/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Представьте, что вы только недавно начали работать data аналитиком в крупной компании. Испытательный срок закончился и сегодня утром на планёрке руководитель отдела поручил вам первую настоящую задачу. Необходимо проанализировать данные, которые поступили из головного офиса. Так как это ваша первая задача, руководитель хочет чтобы вы проанализировали данные на предмет отклонений и подготовили отчёт.
В первую очередь вы знакомитесь с данными. Видите, что они содержат информацию о клиентах (id), процентных ставках по депозиту, клиентских менеджерах (id) и номере филиала, где работает клиентский менеджер. Кажется, что задача не такая сложная, но когда вы видите объём этих данных, то ваш энтузиазм начинает угасать с каждой минутой.
С ужасом в глазах вы подходите к своему наставнику и просите о помощи:
- Константин, у меня проблема. Как я могу проанализировать такой объём данных? Данных так много, что в Excel это просто невозможно открыть.
- Хм.. Excel? Используй Qlik Sense. В нём можно подключиться к базе данных (источнику данных) напрямую и анализировать данные в одном приложении.
- Qlik Sense? Я думал, это приложение только для построения отчётов (визуализации данных).
- Нет. Qlik Sense — мощное и полноценное аналитическое решение с широким функционалом, которое в т.ч. позволяет построить визуализацию.
- Спасибо!
Конечно, это выдуманная история, однако она показывает трудности с которыми вы рано или поздно столкнетесь, особенно при анализе больших данных.
На портале NTA размещена статья “Qlik Sense. Опыт применения” Натальи Розенталь (https://newtechaudit.ru/qlik-sense/). Прочитав её вы познакомитесь с базовым функционалом и созданием простого отчёта. В этой статье мы не будет затрагивать данные темы.
Предлагаю вам попробовать вместе со мной проанализировать подготовленный синтетический dataset и рассмотреть некоторые возможности инструментов Qlik Sense при анализе данных.
Наши данные получены из базы данных и соответственно имеют определённую структуру и внешний ключ, по которому соединяются таблицы. После загрузки данных Qlik Sense автоматически связал таблицы. В приложении мы можем посмотреть модель данных. В нашем случае она представлена следующим образом:
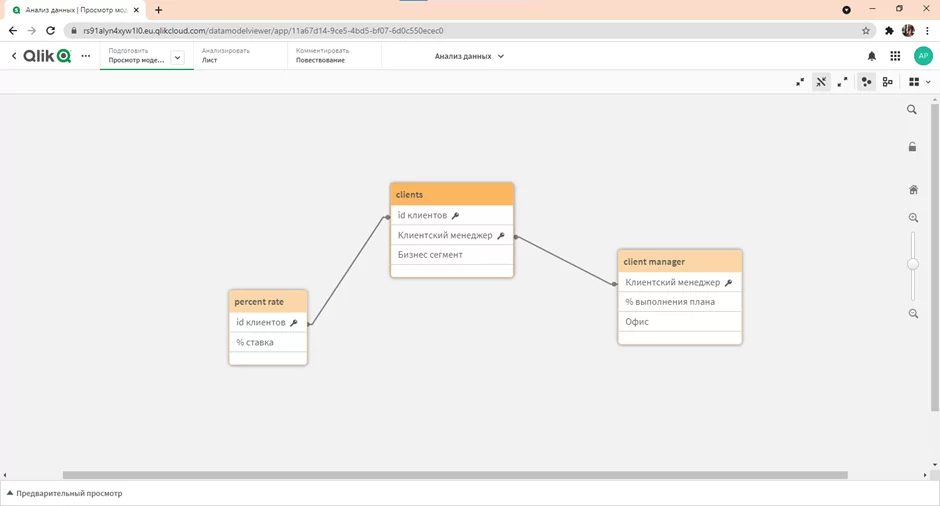
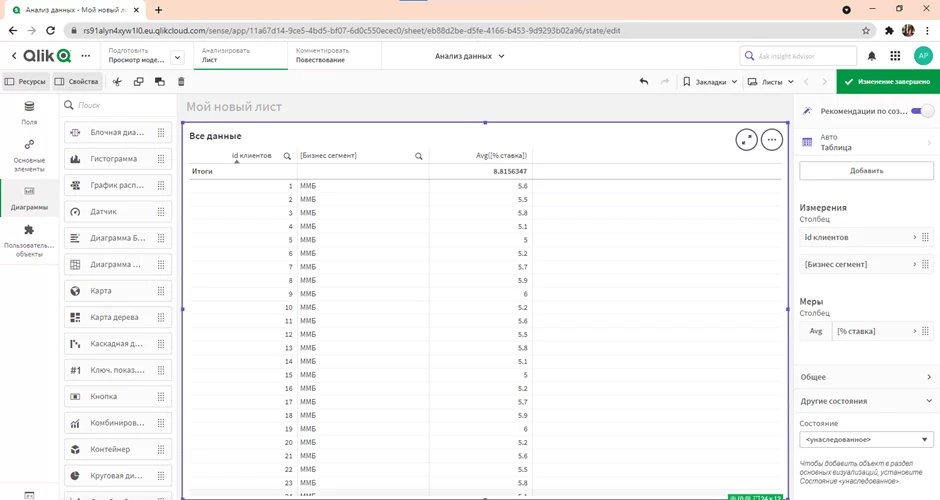
Для начала перейдём на вкладку “лист” и посмотрим на данные в целом. Добавив на лист основные поля (id клиента, бизнес сегмент, процентная ставка) видим, что средняя ставка по всем клиентам составляет 8,8%.
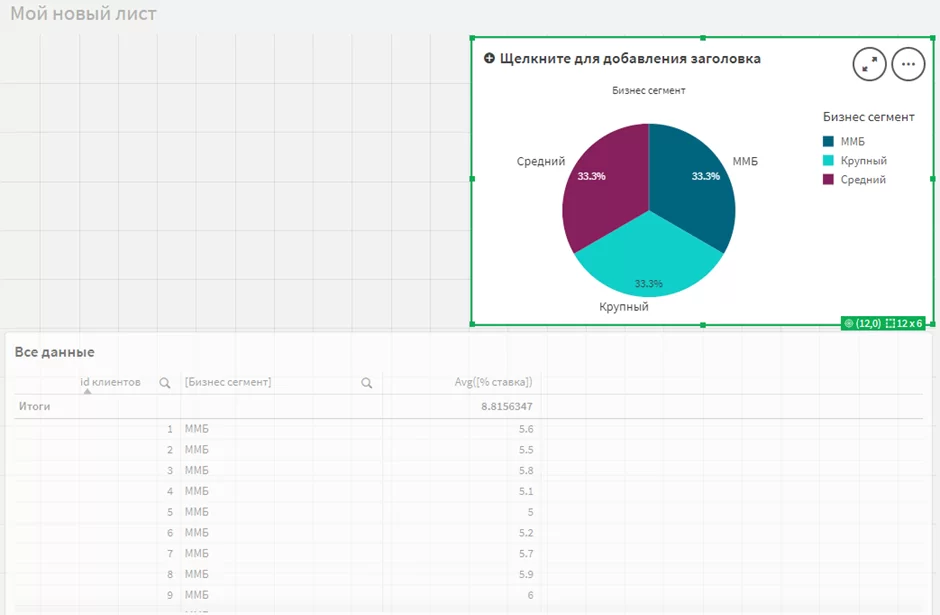
Добавив круговую диаграмму становится очевидно, что наши клиенты разделены на 3 равные части в разрезе бизнес сегмента.
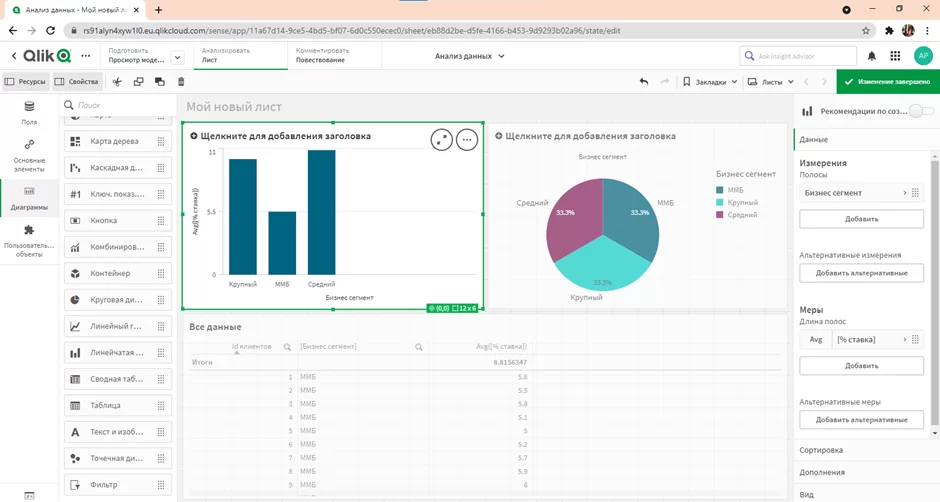
Хорошо, с распределением клиентов по бизнес сегментам разобрались, а что с процентными ставками по каждому из сегментов? Добавим линейчатую диаграмму. Можно заметить, что ставки по сегментам “крупный” и “средний” практически в два раза выше, чем по сегменту ММБ.
Является ли это отклонением? Работа завершена? Нет. Это объясняется тем, что наша компания для сегмента ММБ размещает денежные средства на общих условиях и ставка может варьироваться в зависимости от суммы и срока размещения денежных средств, а для остальных сегментов возможно размещение средств на индивидуальных условиях. Как мы видим средняя ставка по сегментам “крупные” и “средние” практически не отличается.
На следующем шаге предлагаю использовать такой простой показатель, как стандартное отклонение (standart deviation). Стандартное отклонение показывает, как распределены значения относительно среднего в выборке. Другими словами, можно понять насколько велик разброс значений. Добавим в наше приложение элемент “таблица”. В первый столбец добавим наши бизнес сегменты, а во втором используем стандартную функцию Stdev([% ставка]).
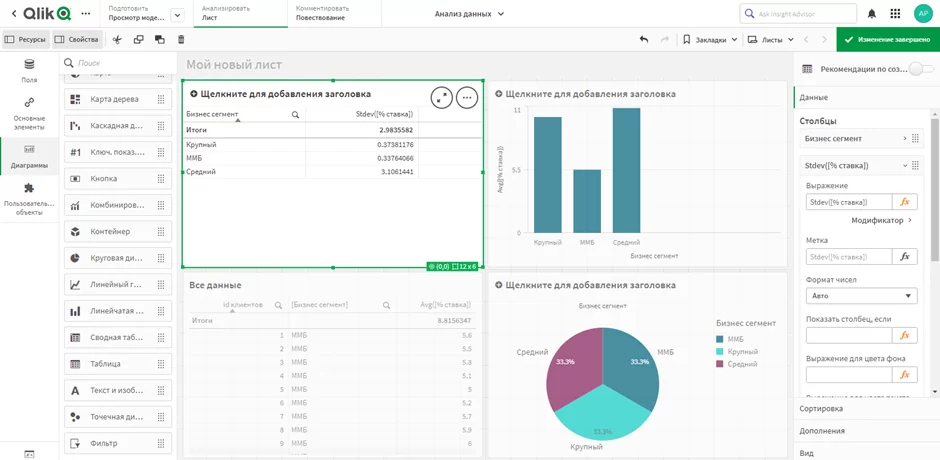
Можно заметить, что значения по сегментам “ММБ” и “Крупный” минимальны — 0.3, а по сегменту “Средний” — 3.1. Это значит, что разброс процентных ставок в данном сегменте очень большой, но с чем он связан? При том, что для клиентов сегментов “Средний” и “Крупный” возможны индивидуальные ставки, такой большой разброс это явное отклонение.
В наших данных присутствует таблица с клиентскими менеджерами, подразделениями и KPI. Мы можем проверить зависит ли процентная ставка от клиентского менеджера или какого-либо филиала. Создадим новый лист. Добавим дополнительные поля, две диаграммы с номером офиса и id сотрудника. С помощью фильтра выберем интересующий нас сегмент и аномально высокую процентную ставку.
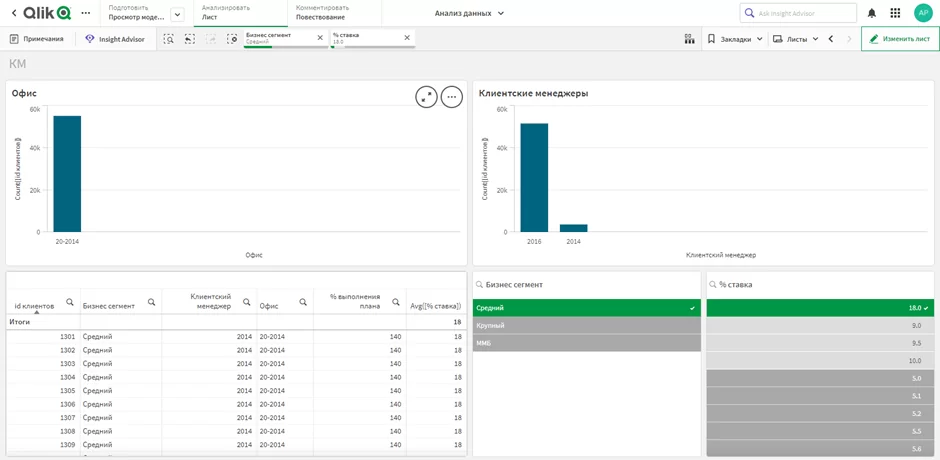
Из полученного результата можно заметить, что два сотрудника одного и того же филиала размещали денежные средства клиентов по ставке 18%. Являются ли действия сотрудников фродом? Однозначно ответить на этот вопроса на данный момент нельзя, но использованные средства позволили нам найти данные отклонения, которые как минимум требуют дальнейшего изучения.
Это всего лишь маленькая часть всех возможностей Qlik Sense для анализа данных. Большинство из них вы сможете найти в справочной документации.
Спасибо за уделённое время и удачи в ваших исследованиях!