/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Желая изучить взаимосвязь между признаками, вы, скорее всего, используете классический Scatterplot и пишете примерно такой код (стоит уточнить, что в своих примерах, я использую набор данных качества красного вина и язык программирования Python):
quality = np.unique(wine['quality'])
c = ['r', 'b', 'g', 'pink', 'cyan', 'grey']
plt.figure(figsize=(9, 6), dpi=70)
for num, qual in enumerate(quality):
plt.scatter('fixed acidity', 'density', data=wine.loc[wine.quality == qual, :],
s=20, c=c[num], label=str(qual))
plt.gca().set(ylim=(wine['density'].min(), wine['density'].max())
, xlim=(wine['fixed acidity'].min(), wine['fixed acidity'].max())
, xlabel='density', ylabel='free sulfur dioxide')
plt.yticks(fontsize=12)
plt.xticks(fontsize=12)
plt.title("Density vs fixed acidity")
И, визуализируя каждую группу в ваших данных своим цветом, получаете такой результат:
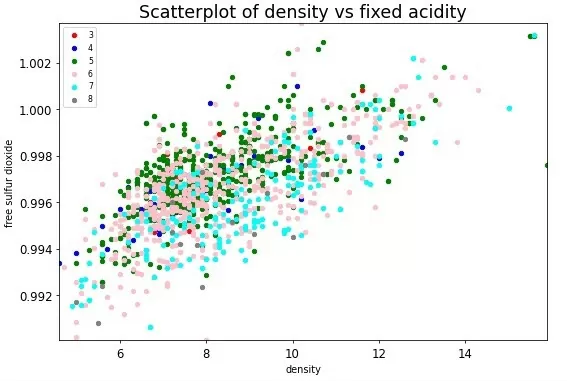
Если необходимо так же взглянуть на распределения признаков по отдельности, то вас может удовлетворить такой пример:
figure= plt.figure(None, (9, 6), dpi=70)
grid = plt.GridSpec(5, 5, wspace=0.2, hspace=0.5)
ax_mid = figure.add_subplot(grid[:-1, :-1])
ax_r = figure.add_subplot(grid[:-1, -1], xticklabels=[], yticklabels=[])
ax_bot = figure.add_subplot(grid[-1, 0:-1], xticklabels=[], yticklabels=[])
ax_mid.scatter('fixed acidity', 'density', data=wine, c=wine.quality,
s=20, alpha=.9, linewidths=.5, cmap='Set1')
ax_r.hist(wine['density'], 70, orientation='horizontal', color='cyan')
ax_bot.hist(wine['fixed acidity'], 70, orientation='vertical', color='cyan')
ax_mid.set(title='fixed acidity vs density with Histograms', xlabel='pH', ylabel='density')
ax_mid.title.set_fontsize(18)
for elem in ([ax_mid.xaxis.label, ax_mid.yaxis.label] + ax_mid.get_xticklabels() + ax_mid.get_yticklabels()):
elem.set_fontsize(12)
xlabels = ax_mid.get_xticks().tolist()
ax_mid.set_xticklabels(xlabels)
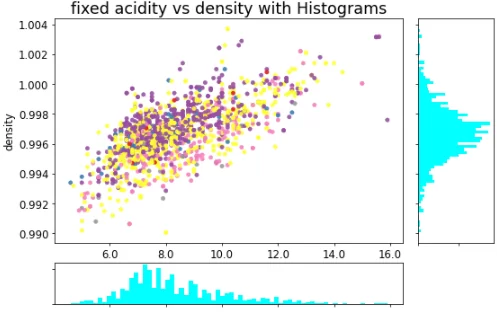
А при необходимости получить взаимосвязанные или интерактивные графики, вам, помимо стандартного mathplotlib, может понадобиться помощь таких библиотек, как bokeh:
reset_output()
output_notebook()
source = ColumnDataSource(wine)
TOOLS = "lasso_select"
TOOLTIPS = [('density', '@density'),
('fixed acidity', '@fixed acidity'),
('citric acid', '@citric acid'),
('pH', '@pH')]
p1 = figure(tooltips=TOOLTIPS, plot_width=300, plot_height=300, title='density vs fixed acidity', tools=TOOLS)
p1.circle(x='fixed acidity', y='density', source=source, fill_color=None)
p2 = figure(tooltips=TOOLTIPS, plot_width=300, plot_height=300, title='density vs citric acid', tools=TOOLS)
p2.circle(x='citric acid', y='density', source=source,fill_color=None)
p3 = figure(tooltips=TOOLTIPS, plot_width=300, plot_height=300, title='density vs pH', tools=TOOLS)
p3.circle(x='pH', y='density', source=source, fill_color=None)
p = gridplot([[p1,p2,p3]])
show(p)
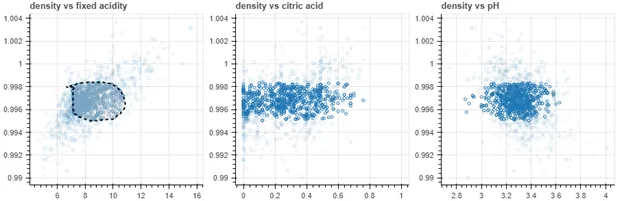
И plotly:
df = go.Scatter3d(x = wine['fixed acidity'],
y = wine['density'],
z = wine['alcohol'],
marker=dict(opacity=0.9,
colorscale='Blues',
size=5,
reversescale=True),
mode='markers')
loc = go.Layout(scene=dict(xaxis=dict(title='fixed acidity'),
yaxis=dict(title='density'),
zaxis=dict(title='alcohol')))
plotly.offline.plot({"data": [df],
"layout": loc},
auto_open=True,
filename=("Plot3D.html"))
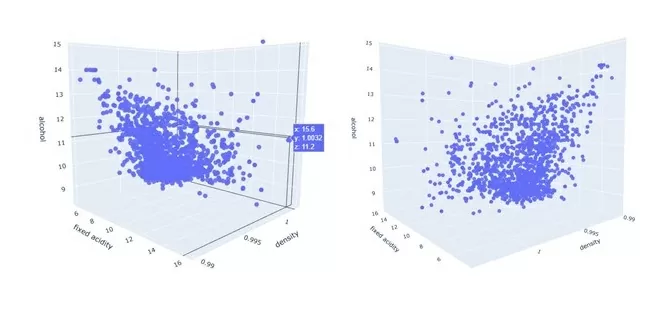
Но что, если у вас десятки таких признаков? Или вы хотите применить различные методы нормализации, выравнивания или другие методы предобработки данных, с целью посмотреть, как изменилось распределение в таком случае? Размер и сложность рукописного кода значительно увеличится, как и время на работу с данными.
Как было сказано в начале, сэкономить время может помочь программа viewpoints.
Этот инструмент визуализации предназначен для изучения больших объемов многомерных данных. И изначально был создан для их анализа в текущих и предстоящих космических научных миссий НАСА. Он позволяет быстро строить высокопроизводительные связанные диаграммы рассеяния и проводить интерактивный анализ наборов данных. Таким образом, Viewpoints позволяет быстро применять ряд полезных вещей. Его основная особенность — несколько связанных Scatterplots в 2D и 3D с выделением и наложением цвета, например, быстро выделив нужные точки одним цветом, они автоматически выделятся на других графиках.
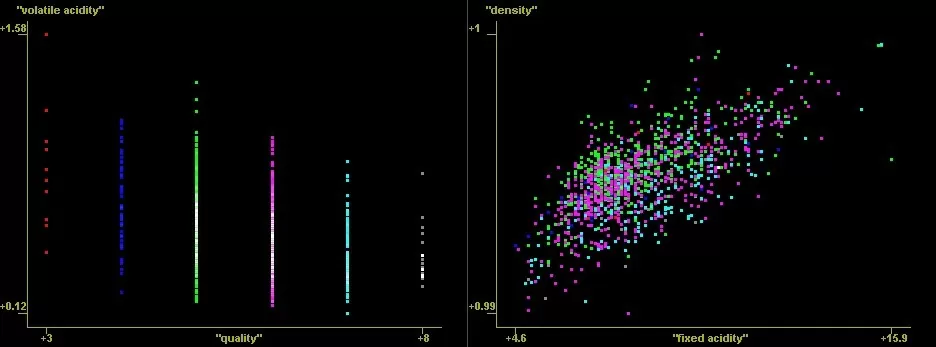
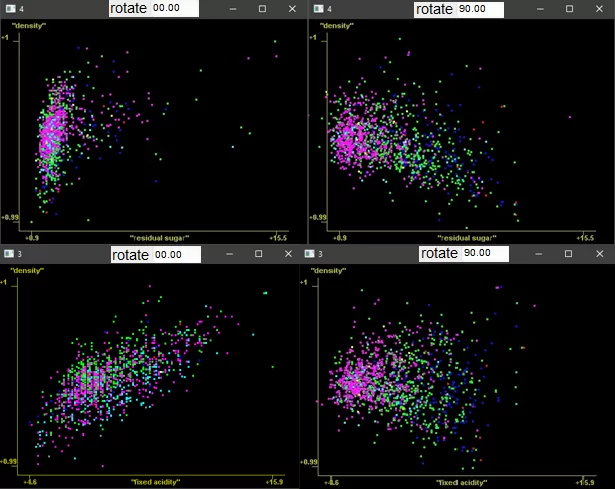
Графики можно вращать вокруг оси, приближать или растягивать для поиска лучшего распределения.
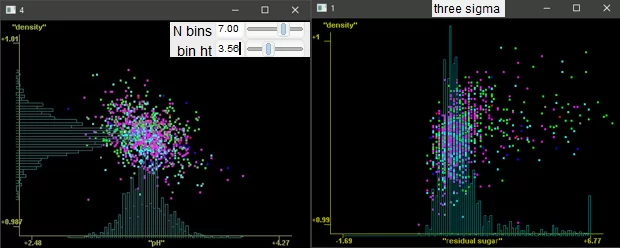
Он также поддерживает гистограммы с динамически регулируемой шириной бина и быстрое обрезание по трём сигмам:
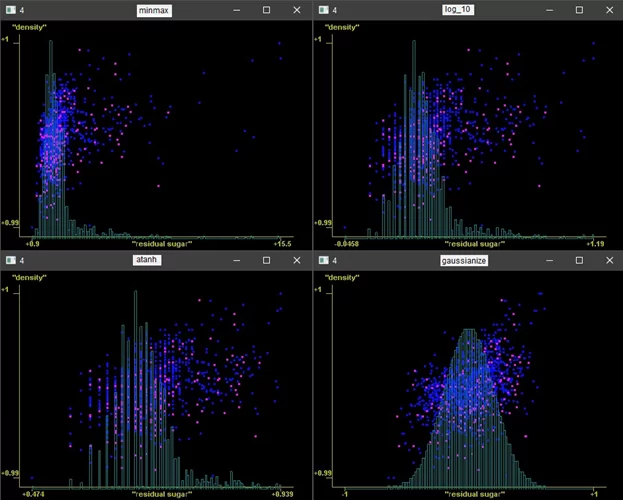
И несколько типов нормализации (линейная, логарифмическая, логистическая, усеченная, ранжированная и т. д.), Выравнивание (гауссово, равномерное и т. Д.) На следующих картинках качество вина свыше 6-ти выделено розовым, остальное синим.
Viewpoints позволяет изменять большинство параметров в режиме реального времени с немедленной визуальной обратной связью и отличается высокой производительностью при работе с большими данными, ограниченной только оперативной памятью.