/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Pandas является весьма популярной библиотекой Python и позволяет работать с двумерными таблицами данных. Scikit-learn – пакет для Machine Learning, с помощью которого в т.ч. проводится предварительная обработка данных.
В Pandas есть два вида структур данных – это DataFrame и Series. В этой статье я покажу примеры использования различных методов Pandas для обработки сформированного DataFrame. Pandas DataFrame — двумерная потенциально неоднородная структура табличных данных с изменяемым размером и помеченными осями (строки и столбцы). Основные три компонента Pandas DataFrame – данные, строки, столбцы.
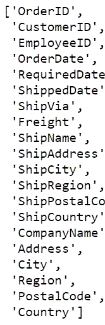
Получаем имена столбцов фрейма данных.
Для начла в рассмотренном примере сформируем DataFrame из csv-файла (фрагмент файла ordersQry.csv, открытого в Notepad++, представлен на рисунке ниже).
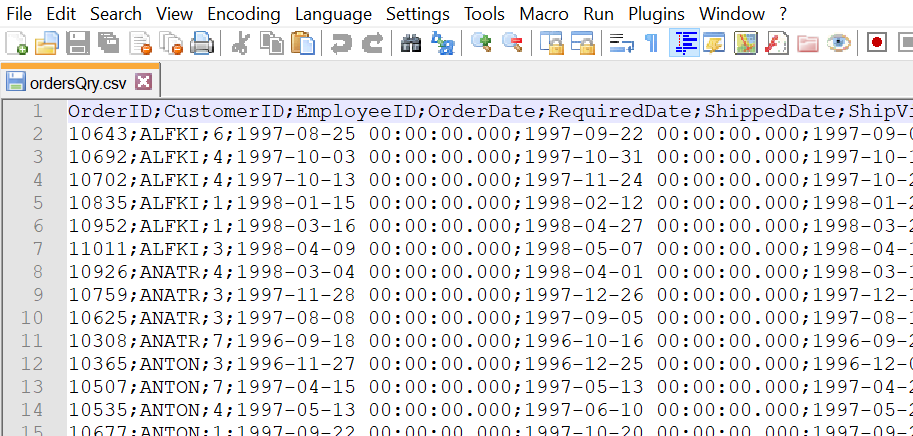
Кроме того, отмечу, что в реальности Pandas DataFrame может быть создан путем загрузки данных из хранилища данных, которое может быть базой данных SQL, файлом Excel или может быть создан из списков, словаря, списка словарей и т. д.
Начнем с установки библиотеки pandas.
pip install pandasСформируем DataFrame.
import pandas as pd
# создаем DataFrame
df = pd.read_csv("c:/Temp/ordersQry.csv", sep =';')
# вызываем метод head(), сохраняем в переменной
dataTop = df.head(5)
# вывод на экран
dataTop
Фрагмент результата:
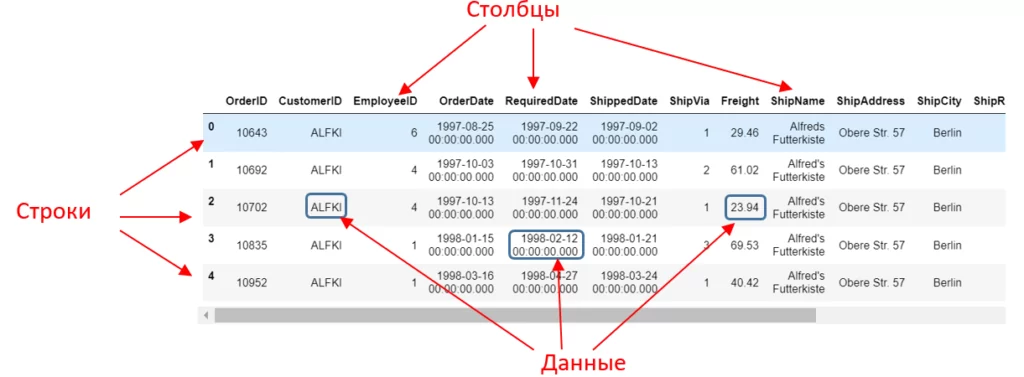
Далее получим имена столбцов различными способами.
Простой перебор столбцов.
for col in df.columns:
print(col)
Вывод:

Или список столбцов:
list(df.columns)Вывод:
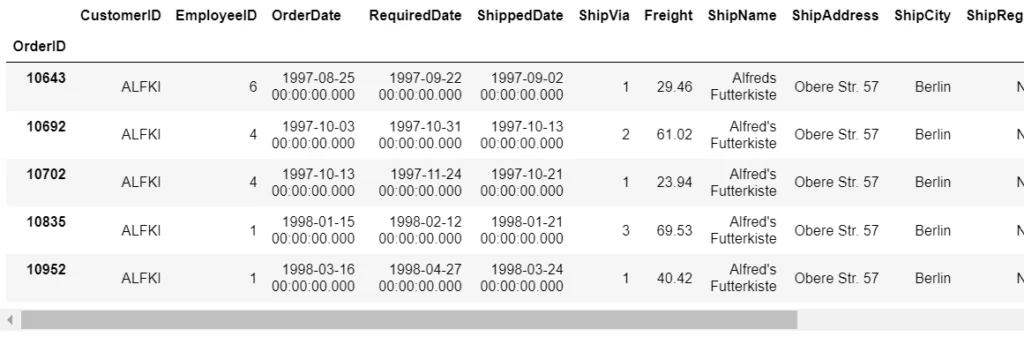
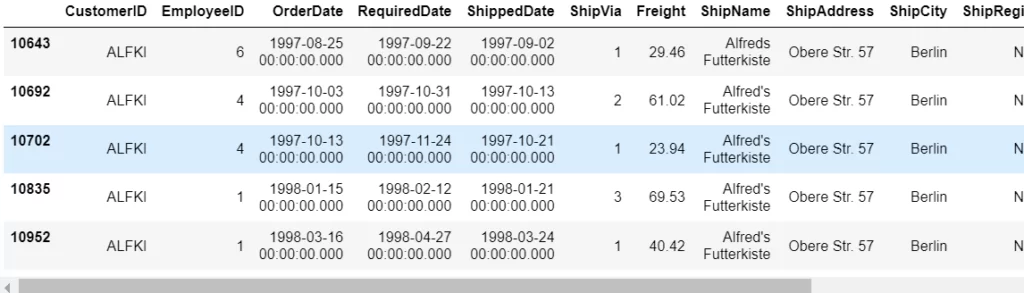
Для сформированного DataFrame преобразовать столбец OrederID в индекс строки.
# используем метод set_index() для столбца 'OrderID'
df = df.set_index('OrderID')
dataTop = df.head(5)
dataTop
Получаем следующий результат:
Теперь установим имя индекса как None:
df.index.names = [None]
dataTop = df.head(5)
dataTop
Вывод:
Получить уникальные значение из столбца в DataFrame.
# уникальные значения столбца 'CustomerID'
df.CustomerID.unique()
Результат:

Теперь получим количество уникальных значений столбца CustomerID.
# количество уникальных значения столбца 'CustomerID'
df.CustomerID.unique()
Out[17]: 89
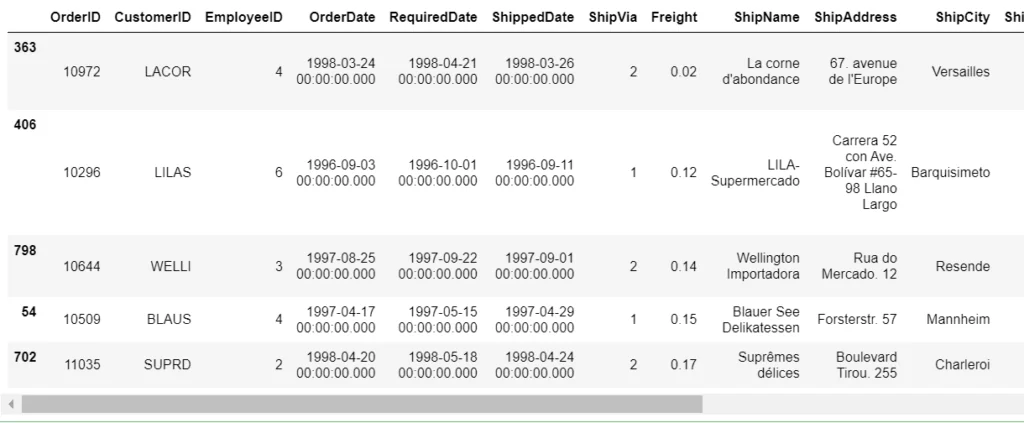
Получить n-наименьших (-наибольших) значений столбца в DataFrame.
import pandas as pd
df = pd.read_csv("c:/Temp/ordersQry.csv", sep =';')
# 5 наименьших значений столбца 'Freight'
df.nsmallest(5, ['Freight'])
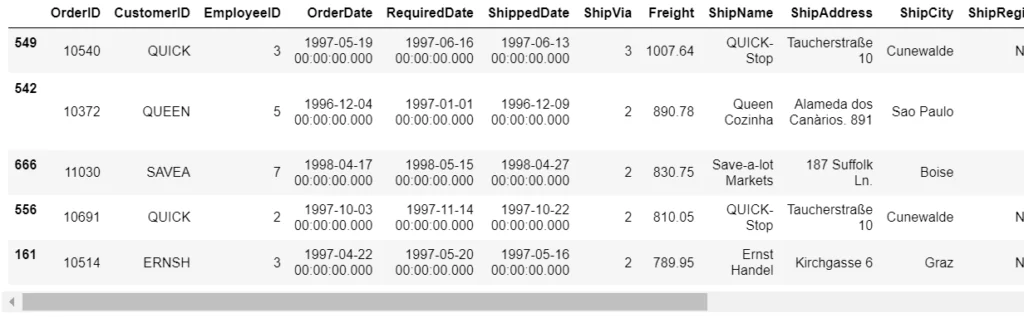
# 5 наибольших значений столбца 'Freight'
df.nlargest(5, ['Freight'])
Получить список (списки) значений столбца (столбцов) в DataFrame.
Такая задача может стоять, когда необходимо, например, получить значения ID всех заказов или же списки значений всех столбцов в наборе данных.
# список значений столбца 'OrderID'
OrderID_list = data['OrderID'].tolist()
print(OrderID_list)
Фрагмент вывода результата:

# списки значений всех столбцов
for i in list(data):
print(data[i].tolist())
Фрагмент вывода данного результата кода:

Разделить данные в столбце DataFrame и получить только определенную их часть.
Сформируем для примера новый DataFrame из csv-файла (ниже фрагмент файла employees_.csv, открытого в Notepad++)

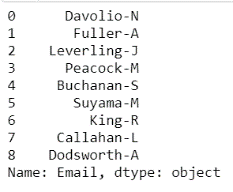
Предположим, что необходимо получить часть данных из столбца, содержащего адрес электронной почты сотрудников компании, который формируется из логина учетной записи до знака @. Результат выведем на экран.
import pandas as pd
df = pd.read_csv("c:/Temp/employees_.csv", sep =';')
print(df.Email.str.split('@').str[0])
Вывод:
И другим способом получим список возвращаемых значений разделяемых данных:
print(df.Email.str.split('@').str[0].tolist())Результат на экране:

Масштабирование чисел столбца.
Давайте теперь посмотрим, как можно применить к столбцу созданного Pandas DataFrame метод масштабирования MinMaxScaler библиотеки Scikit-Learn, который в машинном обучении (ML) является одним из распространенных методов предварительной обработки данных и помогает алгоритмам ML быстрее сходиться за счет того, что функции с такими данными, будут находится в сопоставимом масштабе. Масштабирование сохранит данные в определенном диапазоне.
Сформируем новый Data Frame из файла productsSales_.csv (фрагмент файла, открытого в Notepad++, представлен на рисунке ниже):
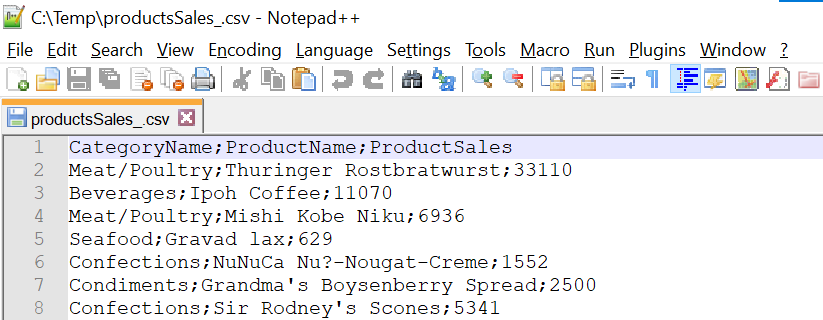
И выполним масштабирование значений столбца ProductSales, применив метод MinMaxScaler, который использует по умолчанию диапазон (0, 1).
# списки значений всех столбцов
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# создаем DataFrame
df = pd.read_csv("c:/Temp/productsSales_.csv", sep =';')
# создаем экземпляр sklearn.preprocessing.MinMaxScaler ()
scaler = MinMaxScaler()
# масштабирование столбца ProductSales
df[['ProductSales']] = scaler.fit_transform(df[['ProductSales']])
print(df)
Вот фрагмент вывода результата:

Если есть необходимость, то можно изменить значение диапазона масштабирования, которое, я напомню, по умолчанию – (0,1). К примеру, установим его таким – (200, 1000). Вот пример кода и фрагмент результат:
# создаем экземпляр sklearn.preprocessing.MinMaxScaler ()
scaler = MinMaxScaler(feature_range=(200, 1000))
# масштабирование столбца ProductSales
df[['ProductSales']] = scaler.fit_transform(df[['ProductSales']])
print(df)

Представленные примеры использования методов библиотек pandas и Scikit-Learn можно успешно применять для исследовательского анализа данных, подготовки их обобщенных характеристик, предварительной обработки.