.drop_duplicates()
На рисунке ниже представлен полученный датафрейм.
Далее с помощью знакомых функций analyze() и show_html() создадим отчет с названием «Unique ids and roles»:
report = sv.analyze([df_unique_ids_roles, 'Unique ids and roles'])
report.show_html('Unique ids and roles.html')
Получили отчет, представленный на рисунке ниже.
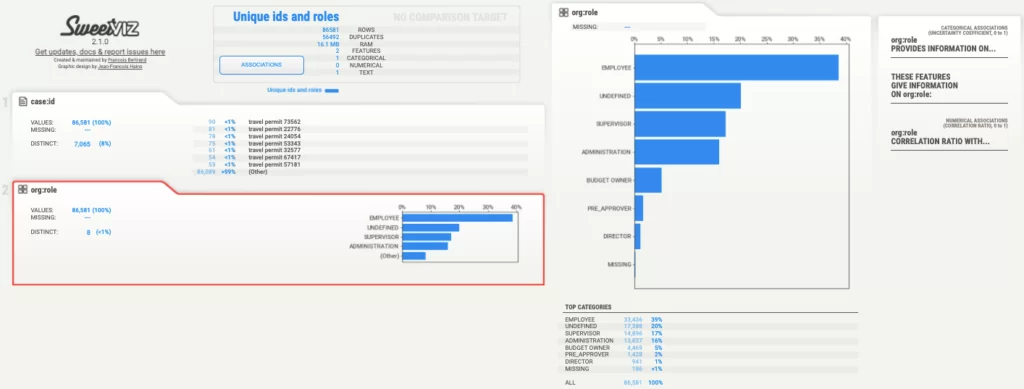
В левой части страницы в каждой вкладке, соответствующей определенному столбцу, приведена такая информация, как общее количество значений, количество отсутствующих значений и количество различных значений. Так, в согласовании заявок, связанных с командировочными расходами, выделены 8 ролей участников:
- EMPLOYEE,
- UNDEFINED,
- SUPERVISOR,
- ADMINISTRATION,
- BUDGET OWNER,
- PRE_APPROVER,
- DIRECTOR,
- MISSING.
Как можем видеть, большая часть событий приходится на работников («EMPLOYEE»). Также на графике наглядно представлено, что согласование командировочных заявок директором потребовалось лишь в малой доле случаев.
Кроме того, благодаря наглядному отчету можно заметить, что значительную часть, а именно 20 % от всех случаев, составляют события, созданные участником с ролью «UNDEFINED». С помощью той же библиотеки Sweetviz мы можем проанализировать, в каких случаях «org:role» принимает данное значение, при этом продемонстрировав принцип работы функции compare_intra().
Функция compare_intra() сравнивает две подгруппы одного датасета, разделенного по какому-либо признаку. В нашем случае в первой подгруппе будут содержаться записи со значением «UNDEFINED» в столбце «org:role», а во второй – все остальные записи.
Так, первым параметром в compare_intra() подаем исходный датасет, вторым – условие разделения датасета на подгруппы, а последним – лист с отображаемыми названиями двух подгрупп. Возвращаемый функцией compare_intra() объект DataframeReport сохраняем в переменную report и сохраняем отчет в файл «Undefined role vs other.html» функцией show_html():
report = sv.compare_intra(df, df["org:role"] == "UNDEFINED", ["Undefined role", "Other"])
report.show_html('Undefined role vs other.html')
На рисунке ниже представлен созданный отчет. В нем сравниваются значения двух датасетов по каждому столбцу. Синим цветом обозначена информация, относящаяся к первой подгруппе набора данных, а желтым – ко второй.
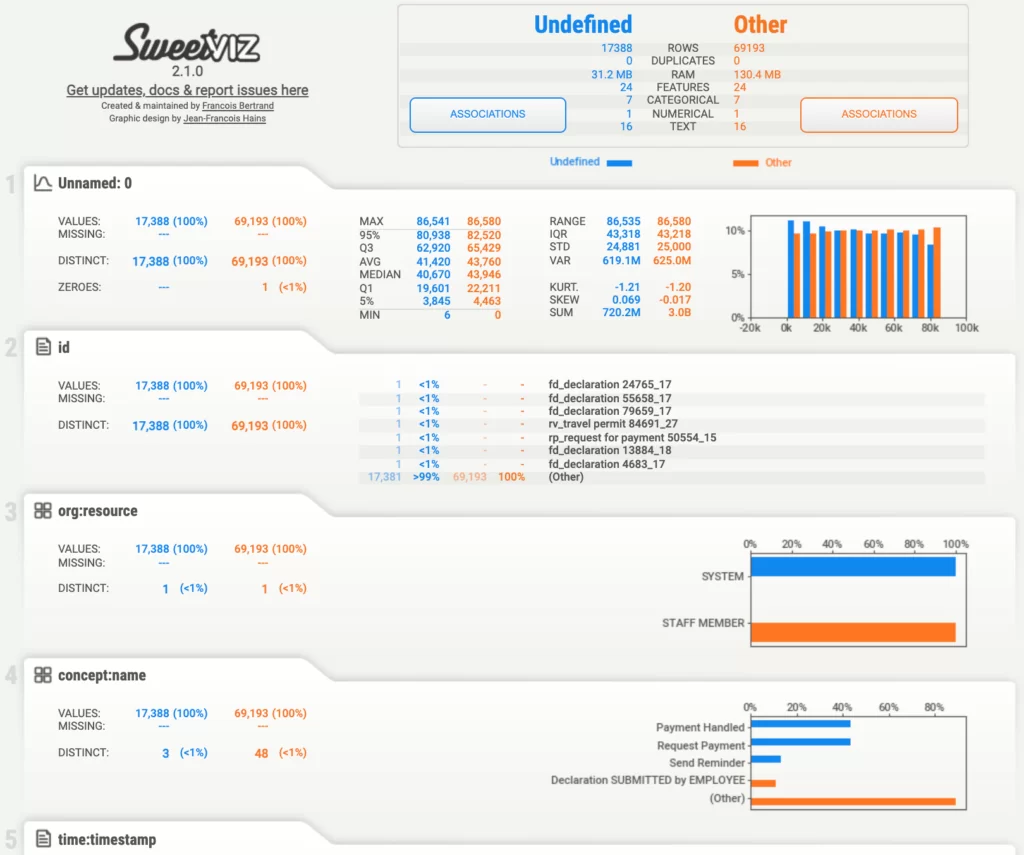
Если обратить внимание на третью вкладку («org:resource»), то можно заметить, что данный столбец принимает значения «SYSTEM» и «STAFF MEMBER», причем все записи со значением «SYSTEM» относятся к первой подгруппе, а со значением «STAFF MEMBER» – ко второй. В свою очередь во вкладке «concept:name» наглядно показано, что записи из первой подгруппы датасета принимают только значения «Request Payment» и «Payment Handled».
Таким образом, благодаря данному отчету, мы смогли понять, что значение «UNDEFINED» в столбце «org:role» означает, что событие было создано системой и является запросом или подтверждением оплаты на командировочные расходы.
Функция compare_intra() библиотеки Sweetviz сравнивает подгруппы значений в рамках одного набора данных. Если же есть необходимость сравнить два разных датасета (например, train и test), Sweetviz предлагает использовать функцию compare(). Для демонстрации работы данной функции сравним данные за период до 2018 и с 2018 года.
Для этого создадим два новых датафрейма date_before_2018 и date_after_2018:
reg_exp = '201[67]'
mask = df['time:timestamp'].str.contains(reg_exp)
date_before_2018, date_after_2018 = df[mask], df[~mask]
В коде выше для фильтрации датасета была использована так называемая маска, использующая регулярное выражение. Так, если в записи датасета в столбце «time:timestamp» находится строка, содержащая подстроки «2016» или «2017», то она будет скопирована в датафрейм date_before_2018, иначе – в date_after_2018.
Затем непосредственно создадим отчет. Передадим в функцию compare() два списка, каждый из которых содержит соответствующий датафрейм и его отображаемое название. Далее сохраняем отчет в HTML функцией show_html().
report = sv.compare([date_before_2018, 'Before 2018'], [date_after_2018, 'After 2018'])
report.show_html('date.html')
Отчет выглядит следующим образом:
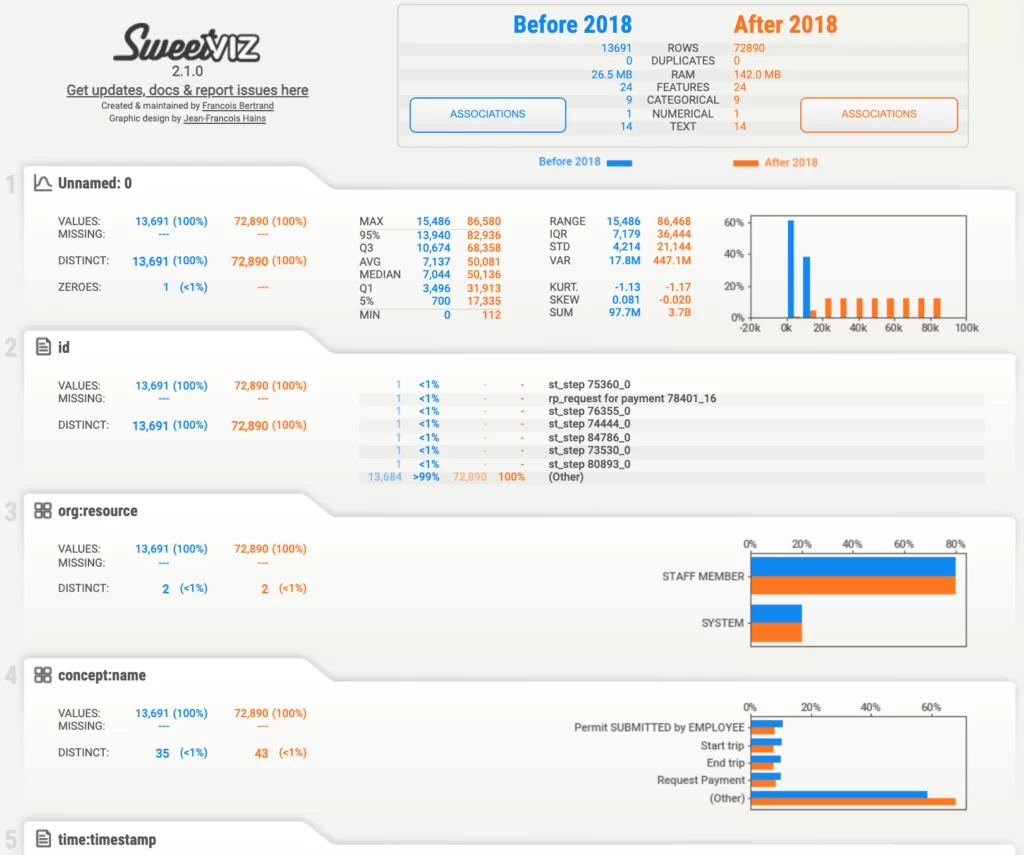
В данном отчете нас интересует вкладка «case:OrganizationalEntity», так как соответствующий столбец в исходном датасете содержит идентификаторы организационного подразделения университета, в которых происходили согласования заявок.
При обращении к данной вкладке, нам предстает следующий график:
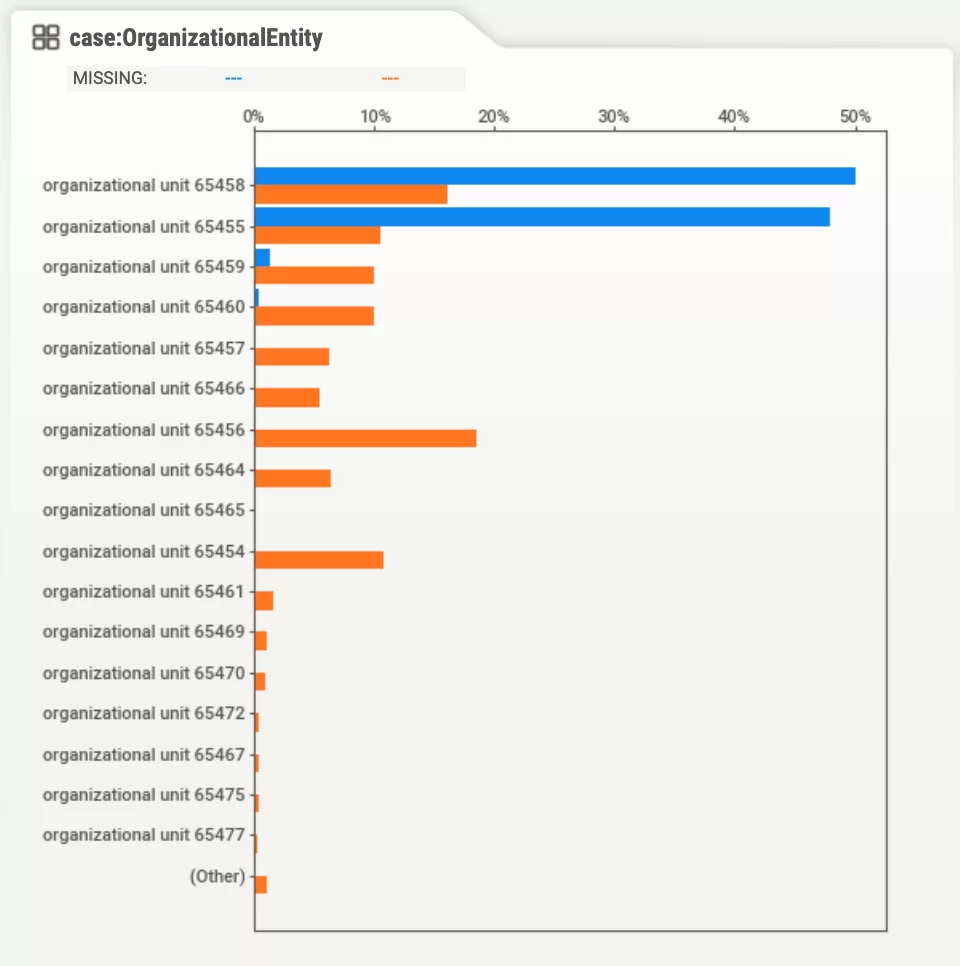
Из данного графика мы можем сделать вывод, что исходный датасет состоит из двух частей: в период до 2018 года логи заявок на командировочные расходы были собраны всего с двух организационных подразделений, тогда как в период с 2018 года записи были собраны с большего числа подразделений.
Важно отметить такую возможность библиотеки Sweetviz как целевой анализ. Такой анализ показывает, как целевое значение соотносится с другими характеристиками набора данных. На данный момент библиотека может использовать в качестве целевых только характеристики с булевыми и числовыми значениями.
Касательно нашего датасета, в нем присутствует столбец «case:Overspent», показывающий, случилось ли превышение выделенных на командировочные расходы средств. Соответственно, данный столбец содержит значения «True» и «False». Поэтому с помощью Sweetviz мы можем создать отчет, показывающий, значения целевой характеристики «case:Overspent» на фоне остальных. Для этого используем функцию analyze() с добавлением именованного параметра target_feat со значением, равным названию целевой характеристики:
report = sv.analyze([df, 'Target: case:Overspent'], target_feat='case:Overspent')
report.show_html('target overspent.html')
Получившийся отчет:
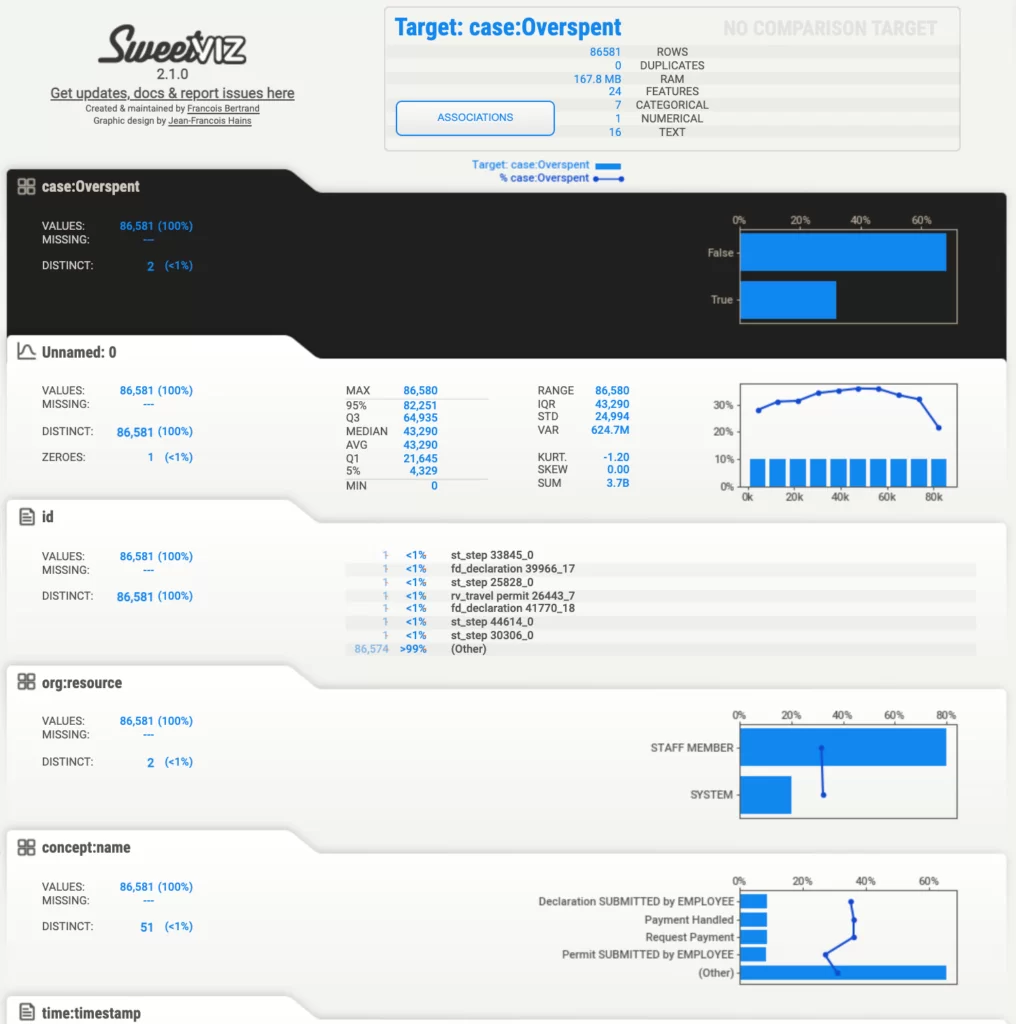
Как мы видим на рисунке выше, вкладка с целевой характеристикой выделена черным цветом, а на остальных вкладках кроме знакомых нам гистограмм присутствует график распределения значений «case:Overspent».
Наиболее интересно распределение данной характеристики на фоне организационных подразделений:
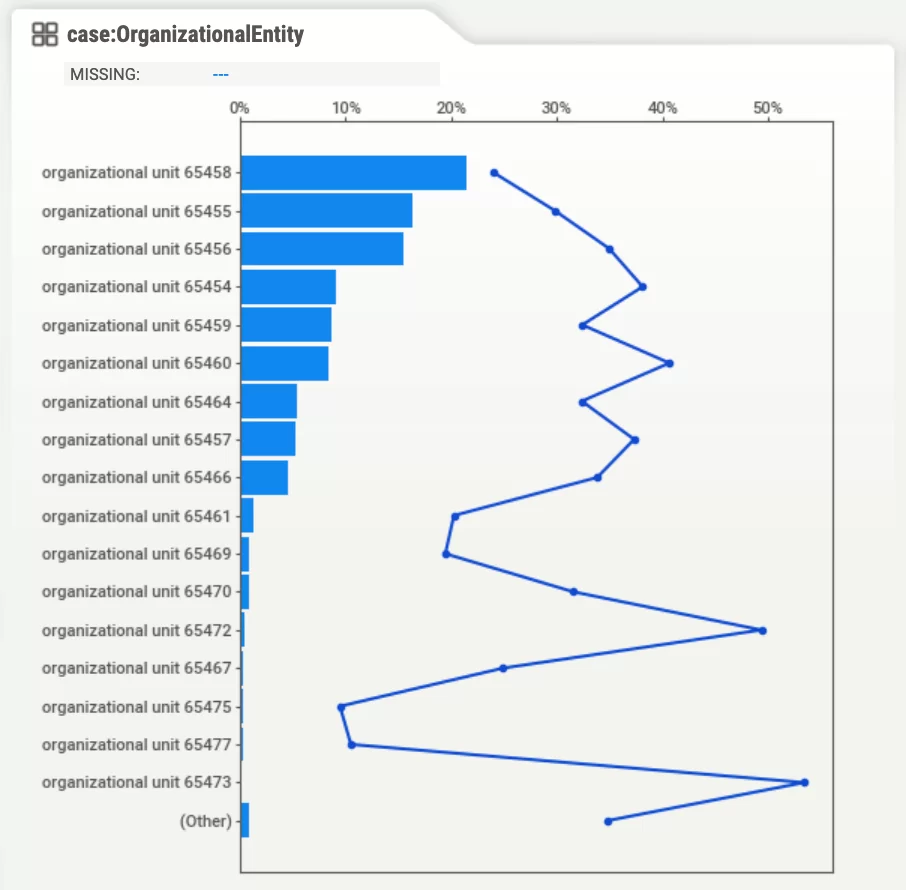
На графике выше можем увидеть, какую составляют случаи, в которых произошло превышение заявленного бюджета на командировочные расходы, в каждом подразделении университета.
Выводы
Библиотека Sweetviz является мощным и крайне полезным для предварительного анализа данных, позволяющим с помощью всего двух строк кода визуализировать информацию для комфортного исследования и выявления зависимостей и аномалий в больших наборах данных. С помощью трех основных функций (analyze(), compare(), compare_intra()) библиотека позволяет создавать отчеты, помогающие проводить полный и целевой анализы и сравнение датасетов или его групп.