/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 4 мин.
Ранее я делилась с вами способом классификации изображений из авансовых отчетов с помощью Machine Learning для выделения билетов на проезд в общественном транспорте из общего массива документов (ссылка на статью). В данной статье я расскажу, как можно выявить FRAUD сотрудников, проведя анализ полученных изображений, приложенных к авансовым отчетам документов с помощью Computer Vision.
В нашем случае FRAUDом является прикрепление одного и того же проездного билета к разным авансовым отчетам и, соответственно, необоснованное получение повторной оплаты компенсации за проезд. Задача состоит в том, чтобы найти идентичные изображения среди 6,6 тыс. файлов.
Для начала импортируем необходимые модули.
import cv2
import pdf2image
import os
from tqdm import tqdm
import pandas as pd
Для сравнения изображений используем хэширование с помощью нижеприведенной функции вычисления хэша. Так как в обрабатываемом массиве встречаются файлы в формате pdf, я использовала конвертацию в формат png с помощью библиотеки poppler
#Функция вычисления хэша
class ImageHash():
PATH_TO_POPPLER = 'prog\\poppler-0.68.0\\bin'
@classmethod
def make_hash(self, threshold_image, img_size):
#Рассчитаем хэш
_hash=""
for x in range(img_size):
for y in range(img_size):
val=threshold_image[x,y]
if val==255:
_hash=_hash+"1"
else:
_hash=_hash+"0"
return _hash
@classmethod
def calc_image_hash(self, FileName, img_size=800):
if FileName[-3:].lower() == 'pdf': #Обработчик для pdf файлов
image_pdf = pdf2image.convert_from_path(FileName,
poppler_path=self.PATH_TO_POPPLER,
fmt='png',
dpi=200,
output_folder='temp',
output_file='temp')[0]
image = cv2.imread(image_pdf.filename) #Прочитаем картинку
image_pdf.close()
else:
image = cv2.imread(FileName) #Прочитаем картинку
resized = cv2.resize(image, (img_size, img_size), interpolation = cv2.INTER_AREA) #Изменяем размер
gray_image = cv2.cvtColor(resized, cv2.COLOR_BGR2GRAY) #Переведем в черно-белый формат
avg=gray_image.mean() #Среднее значение пикселя
ret, threshold_image = cv2.threshold(gray_image, avg, 255, 0) #Бинаризация по порогу
return self.make_hash(threshold_image=threshold_image, img_size=img_size)
Далее используем функцию для определения точности совпадения изображений, насколько они похожи.
@classmethod
def compare_hash(self, hash1, hash2):
l=len(hash1)
i=0
count=0
while i<l:
if hash1[i]!=hash2[i]:
count=count+1
i=i+1
return count
Рассмотрим работу кода на примере. Возьмем 4 файла с изображениями билетов.
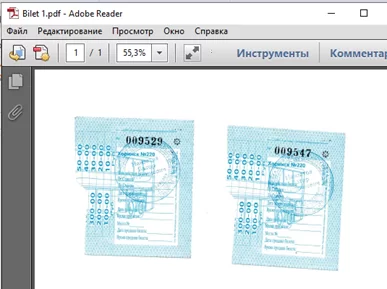
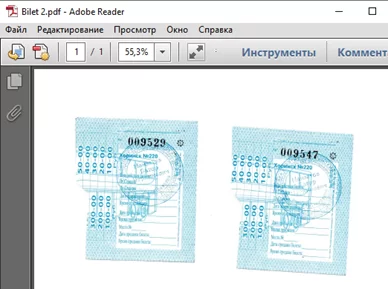
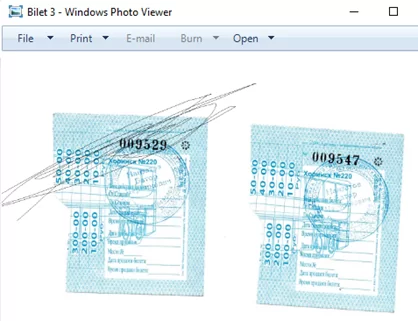

Считываем файлы и рассчитываем хэш для каждого изображения, а также задаем единый размер 800х800 пикселей.
%%time
if __name__ == '__main__':
file_hash = dict()
for file in tqdm(Read_Files.read_files('img2019')):
if file not in list(file_hash.keys()):
try:
file_hash[file] = ImageHash.calc_image_hash(FileName="img2019/" + file, img_size=800)
except:
file_hash[file] = 'error'
Сравниваем полученный хэш каждого изображения и рассчитываем процент совпадения с первым изображением.
hash1 = df['hash'][0]
df['compare_hash'] = ''
for ix in tqdm(df.index):
hash2 = df['hash'][ix]
df['compare_hash'][ix] = 100-100*ImageHash.compare_hash(hash1,hash2)/(800*800)
В данном случае объем обрабатываемых изображений небольшой, поэтому для наглядности нам достаточно сравнить все рассчитанные хэши с хэшем первого изображения («hash1»). Таким образом, мы получаем следующий результат:
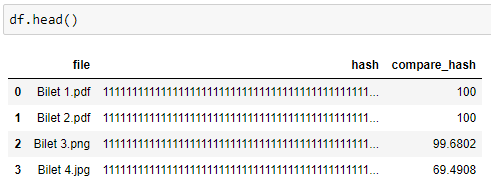
Из полученных данных видно, что хэши файлов «Bilet 1» и «Bilet 2» абсолютно одинаковы – совпадение 100%. Хэш файла «Bilet 3» не совпадает всего на 0,32%, что говорит о том, что изображение совсем немного отличается, что и мы видим визуально на картинке. Хэш файла «Bilet 4» отличается на 30,5%, то есть разница существенна, поэтому мы можем сделать вывод, что изображения не идентичны. Таким образом, с помощью рассчитанных hash можно распознать идентичные изображения.
Применение Machine Learning и Computer Vision позволяет сократить обработку большого количества электронных документов в сжатые сроки. В результате выполнения данного кода, были получены номера авансовых отчетов, к которым в качестве подтверждающих документов, сотрудники приложили идентичные документы.