/img/star (2).png.webp)





/img/news (2).png.webp)
/img/event.png.webp)

Время прочтения: 3 мин.
Как мы очищаем изображения из файла PDF, сохраняя их качество?
Есть несколько способов извлечь изображения из файла PDF. Самый простой способ – просто сделать снимок экрана с изображением, присутствующим на любой странице PDF-файла, и обрезать изображение в соответствии с вашими требованиями. Этот способ выглядит очень простым, но что, если в файл PDF содержит 100 или 1000 изображений, и вы хотите, чтобы все они были в отдельной папке. Тогда этот подход будет утомительным и трудоемким и нам нужно автоматизировать этот процесс, а язык программирования Python сделает это за вас.
Если вы думаете, что можете использовать любой онлайн-инструмент, то вы ставите под угрозу безопасность своих данных. Почему вам нужно полагаться на любую онлайн-платформу, если вы можете выполнить ту же задачу, запустив простой скрипт Python на своем компьютере?
Установка необходимых библиотек
В этой статье мы будем использовать библиотеку Python PyMuPDF (также известную как «fitz»), которая представляет собой легкую программу просмотра PDF и XPS. Эта библиотека может получить доступ к файлам в форматах PDF, XPS, комиксов и художественных книг, и она известна своей высочайшей производительностью и высоким качеством рендеринга.
Вы можете установить этот пакет с помощью следующей команды в терминале (пользователи Linux) или командной строке (пользователи Windows).
$pip3 install PyMuPDFНаписание скрипта Python для извлечения всех изображений в файл pdf
Мы напишем скрипт для очистки изображений из файла PDF. Итак, приступим, для этого нам понадобится интерпретатор Python и idle.
#импорт необходимых библиотек
import fitz
#открытия файла
file_path = input("Введите путь к PDF файлу")
pdf_file = fitz.open(file_path)
# Чтение места, где сохранить файл
location = input("Enter the location to save: ")
#поиск количества страниц в pdf
number_of_pages = len(pdf_file)
#итерация по каждой странице в pdf
for current_page_index in range(number_of_pages):
# итерация по каждому изображению на каждой странице PDF
for img_index,img in enumerate(pdf_file.getPageImageList(current_page_index)):
xref = img[0]
image = fitz.Pixmap(pdf_file, xref)
# если это чёрно-белое или цветное изображение
if image.n < 5:
image.writePNG("{}/image{}-{}.png".format(location,current_page_index, img_index))
#если это CMYK: конвертируем в RGB
else:
new_image = fitz.Pixmap(fitz.csRGB, image)
new_image.writePNG("{}/image{}-{}.png".foramt(location,current_page_index, img_index))
Примечание:
Пользователю необходимо ввести путь к файлу pdf: укажите абсолютный путь, по которому находится файл pdf. Пользователь должен указать, где изображения должны быть сохранены.
После того, как мы запустим скрипт, используя образец PDF, который содержит изображения внутри текста мы можем получить все изображения с этого документа.
Давайте запустим этот скрипт, используя образец PDF представленный ниже:
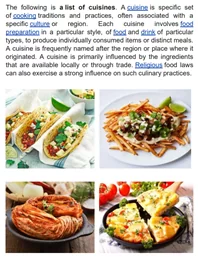
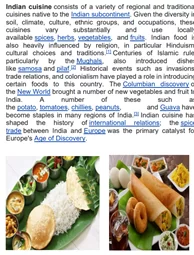
Образец PDF с изображениями.
Когда мы запускаем скрипт Python для этого PDF-файла, мы получим все 6 изображений из PDF-файла в пользовательскую папку.

После ввода вышеуказанных данных все изображения будут извлечены из PDF в указанное пользователем место, как показано ниже.
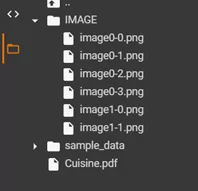
Такой метод извлечения изображений является эффективным, если нам необходимо обработать большой объем данных формата PDF.