/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 2 мин.
Во время очередного DataScienceChallenge появился задача, которую можно описать так: необходимо реализовать алгоритм Process Mining, известный как Heuristic Miner. Так как это соревнование, значит, нужно чтобы алгоритм отработал как можно быстрее. Но как заставить алгоритм отработать “пятилетку за четыре года”? В DS-коммьюнити самым популярным языком является Python, однако по ряду причин, как то динамическая типизация, он имеет проблемы с оптимизацией скорости выполнения. И тут в голову пришла мыслишка: а что если… использовать более “скоростной” язык?

Так как по условиям соревнования от нас требовался исполняемый код на Python, было принято “соломоново” решение: запускать написанное на C# приложение напрямую из “питоновского” скрипта.
В итоге задача свелась к следующему:
- Работа через консоль
- Задание параметров для майнера
- C#
- Прогон алгоритма
- Вывод результатов в консоль
- Python
- Запуск C# кода и передача параметров для майнера
- Изменение прав на исполнение файла
- Перехват вывода из консоли
- Форматирование
Ну что же, вот и настало время интеграции C# и Python.

Итак, вывод в консоль результата С#-приложения:
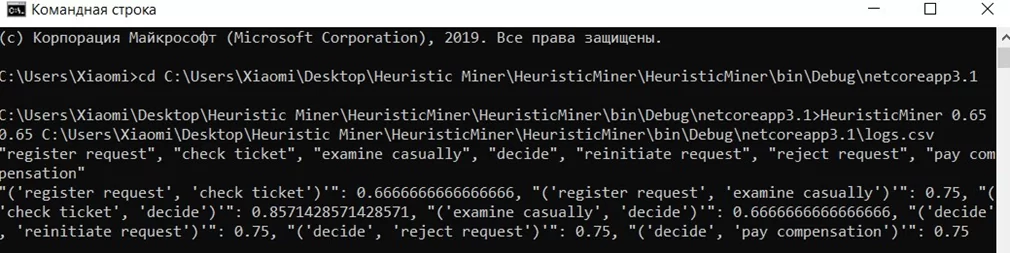
Задача усложняется тем, что код будет выполняться через Docker-контейнеры на Linux. В связи с этим пришлось перекомплировать проект под Linux-x64, выдать себе права на выполнение C#-приложения, и провести форматирование полученного результата, который в силу особенностей операционной системы будет отличаться для Linux.
Исполняемый код на Python:
from subprocess import run
import json
import os
def apply_hue_miner(log_df, dependency_thresh=0.65, and_measure_thresh=0.65, dfg_pre_cleaning_noise_thresh=0.05):
cur_dir = os.getcwd()
log_dir = cur_dir+'/input/logs.csv' os.system('chmod +x ' + cur_dir + '/program/HeuristicMiner’)
output = run([cur_dir+'/program/HeuristicMiner', str(dependency_thresh),
str(and_measure_thresh),
str(dfg_pre_cleaning_noise_thresh),
log_dir], capture_output=True).stdout
output = output.decode("utf-8") print(output.split('\n')[0])
nodes = eval('['+output.split('\n')[0]+']’)
edges_t = '{'+output.split('\n')[1].replace(")'", ")").replace("'(", "(") + '}'
edges = json.loads(edges_t)
edges = {eval(k): float(v) for k, v in edges.items()}
return {'nodes': nodes, 'edges': edges}
По итогу оказалось, что код на C# отработал в 2 раза быстрее, чем аналогичная реализация алгоритма на Python. Так что, вполне возможно, вставки в ваш код, написанные на C#, смогут значительно ускорить реализуемые Вами алгоритмы.