/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Занимаясь поиском доступных банкоматов в г. Москва, случайно обнаружил, что не у всех банкоматов указаны ближайшие станции метрополитена (далее – метро).
Родилась идея с помощью инструментов машинного обучения (ML) создать модель поиска ближайшей станции метро для банкоматов, у которых она не указана.
Для выгрузки списка банкоматов был использован язык программирования Python и библиотека request. Каждый банкомат был выгружен в виде строки:
coordinates latitude;coordinates longitude;fullAddress;subwayStations
55.758824;37.752139;г. Москва, ш. Энтузиастов, д. 31стр39;[['Шоссе Энтузиастов', 'ЖЕЛ', '50'], ['Шоссе Энтузиастов', 'КРЖ', '230']];
Полученный датасет выглядит следующим образом:
df.head()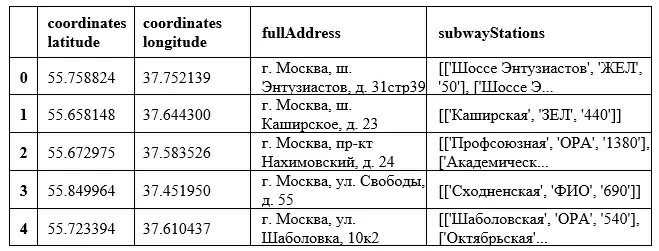
Для лучшей обрабатываемости преобразуем сначала «адрес», используя команды dataframe. str.replace и re.sub:
import re
df_address = df["fullAddress"].str.split(",", expand=True)
df_address_1 = df_address.drop(columns=[0,3,4])
df_address_1[2] = df_address_1[2].str.replace('(^\D+)|(\W+$)', '')
for i in range(len(df_address_1[2])):
if str(df_address_1[2][i]).isdigit() == False:
try:
df_address_1[2][i] = re.sub(r'(\d+$)', '', df_address_1[2][i])
except:
pass
df_address_1[2] = df_address_1[2].str.replace('(\D+$)', '')
Теперь очистим столбец станций метро:
df_metro = df["subwayStations"].str.split(",", expand=True)
df_metro = df_metro[0]
df_metro = df_metro.str.replace("'", "")
df_metro= df_metro.str.replace("[", "")
df_metro = df_metro.str.replace("]", "")
df_metro.head()
Удаляя «исходные» столбцы ‘fullAddress’, ‘subwayStations’, получаем датасет в более удобном виде:

Пустые ячейки метро заменим на «0». Очистим выборку от строк с пустыми значениями и закодируем категориальные признаки.
df.loc[df_2['subway'] == '', 'subway'] = '0'
df.dropna(inplace=True)
from sklearn import preprocessing
result = df.copy()
encoders = {}
for column in result.columns:
# если тип столбца - object, то нужно его закодировать
if result.dtypes[column] == np.object:
# для колонки column создаем кодировщик
encoders[column] = preprocessing.LabelEncoder()
# применяем кодировщик к столбцу и перезаписываем столбец
result[column] = encoders[column].fit_transform(result[column])
encoded_data = result # содержит закодированные кат. признаки
encoded_data.head()
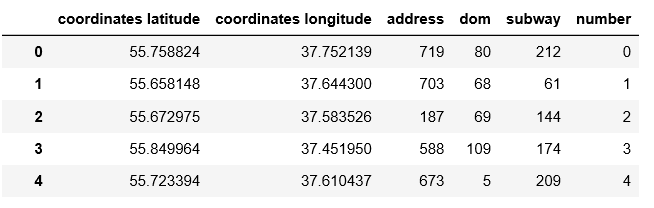
Выделим данные по метро, где нет значений в отдельный датафрейм, и удалим из основного Dataset.
encoded_data_metro = encoded_data.loc[encoded_data['subway'] == 0]
encoded_data = encoded_data.drop(encoded_data.loc[encoded_data['subway'] == 0].index)
Построим матрицу корреляций, проверим – имеются ли данные с единичной линейной зависимостью.
encoded_data_corr = encoded_data.corr()
plt.subplots(figsize=(12, 10))
sns.heatmap(encoded_data.corr(), square = True, annot=True)
plt.show()
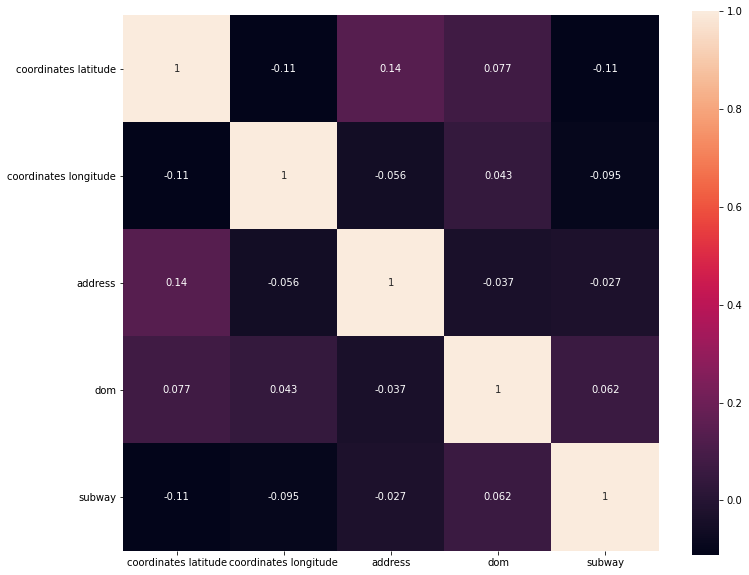
Видим, что признаки не коллинеарны. Значит все признаки могут быть использованы для создания модели.
Библиотеки, которые были использованы для создания разных моделей классификации ML: CatBoost Classifier, Gradient Boosting Classifier, Hist Gradient Boosting Classifier, XGB Classifier, LGBM Classifier.
# выбросим колонку, которую будем предсказывать
X, y = encoded_data[encoded_data.columns[0:4]].values, encoded_data[encoded_data.columns[4]].values
разделим на train и test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Создадим модели с помощью CatBoostClassifier, Gradient Boosting Classifier, XGB Classifier, LGBM Classifier (полный код по ссылке ). Для сравнения моделей напишем функцию и посмотрим где находится рассчитанная станция метро:
def proverka_model(model, name, X_search, t):
y_search = model.predict([X_search])
print(y_search)
try:
y_search = int(y_search[0])
df_r = encoded_data.loc[encoded_data['subway'] == y_search]
except:
df_r = encoded_data.loc[encoded_data['subway'] == y_search[0][0]]
n_metro = encoded_data_subway.loc[encoded_data_subway['subway'] == df_r['subway'].iloc[0]]
name_metro = df_2.loc[df_2['number'] == n_metro['number'].iloc[0]]
print(f"По расчету '{name}' ближайшая станция метро '{name_metro['subway'].iloc[0]}' для банкомата расположенного на широте и долготе: {X_search[0]}, {X_search[1]}, время формирования модели {round(t,2)}")
proverka_model(model_class, "CatBoost", X_search,time_model_class)
proverka_model(model_gb_class, "GradientBoosting", X_search, time_gb_class)
proverka_model(model_XGBC, "xgboost", X_search, time_XGBC)
proverka_model(model_LGBMC, "lightgbm", X_search, time_LGBMC)
proverka_model(gs_rfr, "Random_Forest", X_search, time_gs_rf)
[[10]]
По расчету ‘CatBoost’ ближайшая станция метро ‘Бабушкинская’ для банкомата, расположенного на широте и долготе: 55.880299, 37.694748, время формирования модели 905.05
[10]
По расчету ‘Gradient Boosting’ ближайшая станция метро ‘Бабушкинская’ для банкомата, расположенного на широте и долготе: 55.880299, 37.694748, время формирования модели 6534.01
[10]
По расчету ‘xgboost’ ближайшая станция метро ‘Бабушкинская’ для банкомата, расположенного на широте и долготе: 55.880299, 37.694748, время формирования модели 480.57
[10]
По расчету ‘lightgbm’ ближайшая станция метро ‘Бабушкинская’ для банкомата, расположенного на широте и долготе: 55.880299, 37.694748, время формирования модели 383.23
[20.35307612]
По расчету ‘Random_Forest’ ближайшая станция метро ‘Бибирево’ для банкомата, расположенного на широте и долготе: 55.880299, 37.694748, время формирования модели 45.45
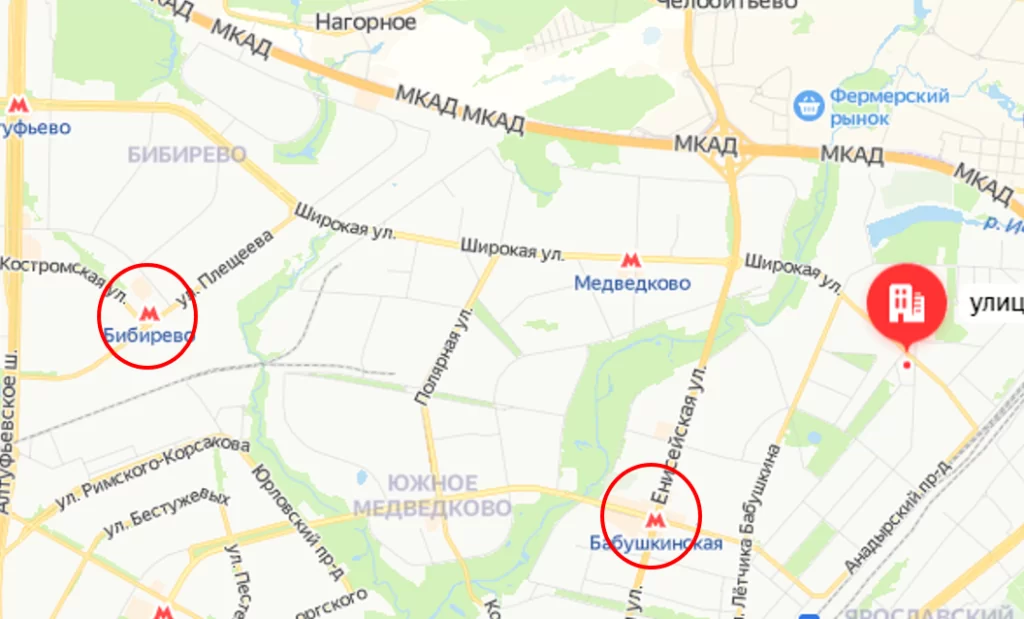
Все модели справились с указанной задачей – по времени лучшая ‘Random_Forest’, по точности: ‘xgboost’, ‘CatBoost’, ‘GradientBoosting’, а по времени и точности ‘lightgbm’. Но есть и недостатки: на карте видно, что имеется еще одна станция метро — «Медведково», но так как в обучающем датасете ее не было, то предсказать эту станцию не представляется возможным (файл с данными расположен по ссылке). Таким образом, с помощью инструментов ML можно создать модель, которая поможет нам находить близлежащую станцию метро от нашего банкомата.