/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 5 мин.
Задача распознавания сущностей (NER) постоянно возникает при машинной обработке документов, продолжается улучшение показателей качества и скорости работы алгоритмов для решения данной задачи. Предлагаю рассмотреть модель W2NER – классификатор попарных отношений слов в предложении. Далее я обучу модель на русскоязычном датасете и оценю качество её работы. Данные взяты из научной публикации: Unified Named Entity Recognition as Word-Word Relation Classification авторов Jingye Li и др.
Для начала я рассмотрел виды именованных сущностей в разрезе их структуры (не имеем их достоверного перевода и приводим английские названия):
- Flat (Здесь находился мой любимый Макдональдс.)
- Discontinuous (Автор — Исаак Антонович (наверняка Вам известный) Паульсен.)
- Nested (Известнейшая фраза из романа Аркадия и Бориса Стругацких.)
Наиболее популярные подходы, используемые для задачи нахождения именованных сущностей, основаны на sequence-to-sequence архитектуре или нахождении границ (span-based) и имеют свои недостатки, в частности, проблемы при нахождении более сложных по структуре именованных сущностей (discontinuous и nested).
В W2NER используется новый подход, основанный на построении двухмерной матрицы отношений слов между собой в рассматриваемом предложении (рис. 1)
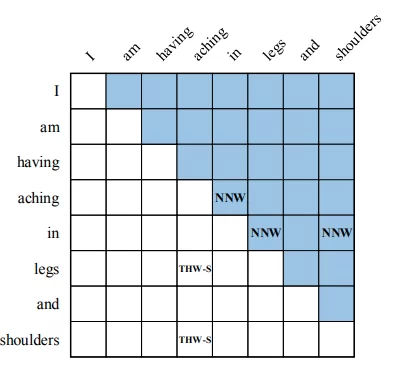
На рисунке 1 заметим, что в некоторых ячейках, соответствующих пересечению строки и столбца, стоит аббревиатура для обозначения отношения между этими словами (NNW, THW-S).
Теперь подробнее об отношениях, предлагаемых в посте:
- NONE: данная пара слов не является частью именованной сущности.
- Next Neighbouring Word (NNW): обозначает что данное слово принадлежит некоторой именованной сущности и слово из соответствующей колонки является в этой именованной сущности следующим. Например: aching → in на Рис.1.
- Tail-Head-Word-* (THW): означает, что данное слово является последним в некоторой именованной сущности и слово в соответствующей колонке- это первый элемент этой именованной сущности данного типа (Location, Person, Organisation и т. д.). Например: Legs → THW-S → aching, здесь S от Symptom.
Модель использует предобученную BERT и двухстороннюю LSTM для получения представления входного предложения в виде тензора. Далее собственная свёрточная сеть преобразует этот тензор в двумерное представление попарных отношений слов в предложении.
Затем происходит классификация полученных результатов и извлечение предсказанных именованных сущностей из матрицы отношений. Доступен репозиторий с кодом модели W2NER и скриптом для её обучения.
Представленная модель была обучена на 14 различных датасетах английского и китайского языка. Я обучил её на русскоязычном датасете nerus, собранном из текстов новостей Lenta.ru, предобработанных моделью Razdel и размеченных Slovnet.
В приведённом датасете выделено три категории именованных сущностей:
LOC — для географических обозначений, PER — имена людей, ORG — названия организаций.
Для обозначения именованных сущностей в датасете используется IOB2 формат, где начало каждого NER объекта отмечается с префикса «B-», последующие элементы «I-» и не входящие в NER элементы отмечены «0» (рис. 2).
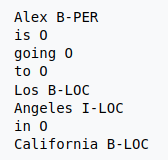
Рис. 2: пример разметки именованных сущностей по стандарту
Nerus содержит более 2 гигабайт размеченных предложений и в целях ограничения времени обучения я не буду использовать все доступные данные, а только случайные 30 000 предложений.
Далее я привел данные в необходимый для обучения JSON-формат:
{‘sentence’: [лист токенов предложения],
‘ner’: [{
‘index’: [индекс именованной сущности],
‘type’: наименование именованной сущности}]}Код доступен по ссылке.
Затем я разбил выбранные предложения с именованными сущностями на тренировочный/валидационный/тестовый сеты в отношении 8/1/1.
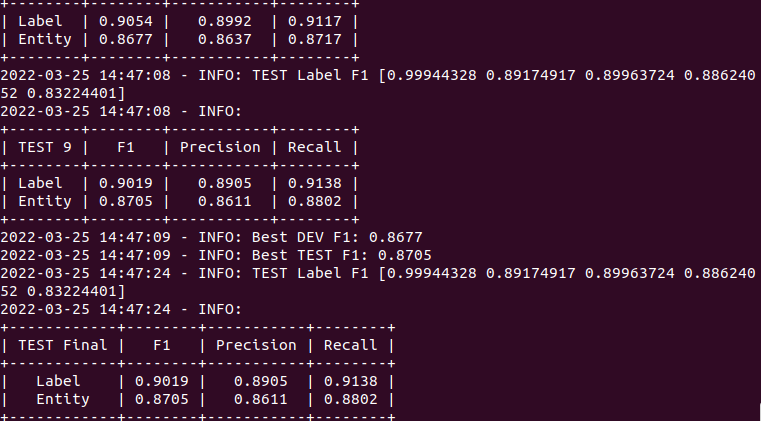
Обучение производил на локальной машине (i7-8700K, 32mb CPU, GTX 1080) и оно заняло около 6 часов. Полученные метрики качества (рис.3, F1: 0.9019, precision: 0.8905, recall: 0.9138) согласуются с результатами на других датасетах и при этом могут быть легко улучшены расширением обучающей выборки. Учитывая скромные технические мощности и небольшой размер тренировочных данных, на мой взгляд, это очень хороший результат.
После обучения модель была сохранена в файл model.pt в папке проекта.
Затем я рассмотрел входное предложение: Жители Брянска устроили давку из-за дешевых продуктов на открытии магазина, сообщает интернет-газета «Брянские новости».
Данное предложение содержит 18 токенов (включая кавычки и точку) и две именованных сущности: Брянска (LOC, позиция 1) и Брянские новости (ORG, позиции 14, 15). Модель была занружена и получены следующие результаты для этого предложения:
import torch as pt
model = pt.load('Документы/W2NER-main/model.pt')
# загрузим предложение в json-формате
with open("test.json", 'r', encoding='utf-8') as f:
test_data = json.load(f)
# проведём токенизацию и разметку предложения
test_loader = data_loader.RelationDataset(*data_loader.process_bert
([test_data[0]], tokenizer, vocab))
# первод модели в режим инференса (без изменения собственных весов)
model.eval()
with torch.no_grad():
for i, data_batch in enumerate(test_loader):
entity_text = data_batch[-1]
length = data_batch[-2]
data_batch = [data.cuda() for data in data_batch[:-1]]
# отправляем токенизированное предложение в модель
outputs = model(*data_batch)
outputs = torch.argmax(outputs, -1)
# получим разметку токенов предложения
result = decode(outputs.cpu().numpy(), entity_text, length.cpu().numpy())
Вывод модели будет выглядеть так: {‘1-#-2′, ’14-15-#-3’}. Здесь первые числа перед решеткой — это позиции именованной сущности, а число после — его код.
Далее я посмотрел на словарь кодов именованных сущностей:
>> vocab.id2label
{0: '<pad>', 1: '<suc>', 2: 'loc', 3: 'org', 4: 'per'}
Соответственно токен 1 – это географический объект, а токены 14 и 15 — название организации.
Рассмотренная модель может быть легко дообучена на сравнительно небольшом корпусе текстов для различных задач не только нахождения имён людей и организаций, но также, например, в научных текстах по химии для нахождения названий соединений или в биологии для поиска упоминаний различных белков.
Каждый день публикуется несколько новых научных статей в области машинного обучения, многие с уже готовой реализацией в коде. Не забывайте знакомиться с публикациями и сможете найти как множество инструментов, так и просто свежих идей и подходов для решения своих задач. Одним из замечательных сайтов для слежения за научными публикациями со всего мира могу порекомендовать https://paperswithcode.com/.
Спасибо за внимание.